Projet :Analyse et visualisation des données de Spotify
Réalisation: Harald Valcourt
Présentation du projet
Le responsable d'une jeune station de radio veut mieux comprendre les tendances musicales de ces derniers mois pour ajuster la diffusion musicale de sa radio. La Direction du Marketing de la radio transmet à un data analyste le lien vers données de streaming (écoutes en ligne) de la plateforme de services multimédias Spotify et lui demande:
- D'analyser le jeu de données;
- De tirer des renseignements intéressants pouvant orienter le responsable sur le choix des musiques à diffuser sur la radio.
Le projet est divisé principalement en deux parties:
- L'analyse des données
- La visualisation des données
Outils technologiques
Les outils technologiques suivants sont utilisés pour l'implémentation du projet:
- Le langage Python
- Le logiciel MS Power BI Desktop
- La plateforme MS Power BI Service
Méthodologie
Pour atteindre l'objectif fixé, les étapes suivantes seront réalisées:
- Le jeu de données
- La collecte des données
- La compréhension des données
- La préparation des données
- L'analyse des données
- Statistique univariée
- Statistique bivariée
- La visualisation des données
- La définition des KPIs
- La définition des rapports
- La réalisation du tableau de bord
- La réalisation de l'application
Première partie :Analyse des données
1- Jeu de données
Les données proviennent de Kaggel.com et sont constituées d'une compilation (semaine après semaine) des chansons les plus écoutées (Top 200 Charts) sur une période d'une année soit de 2020 à 2021(https://www.kaggle.com/datasets/dhruvildave/spotify-charts?select=charts.csv).
2- Collecte des données
importation des librairies et lecture du fichier
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandasql as ps
from warnings import filterwarnings
Parametrage de base
sns.set_context("paper", font_scale=0.8)
colors = ['#66CD00','#458B00','#66CDAA','#CAFF70','#7FFF00','#FFD700','#00CED1']
pd.options.display.float_format = "{:,.2f}".format
filterwarnings('ignore')
Lecture du fichier csv
df=pd.read_csv('spotify_dataset.csv')
Affichage des colonnes
df.columns
Index(['Index', 'Position', 'NumberCharted', 'HighestCharting', 'SongName',
'Streams', 'Artist', 'Followers', 'SongID', 'Genre', 'Date',
'WeeksCharted', 'Popularity', 'Danceability', 'Energy', 'Loudness',
'Speechiness', 'Acousticness', 'Liveness', 'Tempo', 'Duration (ms)',
'Valence', 'Chord'],
dtype='object')
Affichage des certaines données
df[['Index', 'Position', 'NumberCharted', 'HighestCharting', 'SongName','Streams', 'Artist', 'Followers', 'SongID']].head(3)
| Index | Position | NumberCharted | HighestCharting | SongName | Streams | Artist | Followers | SongID | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 8 | 2021-07-23--2021-07-30 | Beggin' | 48,633,449 | Måneskin | 3377762 | 3Wrjm47oTz2sjIgck11l5e |
| 1 | 2 | 2 | 3 | 2021-07-23--2021-07-30 | STAY (with Justin Bieber) | 47,248,719 | The Kid LAROI | 2230022 | 5HCyWlXZPP0y6Gqq8TgA20 |
| 2 | 3 | 1 | 11 | 2021-06-25--2021-07-02 | good 4 u | 40,162,559 | Olivia Rodrigo | 6266514 | 4ZtFanR9U6ndgddUvNcjcG |
3- Compréhension des données
Compréhension du contenu de chaque colonne
- Highest Charting Position: Position la plus élevée de la chanson dans le Top 200 Weekly Global Charts de Spotify entre 2000 et 2019.
- Number of Times Charted: Le nombre de fois où la chanson a figuré dans le Top 200 hebdomadaire mondial de Spotify entre 2000 et 2019.
- Week of Highest Charting: La semaine où la chanson a eu la position la plus élevée dans le Spotify Top 200 Weekly Global Charts entre 2000 et 2019.
- Song Name: Nom de la chanson qui a figuré dans le Top 200 du classement mondial hebdomadaire de Spotify entre 2000 et 2019.
- Streams:Le nombre approximatif de streams de la chanson.
- Artist: L'artiste/les artistes principaux impliqués dans la création de la chanson.
- Artist Followers: Le nombre de followers de l'artiste principal sur Spotify.
- Song ID: Numéro de la chanson
- Genre: Les genres auxquels la chanson appartient.
- Date: La date initiale de sortie de la chanson
- Weeks Charted: Weekend de classement
- Popularity: La popularité du titre. La valeur sera comprise entre 0 et 100, 100 étant la valeur la plus populaire.
- Danceability: La Danceability décrit dans quelle mesure un titre est adapté à la danse en se basant sur une combinaison d'éléments musicaux, notamment le tempo, la stabilité du rythme, la force du battement et la régularité générale. Une valeur de 0,0 est la moins dansante et 1,0 est la plus dansante.
- Energy: L'énergie est une mesure de 0,0 à 1,0 et représente une mesure perceptive de l'intensité et de l'activité. En général, les pistes énergiques sont rapides, fortes et bruyantes.
- Loudness: Représente le volume global d'une piste en décibels (dB) et c'est la qualité d'un son qui est le principal corrélat psychologique de la force physique (amplitude)
- Speechiness: La qualité vocale détecte la présence de mots parlés dans une piste. Plus l'enregistrement est exclusivement vocal (par exemple, talk-show, livre audio, poésie), plus la valeur de l'attribut est proche de 1,0.
- Acousticness: Une mesure de 0,0 à 1,0 indiquant si le morceau est acoustique.
- Liveness: Détecte la présence d'un public dans l'enregistrement. Des valeurs plus élevées représentent une probabilité accrue que la piste ait été jouée en direct.
- Tempo: Tempo en battements par minute (BPM). Dans la terminologie musicale, le tempo est la vitesse ou le rythme d'un morceau donné et dérive directement de la durée moyenne du battement.
- Duration (ms): Durée de la chanson millisecondes.
- Valence: Une mesure de 0,0 à 1,0 qui décrit le côté positif véhiculé par le morceau. Les morceaux avec une valence plus élevée peuvent déclencher des émotions positives, comme le bonheur, la gaieté et l'euphorie, tandis que les morceaux avec une valence plus faible peuvent déclencher des émotions négatives, comme la tristesse, la dépression et la colère.
- Chord: Accord représente un ensemble de notes considéré comme formant un tout du point de vue de l'harmonie.
Affichage des informations du DataFrame
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 1556 entries, 0 to 1555 Data columns (total 23 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Index 1556 non-null int64 1 Position 1556 non-null int64 2 NumberCharted 1556 non-null int64 3 HighestCharting 1556 non-null object 4 SongName 1556 non-null object 5 Streams 1556 non-null object 6 Artist 1556 non-null object 7 Followers 1556 non-null object 8 SongID 1556 non-null object 9 Genre 1556 non-null object 10 Date 1556 non-null object 11 WeeksCharted 1556 non-null object 12 Popularity 1556 non-null object 13 Danceability 1556 non-null object 14 Energy 1556 non-null object 15 Loudness 1556 non-null object 16 Speechiness 1556 non-null object 17 Acousticness 1556 non-null object 18 Liveness 1556 non-null object 19 Tempo 1556 non-null object 20 Duration (ms) 1556 non-null object 21 Valence 1556 non-null object 22 Chord 1556 non-null object dtypes: int64(3), object(20) memory usage: 279.7+ KB
Affichage de la dimension du DataFrame
df.shape
(1556, 23)
4- Préparation des données
Renommage de certaines colonnes
df.rename(mapper= {'Highest Charting Position': 'Position',
'Number of Times Charted':'Frequency',
'Week of Highest Charting': 'Week',
'Song Name': 'Song',
'Artist Followers':'Followers',
'Song ID': 'SongID',
'Duration (ms)': 'Duration',
'HighestCharting': 'WeekCharting'},
axis=1, inplace=True)
Affichage de la période sur laquelle a été fait l'extraction
semaine_charts=df['WeekCharting'] annees_charts=df['WeekCharting'].str[:4].unique() annees_charts
Affichage du nombre de classements par semaine
classement_par_semaine=df['Position'].value_counts()
groupe = df.groupby('WeekCharting')['Position'].count()
groupe
WeekCharting
2019-12-27--2020-01-03 89
2020-01-03--2020-01-10 51
2020-01-10--2020-01-17 22
2020-01-17--2020-01-24 39
2020-01-24--2020-01-31 18
..
2021-06-25--2021-07-02 24
2021-07-02--2021-07-09 23
2021-07-09--2021-07-16 12
2021-07-16--2021-07-23 15
2021-07-23--2021-07-30 46
Name: Position, Length: 83, dtype: int64
Séparation de la colonne 'WeekCharting' en deux colonnes distinctes 'StartWeek' et 'EndWeek'
def start_week(date):
if pd.notnull(date):
split_date = str(date).split('--')
return split_date[0]
else:
return np.nan
def end_week(date):
if pd.notnull(date):
split_date = str(date).split('--')
return split_date[1]
else:
return np.nan
df['StartWeek'] = df['WeekCharting'].apply(start_week)
df['EndWeek'] = df['WeekCharting'].apply(end_week)
var=df[['WeekCharting','StartWeek','EndWeek']]
var.head(3)
| WeekCharting | StartWeek | EndWeek | |
|---|---|---|---|
| 0 | 2021-07-23--2021-07-30 | 2021-07-23 | 2021-07-30 |
| 1 | 2021-07-23--2021-07-30 | 2021-07-23 | 2021-07-30 |
| 2 | 2021-06-25--2021-07-02 | 2021-06-25 | 2021-07-02 |
Traitement de la colonne genre
genre=df['Genre']
genre.sample(10)
855 ['atl hip hop', 'hip hop', 'rap', 'trap'] 527 ['canadian pop', 'pop', 'post-teen pop'] 1361 ['german hip hop'] 1141 ['german drill', 'german hip hop'] 302 ['atl hip hop', 'pop rap', 'rap', 'trap'] 1001 ['viral rap'] 1025 ['dance pop', 'pop'] 771 ['dance pop', 'pop', 'post-teen pop'] 1410 ['australian psych', 'neo-psychedelic'] 393 ['ohio hip hop', 'pop rap'] Name: Genre, dtype: object
Fonction de catégorisation du genre des chansons
def category(genre):
if 'pop' in genre :
return 'Pop'
elif 'latin' in genre:
return 'Latin'
elif 'rock' in genre:
return 'Rock'
elif 'hip hop' in genre:
return 'Hip hop'
elif 'rap' in genre:
return 'Rap'
elif 'funk' in genre:
return 'Funk'
elif 'drill' in genre:
return 'Rap'
else:
return 'Other'
df['Category'] = df['Genre'].map(category)
df[ ["SongID","Genre","StartWeek","EndWeek","Category"]].head(3)
| SongID | Genre | StartWeek | EndWeek | Category | |
|---|---|---|---|---|---|
| 0 | 3Wrjm47oTz2sjIgck11l5e | ['indie rock italiano', 'italian pop'] | 2021-07-23 | 2021-07-30 | Pop |
| 1 | 5HCyWlXZPP0y6Gqq8TgA20 | ['australian hip hop'] | 2021-07-23 | 2021-07-30 | Hip hop |
| 2 | 4ZtFanR9U6ndgddUvNcjcG | ['pop'] | 2021-06-25 | 2021-07-02 | Pop |
Affichage du nombre de chansons par categories
Nombre_chansons=df.groupby('Category')['SongID'].count()
Nombre_chansons
Category Funk 12 Hip hop 199 Latin 138 Other 156 Pop 819 Rap 201 Rock 31 Name: SongID, dtype: int64
Affichage des genres relatifs à la categorie "Other"
other=df[df['Category']=='Other']['Genre']
print(other)
35
49 []
51 []
55 ['dreamo', 'indie surf', 'surf punk', 'vegas i...
56 []
...
1455 []
1480 []
1517 []
1538
1552 ['sertanejo', 'sertanejo universitario']
Name: Genre, Length: 156, dtype: object
Identification de lignes pour lesquelles 'SongID' est vide
id_vide=df[df['SongID']==' ']
id_vide[['Index','Position','SongName','Streams','Artist','SongID']]
| Index | Position | SongName | Streams | Artist | SongID | |
|---|---|---|---|---|---|---|
| 35 | 36 | 36 | NOT SOBER (feat. Polo G & Stunna Gambino) | 11,869,336 | The Kid LAROI | |
| 163 | 164 | 5 | 34+35 | 5,453,159 | Ariana Grande | |
| 464 | 465 | 118 | Richer (feat. Polo G) | 6,292,362 | Rod Wave | |
| 530 | 531 | 20 | 34+35 Remix (feat. Doja Cat, Megan Thee Stalli... | 6,162,453 | Ariana Grande | |
| 636 | 637 | 22 | Driving Home for Christmas - 2019 Remaster | 8,804,531 | Chris Rea | |
| 654 | 655 | 73 | Thank God It's Christmas - Non-Album Single | 10,509,961 | Queen | |
| 750 | 751 | 19 | Agua (with J Balvin) - Music From "Sponge On T... | 5,358,940 | Tainy | |
| 784 | 785 | 76 | Lean (feat. Towy, Osquel, Beltito & Sammy & Fa... | 4,739,241 | Super Yei, Jone Quest | |
| 876 | 877 | 164 | #NAME? | 4,964,708 | Dalex | |
| 1140 | 1141 | 131 | In meinem Benz | 5,494,500 | AK AUSSERKONTROLLE, Bonez MC | |
| 1538 | 1539 | 176 | fuck, i'm lonely (with Anne-Marie) - from “13 ... | 4,856,458 | Lauv |
Suppression des lignes avec SongID vide
df = df.drop(df[df['SongID']==' '].index)
Modification de certains types de donnees
df['Loudness'] = pd.to_numeric(df['Loudness'])
df['Followers'] = pd.to_numeric(df['Followers'])
df['Popularity'] = pd.to_numeric(df['Popularity'])
df['Danceability'] = pd.to_numeric(df['Danceability'])
df['Energy'] = pd.to_numeric(df['Energy'])
df['Speechiness'] = pd.to_numeric(df['Speechiness'])
df['Acousticness'] = pd.to_numeric(df['Acousticness'])
df['Tempo'] = pd.to_numeric(df['Tempo'])
df['Duration'] = pd.to_numeric(df['Duration'])
df['Valence'] = pd.to_numeric(df['Valence'])
Traitement de la colonne "Streams"
df['Streams'].head()
0 48,633,449 1 47,248,719 2 40,162,559 3 37,799,456 4 33,948,454 Name: Streams, dtype: object
streams=df.iloc[:, 5]
df.iloc[:, 5] = df.iloc[:, 5].replace(',', '', regex=True)
df['Streams'] = pd.to_numeric(df['Streams'])
df['Streams'].head()
0 48633449 1 47248719 2 40162559 3 37799456 4 33948454 Name: Streams, dtype: int64
Traitement de la colonne "Artist"
artistes=df['Artist']
print(artistes)
0 Måneskin
1 The Kid LAROI
2 Olivia Rodrigo
3 Ed Sheeran
4 Lil Nas X
...
1551 Dua Lipa
1552 Jorge & Mateus
1553 Camila Cabello
1554 Dadá Boladão, Tati Zaqui, OIK
1555 Taylor Swift
Name: Artist, Length: 1545, dtype: object
Création d'une colonne "Artiste" renseignée du premier nom de la liste pour chaque chanson
def split_artist(artist):
if pd.notnull(artist):
split_artist = str(artist).split(',')
return split_artist[0]
else:
return np.nan
df['Artiste'] = df['Artist'].apply(split_artist)
df[["StartWeek","EndWeek","Category","Artiste"]]
| StartWeek | EndWeek | Category | Artiste | |
|---|---|---|---|---|
| 0 | 2021-07-23 | 2021-07-30 | Pop | Måneskin |
| 1 | 2021-07-23 | 2021-07-30 | Hip hop | The Kid LAROI |
| 2 | 2021-06-25 | 2021-07-02 | Pop | Olivia Rodrigo |
| 3 | 2021-07-02 | 2021-07-09 | Pop | Ed Sheeran |
| 4 | 2021-07-23 | 2021-07-30 | Pop | Lil Nas X |
| ... | ... | ... | ... | ... |
| 1551 | 2019-12-27 | 2020-01-03 | Pop | Dua Lipa |
| 1552 | 2019-12-27 | 2020-01-03 | Other | Jorge & Mateus |
| 1553 | 2019-12-27 | 2020-01-03 | Pop | Camila Cabello |
| 1554 | 2019-12-27 | 2020-01-03 | Funk | Dadá Boladão |
| 1555 | 2019-12-27 | 2020-01-03 | Pop | Taylor Swift |
1545 rows × 4 columns
Création d'une nouvelle colonne "NiveauEcoute" pour catégoriser les genres en fonction de leurs volumes d'écoutes
def ecoute(row):
if row["Streams"] >30000000 :
return "Forte"
if row["Streams"] >20000000 :
return "Moyenne"
if row["Streams"] >10000000 :
return "Faible"
else:
return "Très Faible"
df = df.assign(NiveauEcoute=df.apply(ecoute, axis=1))
df['NiveauEcoute']
0 Forte
1 Forte
2 Forte
3 Forte
4 Forte
...
1551 Très Faible
1552 Très Faible
1553 Très Faible
1554 Très Faible
1555 Très Faible
Name: NiveauEcoute, Length: 1545, dtype: object
Création d'une nouvelle colonne "NiveauPopulaire" pour catégoriser les chansons en fonction de leurs popularites
def popularite(row):
if row["Popularity"] >60 :
return "Forte"
else:
return "Faible"
df = df.assign(NiveauPopularite=df.apply(popularite, axis=1))
df['NiveauPopularite']
0 Forte
1 Forte
2 Forte
3 Forte
4 Forte
...
1551 Forte
1552 Forte
1553 Forte
1554 Faible
1555 Forte
Name: NiveauPopularite, Length: 1545, dtype: object
Création d'une nouvelle colonne "NiveauEnergie" pour catégoriser l'energie d'une chanson
def energie(row):
if row["Energy"] >0.7 :
return "Forte"
if row["Energy"] >0.5 :
return "Moyenne"
else:
return "Faible"
df = df.assign(NiveauEnergie=df.apply(energie, axis=1))
df['NiveauEnergie']
0 Forte
1 Forte
2 Moyenne
3 Forte
4 Forte
...
1551 Moyenne
1552 Forte
1553 Moyenne
1554 Moyenne
1555 Moyenne
Name: NiveauEnergie, Length: 1545, dtype: object
Création des colonnes pour stocker l'année,le mois,le jour de sortie de la chanson
df['Date'] = pd.to_datetime(df['Date'],format='mixed')
df['AnneeSortie']=pd.to_datetime(df['Date'],format='mixed').dt.year
df['MoisSortie']=pd.to_datetime(df['Date'],format='mixed').dt.month
df['WeekSortie']=pd.to_datetime(df['Date'],format='mixed').dt.isocalendar().week
df['NomMoisSortie']=pd.to_datetime(df['Date'],format='mixed').dt.month_name()
df['JourSortie']=pd.to_datetime(df['Date'],format='mixed').dt.day
df['NomJourSortie']=pd.to_datetime(df['Date'],format='mixed').dt.day_name()
df['Date'] = df['Date'].dt.strftime('%Y-%m-%d')
df['StartWeek'] = pd.to_datetime(df['StartWeek'],format='mixed')
df['StartWeek'] = df['StartWeek'].dt.strftime('%Y-%m-%d')
var=df[['WeekCharting','StartWeek','EndWeek','AnneeSortie','MoisSortie','NomMoisSortie','NomJourSortie']]
var.head()
| WeekCharting | StartWeek | EndWeek | AnneeSortie | MoisSortie | NomMoisSortie | NomJourSortie | |
|---|---|---|---|---|---|---|---|
| 0 | 2021-07-23--2021-07-30 | 2021-07-23 | 2021-07-30 | 2017 | 12 | December | Friday |
| 1 | 2021-07-23--2021-07-30 | 2021-07-23 | 2021-07-30 | 2021 | 7 | July | Friday |
| 2 | 2021-06-25--2021-07-02 | 2021-06-25 | 2021-07-02 | 2021 | 5 | May | Friday |
| 3 | 2021-07-02--2021-07-09 | 2021-07-02 | 2021-07-09 | 2021 | 6 | June | Friday |
| 4 | 2021-07-23--2021-07-30 | 2021-07-23 | 2021-07-30 | 2021 | 7 | July | Friday |
Ajout de la colonne "Age"
df['Date']= pd.to_datetime(df['Date'],format='mixed')
df['StartWeek'] = pd.to_datetime(df['StartWeek'],format='mixed')
df['Age']=(df['StartWeek']- df['Date']).dt.days
df['Date'] = df['Date'].dt.strftime('%Y-%m-%d')
df['StartWeek'] = df['StartWeek'].dt.strftime('%Y-%m-%d')
df.columns
Index(['Index', 'Position', 'NumberCharted', 'WeekCharting', 'SongName',
'Streams', 'Artist', 'Followers', 'SongID', 'Genre', 'Date',
'WeeksCharted', 'Popularity', 'Danceability', 'Energy', 'Loudness',
'Speechiness', 'Acousticness', 'Liveness', 'Tempo', 'Duration',
'Valence', 'Chord', 'StartWeek', 'EndWeek', 'Category', 'Artiste',
'NiveauEcoute', 'NiveauPopularite', 'NiveauEnergie', 'AnneeSortie',
'MoisSortie', 'WeekSortie', 'NomMoisSortie', 'JourSortie',
'NomJourSortie', 'Age'],
dtype='object')
Verification des valeurs négatives de la colonne "Age"
age_negatif=df[df['Age']<0][['WeekCharting','Date','StartWeek','Age']]
age_negatif
| WeekCharting | Date | StartWeek | Age | |
|---|---|---|---|---|
| 14 | 2021-05-21--2021-05-28 | 2021-06-04 | 2021-05-21 | -14 |
| 22 | 2021-03-12--2021-03-19 | 2021-05-21 | 2021-03-12 | -70 |
| 46 | 2020-10-16--2020-10-23 | 2021-03-26 | 2020-10-16 | -161 |
| 52 | 2021-07-09--2021-07-16 | 2021-07-30 | 2021-07-09 | -21 |
| 53 | 2021-06-18--2021-06-25 | 2021-06-25 | 2021-06-18 | -7 |
| ... | ... | ... | ... | ... |
| 1460 | 2020-01-03--2020-01-10 | 2020-01-17 | 2020-01-03 | -14 |
| 1476 | 2020-01-24--2020-01-31 | 2020-02-13 | 2020-01-24 | -20 |
| 1480 | 2020-01-10--2020-01-17 | 2021-08-13 | 2020-01-10 | -581 |
| 1481 | 2020-01-24--2020-01-31 | 2020-08-28 | 2020-01-24 | -217 |
| 1506 | 2020-01-17--2020-01-24 | 2020-04-24 | 2020-01-17 | -98 |
188 rows × 4 columns
Verification des valeurs nulles de la colonne "Age"
age_zero=df[df['Age']==0][['StartWeek','Date','Age']]
age_zero
| StartWeek | Date | Age | |
|---|---|---|---|
| 4 | 2021-07-23 | 2021-07-23 | 0 |
| 12 | 2021-07-09 | 2021-07-09 | 0 |
| 15 | 2021-05-21 | 2021-05-21 | 0 |
| 16 | 2021-05-21 | 2021-05-21 | 0 |
| 17 | 2021-04-23 | 2021-04-23 | 0 |
| ... | ... | ... | ... |
| 1533 | 2019-12-27 | 2019-12-27 | 0 |
| 1534 | 2019-12-27 | 2019-12-27 | 0 |
| 1535 | 2019-12-27 | 2019-12-27 | 0 |
| 1544 | 2019-12-27 | 2019-12-27 | 0 |
| 1546 | 2019-12-27 | 2019-12-27 | 0 |
570 rows × 3 columns
Renseignements
- 188 lignes présentent une date de sortie postérieure à la date de classement.
- Pour ces lignes la date de classement sera fixée à celle de sortie
- 570 lignes ont la date de classement identique à de sortie
Creation d'un nouveau DataFrame:spotify et Suppression des colonnes inutiles
spotify = df[[
'Index', 'Position', 'NumberCharted','SongName',
'Streams', 'Followers', 'Date',
'Popularity', 'Danceability', 'Energy', 'Loudness',
'Speechiness', 'Acousticness', 'Liveness', 'Tempo', 'Duration',
'Valence','StartWeek', 'EndWeek', 'Category', 'Artiste',
'NiveauPopularite', 'NiveauEcoute', 'NiveauEnergie', 'AnneeSortie',
'MoisSortie', 'JourSortie', 'NomJourSortie', 'NomMoisSortie',
'WeekSortie', 'Age'
]]
Renommage des colonnnes du DataFrame spotify
spotify.rename(mapper= {
'Index':'Index',
'Position': 'Place',
'NumberCharted': 'Frequence',
'SongName': 'Chanson',
'Streams' :'Ecoute',
'Followers': 'Disciple',
'Date' :'DateSortie',
'Popularity' :'Popularite',
'Danceability':'Dansabilite',
'Energy': 'Energie',
'Loudness':'Intensite',
'Speechiness':'Parole',
'Acousticness':'Acoustique',
'Liveness':'Concert',
'Tempo':'Rythme',
'Duration': 'Duree',
'Valence':'Positivite',
'StartWeek':'DebutSemaine',
'EndWeek':'FinSemaine',
'Category' :'Genre',
'Artiste':'Artiste'
}, axis=1, inplace=True)
spotify.info()
<class 'pandas.core.frame.DataFrame'> Index: 1545 entries, 0 to 1555 Data columns (total 31 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Index 1545 non-null int64 1 Place 1545 non-null int64 2 Frequence 1545 non-null int64 3 Chanson 1545 non-null object 4 Ecoute 1545 non-null int64 5 Disciple 1545 non-null int64 6 DateSortie 1545 non-null object 7 Popularite 1545 non-null int64 8 Dansabilite 1545 non-null float64 9 Energie 1545 non-null float64 10 Intensite 1545 non-null float64 11 Parole 1545 non-null float64 12 Acoustique 1545 non-null float64 13 Concert 1545 non-null object 14 Rythme 1545 non-null float64 15 Duree 1545 non-null int64 16 Positivite 1545 non-null float64 17 DebutSemaine 1545 non-null object 18 FinSemaine 1545 non-null object 19 Genre 1545 non-null object 20 Artiste 1545 non-null object 21 NiveauPopularite 1545 non-null object 22 NiveauEcoute 1545 non-null object 23 NiveauEnergie 1545 non-null object 24 AnneeSortie 1545 non-null int32 25 MoisSortie 1545 non-null int32 26 JourSortie 1545 non-null int32 27 NomJourSortie 1545 non-null object 28 NomMoisSortie 1545 non-null object 29 WeekSortie 1545 non-null UInt32 30 Age 1545 non-null int64 dtypes: UInt32(1), float64(7), int32(3), int64(8), object(12) memory usage: 363.6+ KB
Vérification de la présence de lignes dupliquées
len(spotify)-len(spotify.drop_duplicates())
0
Vérification de la présence de valeurs manquantes
spotify.isnull().sum()
Index 0 Place 0 Frequence 0 Chanson 0 Ecoute 0 Disciple 0 DateSortie 0 Popularite 0 Dansabilite 0 Energie 0 Intensite 0 Parole 0 Acoustique 0 Concert 0 Rythme 0 Duree 0 Positivite 0 DebutSemaine 0 FinSemaine 0 Genre 0 Artiste 0 NiveauPopularite 0 NiveauEcoute 0 NiveauEnergie 0 AnneeSortie 0 MoisSortie 0 JourSortie 0 NomJourSortie 0 NomMoisSortie 0 WeekSortie 0 Age 0 dtype: int64
5- Analyse des donnée
L'analyse des données de spotify comprend les étapes suivantes:
- La statistique univariée
- La statistique bivariée
Statistique univariée
Dans Cette partie du projet on va procéder à l'étude, une par une, des variables qu'elle soit quantitative ou qualitative.
Pour les variables quantitatives, on va s'intéresser à identifier :
- Les valeurs extrêmes (Maximum et Minimum)
- L'étendue des valeurs
- La moyenne et la médiane
- Les quartiles
- Les valeurs manquantes
- Les valeurs aberrantes
- La modalité.
- La distribution
Pour les variables qualitatives, on va s'intéresser à identifier :
- Le pourcentage de valeus vides
- Les valeurs uniques
- La répartition des valeurs
Identification des colonnes de type numerique
col_number = spotify.select_dtypes(include=np.number).columns.tolist()
col_number
['Index', 'Place', 'Frequence', 'Ecoute', 'Disciple', 'Popularite', 'Dansabilite', 'Energie', 'Intensite', 'Parole', 'Acoustique', 'Rythme', 'Duree', 'Positivite', 'AnneeSortie', 'MoisSortie', 'JourSortie', 'WeekSortie', 'Age']
Identification des colonnes de type objet
col_objet = spotify.select_dtypes(include="object").columns.tolist()
col_objet
['Chanson', 'DateSortie', 'Concert', 'DebutSemaine', 'FinSemaine', 'Genre', 'Artiste', 'NiveauPopularite', 'NiveauEcoute', 'NiveauEnergie', 'NomJourSortie', 'NomMoisSortie']
Analyse univariée des variables quantitatives
Etude de la variable "Ecoute"
Identification des valeurs extrêmes, l'étendue des valeurs, la moyenne et la médiane de la variable "Ecoute"
ecoute_max=spotify['Ecoute'].max()
ecoute_min=spotify['Ecoute'].min()
etendue_ecoute=spotify['Ecoute'].max()-spotify['Ecoute'].min()
moyenne_ecoute=spotify['Ecoute'].mean()
mediane_ecoute=spotify['Ecoute'].median()
print(f'la valeur maximale des écoutes est: {"%.2f"% ecoute_max}')
print(f'la valeur minimale des écoutes est: {"%.2f"%ecoute_min}')
print(f'la valeur moyenne des écoutes est : {"%.2f"% moyenne_ecoute}')
print(f'la valeur médiane des écoutes est: {"%.2f"% mediane_ecoute}')
print('l\'étendue des écoutes: '+ str("%.2f"% etendue_ecoute))
la valeur maximale des écoutes est: 48633449.00 la valeur minimale des écoutes est: 4176083.00 la valeur moyenne des écoutes est : 6337136.38 la valeur médiane des écoutes est: 5269163.00 l'étendue des écoutes: 44457366.00
Calcul des quartiles
quartiles=spotify['Ecoute'].quantile([0.25, 0.5, 0.75])
quartiles
0.25 4,915,080.00 0.50 5,269,163.00 0.75 6,452,492.00 Name: Ecoute, dtype: float64
Recherche des valeurs manquantes dans "Ecoute"
spotify[spotify['Ecoute'].isnull()]['Index']
Series([], Name: Index, dtype: int64)
Recherche des valeurs aberrantes
# Determination des valeurs aberrantes sur la base d'une limite
limit=spotify['Ecoute'].quantile(.95)
ecoutes_aberrantes=spotify[spotify['Ecoute']>limit]
ecoutes_aberrantes['Ecoute']
0 48633449
1 47248719
2 40162559
3 37799456
4 33948454
...
733 10957181
935 11373347
1005 15129295
1356 12059592
1430 28509534
Name: Ecoute, Length: 78, dtype: int64
Modalié de la variable "Ecoute"
spotify['Ecoute'].unique()
array([48633449, 47248719, 40162559, ..., 4620876, 4607385, 4595450],
dtype=int64)
Nombre de valeurs par modalité
spotify['Ecoute'].value_counts()
Ecoute
48633449 1
4430642 1
7112419 1
7308690 1
8443771 1
..
5044929 1
5060903 1
5073657 1
5093408 1
4595450 1
Name: count, Length: 1545, dtype: int64
Distribution de la variable "Ecoute"
data=spotify
plt.figure(figsize=(13,4))
plt.subplot(1,2,1)
sns.histplot(spotify['Ecoute'], kde=False,bins=5,color="green").set_title('Histogramme de la variable "Ecoute"');
plt.subplot(1,2,2)
sns.boxplot(data=spotify[['Ecoute']], showmeans=True,palette=colors).set(xticklabels=[])
plt.title('Distribution boxplot de la variable "Ecoute" ')
plt.show()

Enseignements
- La musique la plus écoutée est quasiment à 50 millions d'écoutes ou de streams
- Le rapport est de 1 à 10 entre la musique la plus écoutée et celle la moins écoutée
- On constate un écart considérable entre les valeurs maximum et minimum
- Pas de valeurs nulles dans cette colonne
- Présence de valeurs aberrantes dans la partie supérieure justifiant l'écart
Etude de la variable "Disciple"
Identification des valeurs extrêmes, l'étendue des valeurs, la moyenne et la médiane de la variable "Disciple"
Disciple_max=spotify['Disciple'].max()
Disciple_min=spotify['Disciple'].min()
etendue_Disciple=spotify['Disciple'].max()-spotify['Disciple'].min()
moyenne_Disciple=spotify['Disciple'].mean()
mediane_Disciple=spotify['Disciple'].median()
print(f'la valeur maximale des disciples est: {"%.2f"% Disciple_max}')
print(f'la valeur minimale des disciples est: {"%.2f"%Disciple_min}')
print(f'la valeur moyenne des disciples est : {"%.2f"% moyenne_Disciple}')
print(f'la valeur mediane des disciples est: {"%.2f"% mediane_Disciple}')
print('l\'étendue des Disciples: '+ str("%.2f"% etendue_Disciple))
la valeur maximale des disciples est: 83337783.00 la valeur minimale des disciples est: 4883.00 la valeur moyenne des disciples est : 14716902.87 la valeur mediane des disciples est: 6852509.00 l'étendue des Disciples: 83332900.00
Calcul des quartiles
import pandas as pd
quartiles=spotify['Disciple'].quantile([0.25, 0.5, 0.75])
quartiles
0.25 2,123,734.00 0.50 6,852,509.00 0.75 22,698,747.00 Name: Disciple, dtype: float64
Recherche des valeurs manquantes de "Disciple"
spotify[spotify['Disciple'].isnull()]['Index']
Series([], Name: Index, dtype: int64)
Détermination des valeurs aberrantes
limit=spotify['Disciple'].quantile(.95)
disciple_aberrants=spotify[spotify['Disciple']>limit]
disciple_aberrants['Disciple']
3 83293380
81 56308172
91 67158068
116 83293380
119 83293380
...
1416 48544923
1419 48544923
1427 48544923
1430 48544923
1437 48544923
Name: Disciple, Length: 76, dtype: int64
Nombre de valeurs par modalité
spotify['Disciple'].value_counts()
Disciple
42227614 52
36177712 43
11821805 33
1251372 31
48544923 29
..
5799137 1
1254432 1
35910149 1
14122 1
208630 1
Name: count, Length: 599, dtype: int64
Distribution de la variable "Disciple"
data=spotify
plt.figure(figsize=(13,4))
plt.subplot(1,2,1)
sns.histplot(spotify['Disciple'], kde=False,bins=5,color="green").set_title('Histogramme de la variable "Disciple"');
plt.subplot(1,2,2)
sns.boxplot(data=spotify[['Disciple']], showmeans=True,palette=colors).set(xticklabels=[])
plt.title('Distribution boxplot de la variable "Disciple" ')
plt.show()

Enseignements
- On voit que la moyenne est très impactée par des valeurs extrêmes
- On voit que la médiane ne subit par ce type de déformation.
- La valeur maximale est 7 fois supérieure à la médiane.
- Beaucoup de chansons ont un nombre de disciples faible
Etude de la variable "Frequence" (Nombre d'apparitions dans les charts)
Identification des valeurs extrêmes, l'étendue des valeurs, la moyenne et la médiane de la variable "Frequence"
Frequence_max=spotify['Frequence'].max()
Frequence_min=spotify['Frequence'].min()
etendue_Frequence=spotify['Frequence'].max()-spotify['Frequence'].min()
moyenne_Frequence=spotify['Frequence'].mean()
mediane_Frequence=spotify['Frequence'].median()
print(f'la valeur maximale des fréquences est: {"%.2f"% Frequence_max}')
print(f'la valeur minimale des fréquences est: {"%.2f"% Frequence_min}')
print(f'la valeur moyenne des fréquences est : {"%.2f"% moyenne_Frequence}')
print(f'la valeur mediane des fréquences est: {"%.2f"% mediane_Frequence}')
print('l\'étendue des Frequences: '+ str("%.2f"% etendue_Frequence))
la valeur maximale des fréquences est: 142.00 la valeur minimale des fréquences est: 1.00 la valeur moyenne des fréquences est : 10.68 la valeur mediane des fréquences est: 4.00 l'étendue des Frequences: 141.00
Calcul des quartiles de "Frequence"
quartiles=spotify['Frequence'].quantile([0.25, 0.5, 0.75])
quartiles
0.25 1.00 0.50 4.00 0.75 12.00 Name: Frequence, dtype: float64
Recherche des valeurs manquantes dans "Frequence"
spotify[spotify['Frequence'].isnull()]['Frequence']
Series([], Name: Frequence, dtype: int64)
Détermination des valeurs aberrantes
limit=spotify['Frequence'].quantile(.95)
frequence_aberrants=spotify[spotify['Frequence']>limit]
frequence_aberrants['Frequence']
24 83
34 83
43 49
46 51
65 83
..
567 49
611 46
616 45
781 46
800 45
Name: Frequence, Length: 77, dtype: int64
Nombre de valeurs par modalité
spotify['Frequence'].value_counts()
Frequence
1 504
2 149
3 110
4 76
5 70
...
74 1
47 1
77 1
56 1
84 1
Name: count, Length: 75, dtype: int64
Distribution de la variable "Frequence"
data=spotify
plt.figure(figsize=(13,4))
plt.subplot(1,2,1)
sns.histplot(spotify['Frequence'], kde=False,bins=5,color="green").set_title('Histogramme de la variable "Frequence"');
plt.subplot(1,2,2)
sns.boxplot(data=spotify[['Frequence']], showmeans=True,palette=colors).set(xticklabels=[])
plt.title('Distribution boxplot de la variable "Frequence" ')
plt.show()

Enseignements
- La musique la plus écoutée est quasiment à 50 millions d'écoutes ou de streams
- Le rapport est de 1 à 10 entre la musique la plus écoutée et celle la moins écoutée
- On constate un écart considérable entre les valeurs maximum et minimum
- Pas de valeurs nulles dans cette colonne
- Présence de valeurs aberrantes dans la partie supérieure justifiant l'écart
Etude de la variable "Energie"
Identification des valeurs extrêmes, l'étendue des valeurs, la moyenne et la médiane de la variable "Energie"
Energie_max=spotify['Energie'].max()
Energie_min=spotify['Energie'].min()
etendue_Energie=spotify['Energie'].max()-spotify['Energie'].min()
moyenne_Energie=spotify['Energie'].mean()
mediane_Energie=spotify['Energie'].median()
print(f'la valeur maximale des Energies est: {"%.2f"% Energie_max}')
print(f'la valeur minimale des Energies est: {"%.2f"%Energie_min}')
print(f'la valeur moyenne des Energies est : {"%.2f"% moyenne_Energie}')
print(f'la valeur mediane des Energies est: {"%.2f"% mediane_Energie}')
print('l\'étendue des Energies: '+ str("%.2f"% etendue_Energie))
la valeur maximale des Energies est: 0.97 la valeur minimale des Energies est: 0.05 la valeur moyenne des Energies est : 0.63 la valeur mediane des Energies est: 0.64 l'étendue des Energies: 0.92
Calcul des quartiles de "Energie"
quartiles=spotify['Energie'].quantile([0.25, 0.5, 0.75])
quartiles
0.25 0.53 0.50 0.64 0.75 0.75 Name: Energie, dtype: float64
Recherche des valeurs manquantes
spotify[spotify['Energie'].isnull()]['Energie']
Series([], Name: Energie, dtype: float64)
Détermination des valeurs aberrantes
limit=spotify['Energie'].quantile(.95)
energie_aberrants=spotify[spotify['Energie']>limit]
energie_aberrants['Energie']
3 0.90
55 0.94
56 0.89
73 0.90
75 0.94
...
1435 0.89
1494 0.97
1495 0.90
1525 0.88
1540 0.88
Name: Energie, Length: 78, dtype: float64
Nombre de valeurs par modalité
spotify['Energie'].value_counts()
Energie
0.62 10
0.64 9
0.59 9
0.63 9
0.79 8
..
0.85 1
0.94 1
0.91 1
0.47 1
0.78 1
Name: count, Length: 574, dtype: int64
Distribution de la variable "Energie"
data=spotify
plt.figure(figsize=(13,4))
plt.subplot(1,2,1)
sns.histplot(spotify['Energie'], kde=False,bins=10,color="green").set_title('Histogramme de la variable "Energie"');
plt.subplot(1,2,2)
sns.boxplot(data=spotify[['Energie']], showmeans=True,palette=colors).set(xticklabels=[])
plt.title('Distribution boxplot de la variable "Energie" ')
plt.show()

Enseignements
- Les musiques sont plutôt avec une énergie haute dans l'ensemble.
- Le quartile le plus bas reste au-dessus de 0,5 et un quartile maximum à 0,75
Etude des variables "Dansabilité", "Energie", "Parole","Acoustique" et "Positivite"
Pour chacun de ces variables, on va déterminer:
- Le maximum
- Le minimum
- L'étendue
- le mode
- La médiane
- La moyenne
- L'ecart-type
- Le Kurtosis
- Le coefficient d'asymétrie
Données statistiques et distribution de la variable "Dansabilite"
Dansabilite_max=spotify['Dansabilite'].max()
Dansabilite_min=spotify['Dansabilite'].min()
etendue_Dansabilite=spotify['Dansabilite'].max()-spotify['Dansabilite'].min()
moyenne_Dansabilite=spotify['Dansabilite'].mean()
mediane_Dansabilite=spotify['Dansabilite'].median()
ecart_type_Dansabilite = spotify['Dansabilite'].std()
kurtosis_Dansabilite=spotify['Dansabilite'].kurt()
coefasy_Dansabilite=spotify['Dansabilite'].skew()
mode_Dansabilite=spotify['Dansabilite'].mode()
print(f'la valeur maximale de Dansabilite est: {"%.2f"% Dansabilite_max}')
print(f'la valeur minimale de Dansabilite est: {"%.2f"%Dansabilite_min}')
print(f'la valeur moyenne de Dansabilite est : {"%.2f"% moyenne_Dansabilite}')
print(f'la valeur mediane de Dansabilite est: {"%.2f"% mediane_Dansabilite}')
print('l\'étendue des Dansabilite: '+ str("%.2f"% etendue_Dansabilite))
print(f'l\'écart-type de Dansabilite est: {"%.2f"% ecart_type_Dansabilite}')
print(f'le kurtosis de Dansabilite est : {"%.2f"% kurtosis_Dansabilite}')
print(f'le coefficient d\'assymetrie de Dansabilite est: {"%.2f"% coefasy_Dansabilite}')
print(f'les valeurs les plus courantes sont: {mode_Dansabilite}')
la valeur maximale de Dansabilite est: 0.98 la valeur minimale de Dansabilite est: 0.15 la valeur moyenne de Dansabilite est : 0.69 la valeur mediane de Dansabilite est: 0.71 l'étendue des Dansabilite: 0.83 l'écart-type de Dansabilite est: 0.14 le kurtosis de Dansabilite est : 0.11 le coefficient d'assymetrie de Dansabilite est: -0.60 les valeurs les plus courantes sont: 0 0.66 1 0.67 2 0.76 Name: Dansabilite, dtype: float64
plt.figure(figsize=(12, 4))
sns.set_theme(style="white")
sns.histplot(spotify['Dansabilite'],kde=True,bins=20,color="green").set_title('Distribution de la Dansabilité des chansons ')
plt.xlabel('Dansabilité')
plt.ylabel('Valeurs ')
plt.show()

Données statistiques et distribution de la variable "Energie"
Energie_max=spotify['Energie'].max()
Energie_min=spotify['Energie'].min()
etendue_Energie=spotify['Energie'].max()-spotify['Energie'].min()
moyenne_Energie=spotify['Energie'].mean()
mediane_Energie=spotify['Energie'].median()
ecart_type_Energie = spotify['Energie'].std()
kurtosis_Energie=spotify['Energie'].kurt()
coefasy_Energie=spotify['Energie'].skew()
mode_Energie=spotify['Energie'].mode()
print(f'la valeur maximale de Energie est: {"%.2f"% Energie_max}')
print(f'la valeur minimale de Energie est: {"%.2f"%Energie_min}')
print(f'la valeur moyenne de Energie est : {"%.2f"% moyenne_Energie}')
print(f'la valeur mediane de Energie est: {"%.2f"% mediane_Energie}')
print('l\'étendue des Energie: '+ str("%.2f"% etendue_Energie))
print(f'l\'écart-type de Energie est: {"%.2f"% ecart_type_Energie}')
print(f'le kurtosis de Energie est : {"%.2f"% kurtosis_Energie}')
print(f'le coefficient d\'assymetrie de Energie est: {"%.2f"% coefasy_Energie}')
print(f'la valeur la plus courante est: {mode_Energie}')
la valeur maximale de Energie est: 0.97 la valeur minimale de Energie est: 0.05 la valeur moyenne de Energie est : 0.63 la valeur mediane de Energie est: 0.64 l'étendue des Energie: 0.92 l'écart-type de Energie est: 0.16 le kurtosis de Energie est : 0.09 le coefficient d'assymetrie de Energie est: -0.48 la valeur la plus courante est: 0 0.62 Name: Energie, dtype: float64
plt.figure(figsize=(12, 4))
sns.histplot(spotify['Energie'],kde=True, bins=20,color="green")
plt.title('Distribution de l\'énergie des chansons')
plt.xlabel('Energie')
plt.ylabel('Valeurs ')
plt.show()

Données statistiques et distribution de la variable "Parole"
Parole_max=spotify['Parole'].max()
Parole_min=spotify['Parole'].min()
etendue_Parole=spotify['Parole'].max()-spotify['Parole'].min()
moyenne_Parole=spotify['Parole'].mean()
mediane_Parole=spotify['Parole'].median()
ecart_type_Parole = spotify['Parole'].std()
kurtosis_Parole=spotify['Parole'].kurt()
coefasy_Parole=spotify['Parole'].skew()
mode_Parole=spotify['Parole'].mode()
print(f'la valeur maximale de Parole est: {"%.2f"% Parole_max}')
print(f'la valeur minimale de Parole est: {"%.2f"%Parole_min}')
print(f'la valeur moyenne de Parole est : {"%.2f"% moyenne_Parole}')
print(f'la valeur mediane de Parole est: {"%.2f"% mediane_Parole}')
print('l\'étendue des Parole: '+ str("%.2f"% etendue_Parole))
print(f'l\'écart-type de Parole est: {"%.2f"% ecart_type_Parole}')
print(f'le kurtosis de Parole est : {"%.2f"% kurtosis_Parole}')
print(f'le coefficient d\'assymetrie de Parole est: {"%.2f"% coefasy_Parole}')
print(f'la valeur la plus courante est: {mode_Parole}')
la valeur maximale de Parole est: 0.88 la valeur minimale de Parole est: 0.02 la valeur moyenne de Parole est : 0.12 la valeur mediane de Parole est: 0.08 l'étendue des Parole: 0.86 l'écart-type de Parole est: 0.11 le kurtosis de Parole est : 3.20 le coefficient d'assymetrie de Parole est: 1.68 la valeur la plus courante est: 0 0.10 Name: Parole, dtype: float64
plt.figure(figsize=(12, 4))
sns.histplot(spotify['Parole'],kde=True,color="green")
plt.title('Distribution de la Parole des chansons')
plt.xlabel('Parole')
plt.ylabel('Valeurs ')
plt.show()

Données statistiques et distribution de la variable "Acoustique"
Acoustique_max=spotify['Acoustique'].max()
Acoustique_min=spotify['Acoustique'].min()
etendue_Acoustique=spotify['Acoustique'].max()-spotify['Acoustique'].min()
moyenne_Acoustique=spotify['Acoustique'].mean()
mediane_Acoustique=spotify['Acoustique'].median()
ecart_type_Acoustique = spotify['Acoustique'].std()
kurtosis_Acoustique=spotify['Acoustique'].kurt()
coefasy_Acoustique=spotify['Acoustique'].skew()
mode_Acoustique=spotify['Acoustique'].mode()
print(f'la valeur maximale de Acoustique est: {"%.2f"% Acoustique_max}')
print(f'la valeur minimale de Acoustique est: {"%.2f"%Acoustique_min}')
print(f'la valeur moyenne de Acoustique est : {"%.2f"% moyenne_Acoustique}')
print(f'la valeur mediane de Acoustique est: {"%.2f"% mediane_Acoustique}')
print('l\'étendue des Acoustique: '+ str("%.2f"% etendue_Acoustique))
print(f'l\'écart-type de Acoustique est: {"%.2f"% ecart_type_Acoustique}')
print(f'le kurtosis de Acoustique est : {"%.2f"% kurtosis_Acoustique}')
print(f'le coefficient d\'assymetrie de Acoustique est: {"%.2f"% coefasy_Acoustique}')
print(f'la valeur la plus courante est: {mode_Acoustique}')
la valeur maximale de Acoustique est: 0.99 la valeur minimale de Acoustique est: 0.00 la valeur moyenne de Acoustique est : 0.25 la valeur mediane de Acoustique est: 0.16 l'étendue des Acoustique: 0.99 l'écart-type de Acoustique est: 0.25 le kurtosis de Acoustique est : 0.38 le coefficient d'assymetrie de Acoustique est: 1.15 la valeur la plus courante est: 0 0.11 Name: Acoustique, dtype: float64
plt.figure(figsize=(12, 4))
sns.set_theme(style="white")
sns.histplot(spotify['Acoustique'],kde=True,color="green")
plt.title('Distribution de l\'acoustique des chansons')
plt.xlabel('Acoustique')
plt.ylabel('Valeurs ')
plt.show()

Données statistiques et distribution de la variable "Positivite"
Positivite_max=spotify['Positivite'].max()
Positivite_min=spotify['Positivite'].min()
etendue_Positivite=spotify['Positivite'].max()-spotify['Positivite'].min()
moyenne_Positivite=spotify['Positivite'].mean()
mediane_Positivite=spotify['Positivite'].median()
ecart_type_Positivite = spotify['Positivite'].std()
kurtosis_Positivite=spotify['Positivite'].kurt()
coefasy_Positivite=spotify['Positivite'].skew()
mode_Positivite=spotify['Positivite'].mode()
print(f'la valeur maximale de Positivite est: {"%.2f"% Positivite_max}')
print(f'la valeur minimale de Positivite est: {"%.2f"%Positivite_min}')
print(f'la valeur moyenne de Positivite est : {"%.2f"% moyenne_Positivite}')
print(f'la valeur mediane de Positivite est: {"%.2f"% mediane_Positivite}')
print('l\'étendue des Positivite: '+ str("%.2f"% etendue_Positivite))
print(f'l\'écart-type de Positivite est: {"%.2f"% ecart_type_Positivite}')
print(f'le kurtosis de Positivite est : {"%.2f"% kurtosis_Positivite}')
print(f'le coefficient d\'assymetrie de Positivite est: {"%.2f"% coefasy_Positivite}')
print(f'les valeurs les plus courantes sont: {mode_Positivite}')
la valeur maximale de Positivite est: 0.98 la valeur minimale de Positivite est: 0.03 la valeur moyenne de Positivite est : 0.51 la valeur mediane de Positivite est: 0.51 l'étendue des Positivite: 0.95 l'écart-type de Positivite est: 0.23 le kurtosis de Positivite est : -0.84 le coefficient d'assymetrie de Positivite est: -0.02 les valeurs les plus courantes sont: 0 0.41 1 0.58 Name: Positivite, dtype: float64
plt.figure(figsize=(12, 4))
sns.set_theme(style="white")
sns.histplot(spotify['Positivite'],kde=True,color="green")
plt.title('Distribution de la Positivité des chansons')
plt.xlabel('Positivité')
plt.ylabel('Valeurs')
plt.show()

Analyse de la distibution des variables Dansabilité,Energie,Parole,Acoustique et Positivite
sns.set_context("paper", font_scale=0.8)
data=spotify[['Dansabilite','Energie','Parole','Acoustique','Positivite']]
plt.figure(figsize=(13,4))
plt.subplot(1,2,1)
sns.boxplot(data=data,palette=colors).set_title('Boxplot "Dansabilite","Energie","Parole","Acoustique" et "Positivite" ');
plt.subplot(1,2,2)
sns.barplot(data=data,palette=colors)
plt.title('Barplot "Dansabilite","Energie","Parole","Acoustique" et "Positivite" ')
plt.show()

Remarques sur les distibutions
La base unitaire étant la même (de 0 à 1), on peut facilement comparer ces distributions. On peut constater:
- Une concentration des valeurs au niveau supérieur pour "Dansabilite" , "Energie" et "Positivité".
- On remarque tout de suite les critères faisabilité et énergie ont très fortement la même distribution. Il est donc possible de trouver une corrélation entre ses 2 colonnes.
- La variable "Parole" est concentrée sur les valeurs basses pour ces quatre quartiles avec certaines valeurs extrêmes
- L'acoustique est un critère qui occupe toute la longueur du spectre. Il est donc possible qu'on ne trouve pas de relation entre la popularité d'une chanson et son acoustique.
- La positivité est également très étendue
- La concentration des valeurs est très forte au démarrage pour les variables Parole et Acoustique. On s'attend donc à obtenir un coefficient d'asymétrie positif pour ces variables
- Les valeurs étant très fortement concentrées sur la fin pour les variables Dansabilité et Energie, on s'attend donc à obtenir un coefficient d'asymétrie négatif pour ces variables
Comparaison graphique de la distibution des varaibles 'Dansabilite','Energie','Parole','Acoustique' et 'Positivite'
plt.figure(figsize=(12, 4))
data=spotify[['Dansabilite','Energie','Parole','Acoustique','Positivite']]
ax = sns.kdeplot(data=data)
plt.show()

Résumé des données statistiques de certaines variables numeriques
spotify[['Place','Place', 'Frequence', 'Ecoute', 'Disciple',
'Popularite', 'Dansabilite', 'Energie', 'Intensite',
'Parole', 'Acoustique', 'Concert', 'Duree', 'Positivite']].describe()
| Place | Place | Frequence | Ecoute | Disciple | Popularite | Dansabilite | Energie | Intensite | Parole | Acoustique | Duree | Positivite | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 1,545.00 | 1,545.00 | 1,545.00 | 1,545.00 | 1,545.00 | 1,545.00 | 1,545.00 | 1,545.00 | 1,545.00 | 1,545.00 | 1,545.00 | 1,545.00 | 1,545.00 |
| mean | 87.83 | 87.83 | 10.68 | 6,337,136.38 | 14,716,902.87 | 70.09 | 0.69 | 0.63 | -6.35 | 0.12 | 0.25 | 197,940.82 | 0.51 |
| std | 58.13 | 58.13 | 16.39 | 3,375,402.18 | 16,675,788.51 | 15.82 | 0.14 | 0.16 | 2.51 | 0.11 | 0.25 | 47,148.93 | 0.23 |
| min | 1.00 | 1.00 | 1.00 | 4,176,083.00 | 4,883.00 | 0.00 | 0.15 | 0.05 | -25.17 | 0.02 | 0.00 | 30,133.00 | 0.03 |
| 25% | 37.00 | 37.00 | 1.00 | 4,915,080.00 | 2,123,734.00 | 65.00 | 0.60 | 0.53 | -7.49 | 0.05 | 0.05 | 169,266.00 | 0.34 |
| 50% | 80.00 | 80.00 | 4.00 | 5,269,163.00 | 6,852,509.00 | 73.00 | 0.71 | 0.64 | -5.99 | 0.08 | 0.16 | 193,591.00 | 0.51 |
| 75% | 137.00 | 137.00 | 12.00 | 6,452,492.00 | 22,698,747.00 | 80.00 | 0.80 | 0.75 | -4.71 | 0.17 | 0.39 | 218,902.00 | 0.69 |
| max | 200.00 | 200.00 | 142.00 | 48,633,449.00 | 83,337,783.00 | 100.00 | 0.98 | 0.97 | 1.51 | 0.88 | 0.99 | 588,139.00 | 0.98 |
Analyse univariée des variables qualitatives ou catégorielles
On va s'interesser à identifier pour chacune des variables:
- Les valeurs vides
- Le pourcentage de valeus vides
- Les valeurs uniques
- La répartition des valeurs
Etude de la variable "Genre"
# Nombre de genres differents presents dans le classement
genre_different=spotify['Genre'].nunique()
# Nombre de genre presents dans le classement
genre_count=spotify['Genre'].count()
# Répartition des genres
genre_reparti = spotify['Genre'].value_counts()
print(f'Le nombre de genres differents dans le classement :{genre_different}')
print(f'Le nombre de genres dans le classement :{genre_count}')
print(f'La répartition des genres est le suivant:{genre_reparti}')
Le nombre de genres differents dans le classement :7 Le nombre de genres dans le classement :1545 La répartition des genres est le suivant:Genre Pop 819 Rap 201 Hip hop 199 Other 145 Latin 138 Rock 31 Funk 12 Name: count, dtype: int64
sns.set_context("paper", font_scale=0.9)
plt.figure(figsize=(12, 4))
data= pd.DataFrame(spotify.Genre.value_counts().rename_axis('Genre').reset_index(name='total'))
sns.barplot(x="Genre",y="total",data=data ,palette=colors).set_title('Répartition de la variable "Genre"');
plt.show()

Enseignements sur la variable "Genre"
- Il y a énormément de disparité entre les genres en terme de volume de chansons.
- Les 5 premiers genres représentent plus que 80% des chansons.
Etude de la variable "Artiste"
# Nombre de Artiste presents dans le classement
Artiste_count=spotify['Artiste'].count()
# Nombre de Artiste differents presents dans le classement
Artiste_different=spotify['Artiste'].nunique()
# fréquence de classement des artistes
Artistes_classes = spotify['Artiste'].value_counts()
print(f'Le nombre de Artistes présents dans le classement est :{Artiste_count}')
print(f'Le nombre de Artistes differentes présents dans le classement est :{Artiste_different}')
print(f'La fréquece de classement des artistes est la suivante :{Artistes_classes}')
Le nombre de Artistes présents dans le classement est :1545
Le nombre de Artistes differentes présents dans le classement est :509
La fréquece de classement des artistes est la suivante :Artiste
Taylor Swift 52
Bad Bunny 46
Justin Bieber 34
Lil Uzi Vert 33
Juice WRLD 32
..
BANNERS 1
Jay Wheeler 1
Hippie Sabotage 1
Hugo & Guilherme 1
Dadá Boladão 1
Name: count, Length: 509, dtype: int64
sns.set_context("paper", font_scale=0.9)
plt.figure(figsize=(12,5))
data= pd.DataFrame(spotify.Artiste.value_counts().rename_axis('Artiste').reset_index(name='total'))
data=data.head(15)
sns.barplot(x="Artiste",y="total",data=data ,palette=colors).set_title('Répartition de la variable "Artiste" pour les 15 Top ');
plt.show()

Enseignements sur la variable "Artiste"
- Dans la majorite des cas, le nombre d'apparitions des artistes dans les classements est superieur à 20 pour la péroide etudiée.
Etude de la variable "AnneeSortie"
# Nombre d'années de sortie presentes dans le classement
AnneeSortie_count=spotify['AnneeSortie'].count()
# Nombre d'AnneeSortie differentes presents dans le classement
AnneeSortie_different=spotify['AnneeSortie'].nunique()
# fréquence de classement des AnneeSorties
AnneeSorties_classes = spotify['AnneeSortie'].value_counts()
print(f'Le nombre d\'AnneeSorties présents dans le classement est :{AnneeSortie_count}')
print(f'Le nombre d\'AnneeSorties differentes présents dans le classement est :{AnneeSortie_different}')
print(f'La fréquece de classement des AnneeSorties est la suivante :{AnneeSorties_classes}')
Le nombre d'AnneeSorties présents dans le classement est :1545 Le nombre d'AnneeSorties differentes présents dans le classement est :45 La fréquece de classement des AnneeSorties est la suivante :AnneeSortie 2020 783 2021 396 2019 181 2018 43 2017 16 2016 13 2013 12 2014 12 2015 10 2012 9 2010 5 2011 4 1957 4 2000 4 1963 3 2005 3 1994 3 1980 3 1959 3 1983 3 2002 2 1978 2 1981 2 2006 2 1990 2 1998 2 2008 2 1991 2 1995 2 2004 2 1985 1 1999 1 1979 1 1975 1 1970 1 1973 1 1965 1 1988 1 1984 1 1942 1 1962 1 1977 1 2007 1 1964 1 2009 1 Name: count, dtype: int64
plt.figure(figsize=(12, 4))
data= pd.DataFrame(spotify.AnneeSortie.value_counts().rename_axis('AnneeSortie').reset_index(name='total'))
data=data[data['total']>10]
sns.barplot(x="AnneeSortie",y="total",data=data ,palette=colors).set_title('Distribution de la variable "AnneeSortie"');
plt.show()

Enseignements sur la variable "AnneeSortie"
- 88% des chansons classées dans le Top Chart 2020-2021 sont sorties entre 2019 et 2021.
Statistique bivariée ou bidimentionnelle
Dans cette partie du projet, on va s'intéresser aux relations entre les variables deux à deux. On cherchera à identifier la fluctuation entre les deux variables.
- Du point de vue statistique, le coefficient de corrélation permettra de confirmer l'existence ou pas de la corrélation.
- Du point de vue visuel, la représentation graphique en nuage de points permettra d'observer la corrélation entre les deux variables. Nous allons procéder de la manière suivante:
- Corrélation entre deux variables quantitatives
- Corrélation entre une variable quantitative et une variable qualitative
- Corrélation entre une variable qualitative et une variable quantitative
Corrélation entre deux variables quantitatives
Corrélation entre les écoutes et la popularité
# Covariance des variables "Ecoute" et "Popularite"
cov_ecoute_popularite=spotify[['Ecoute','Popularite']].cov()
# Le coefficient de corrélation des variables Ecoute et Popularite
corr_ecoute_popularite = spotify[['Ecoute','Popularite']].corr()
print(f'La covariance est :{cov_ecoute_popularite['Popularite'].head(1)}')
print(f'Le coefficient de symetrie est :{corr_ecoute_popularite['Popularite'].head(1)}')
La covariance est :Ecoute 6,579,557.00 Name: Popularite, dtype: float64 Le coefficient de symetrie est :Ecoute 0.12 Name: Popularite, dtype: float64
plt.figure(figsize=(12, 4))
sns.regplot(x="Ecoute",y="Popularite",fit_reg=True, data=spotify,color="#008000").set_title('Corrélation entre les variables "Ecoutes" et "Popularite" ');
plt.show()

Enseignements sur la corrélation des variables "Ecoute" et "Popularite"
- On peut confirmer que la corrélation entre ces deux variables est faible selon la valeur calculée du coefficient d'asymétrie (0,12).
- Le représentation en nuage de points indique aussi cette faible corrélation entre ces deux variables
- Le nombre d'écoute n'est donc pas un indicateur fiable pour expliquer la popularité d'une chanson
Corrélation entre les variable "dansabilite" et "positivite"
# Covariance des variables Dansabilite et Positivite
cov_Dansabilite_Positivite=spotify[['Dansabilite','Positivite']].cov()
# Le coefficient de corrélation des variables Dansabilite et Positivite
corr_Dansabilite_Positivite = spotify[['Dansabilite','Positivite']].corr()
print(f'La covariance est :{cov_Dansabilite_Positivite['Positivite'].head(1)}')
print(f'Le coefficient de symetrie est :{corr_Dansabilite_Positivite['Positivite'].head(1)}')
La covariance est :Dansabilite 0.01 Name: Positivite, dtype: float64 Le coefficient de symetrie est :Dansabilite 0.36 Name: Positivite, dtype: float64
plt.figure(figsize=(12, 4))
sns.regplot(x="Dansabilite",y="Positivite",fit_reg=True, data=spotify,color="#008000").set_title(
"Corrélation entre la dansabilité et la positivité ");
plt.show()

Enseignements sur la corrélation des variables "Dansabilité" et "Positivite"
- On peut confirmer que la corrélation entre ces deux variables est un peu plus forte selon la valeur calculée du coefficient d'asymétrie (0,36).
- Le représentation en nuage de points indique aussi cette confirmation malgré une grande disparité.
- Les musiques dansantes ont donc tendance à être positives mais ce n'est pas une règle absolue
- La dansabilité sera un bon indicateur pour le choisir rapidement les morceaux mais ne pourra pas être le seul critère.
Corrélation entre les variables "Intensite" et "Energie"
# Covariance des variables Intensite et Energie
cov_Intensite_Energie=spotify[['Intensite','Energie']].cov()
# Le coefficient de corrélation des variables Intensite et Energie
corr_Intensite_Energie = spotify[['Intensite','Energie']].corr()
print(f'La covariance est :{cov_Intensite_Energie['Energie'].head(1)}')
print(f'Le coefficient de symetrie est :{corr_Intensite_Energie['Energie'].head(1)}')
La covariance est :Intensite 0.30 Name: Energie, dtype: float64 Le coefficient de symetrie est :Intensite 0.73 Name: Energie, dtype: float64
plt.figure(figsize=(12, 4))
sns.regplot(x="Energie",y="Intensite",fit_reg=True, data=spotify,color="#008000").set_title("Corrélation entre l'énergie et l'intensité");
plt.show()

Enseignements sur la corrélation des variables "Intensité" et "Energie"
- La représentation en nuage de points ainsi que la valeur calculée du coefficient d'asymétrie (0.73) indiquent une corrélation forte entre l'intensité et l'énergie
- L'indicateur d'intensité semble bien lié à celle de l'énergie.
- Connaitre l'intensité d'une chanson peut nous donner une indication sur l'énergie et ainsi sélectionner ce type de morceau éventuellement.
Matrice de corrélation
# Creation d'un nouveau DataFrame:spotify_metrique
spotify_metrique = spotify[[
'Index', 'Place', 'Frequence', 'Ecoute', 'Disciple',
'Popularite', 'Dansabilite', 'Energie', 'Intensite',
'Parole', 'Acoustique', 'Concert', 'Rythme', 'Duree', 'Positivite', 'Age'
]]
spotify_metrique.columns
correlation_matrix =spotify_metrique.corr()
correlation_matrix
| Index | Place | Frequence | Ecoute | Disciple | Popularite | Dansabilite | Energie | Intensite | Parole | Acoustique | Concert | Rythme | Duree | Positivite | Age | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Index | 1.00 | 0.25 | -0.36 | -0.26 | 0.09 | -0.33 | 0.13 | -0.02 | -0.01 | 0.11 | -0.06 | 0.03 | 0.02 | -0.02 | -0.05 | -0.09 |
| Place | 0.25 | 1.00 | -0.42 | -0.30 | -0.23 | -0.16 | 0.02 | 0.06 | 0.03 | 0.04 | -0.01 | 0.01 | 0.03 | -0.03 | 0.05 | 0.04 |
| Frequence | -0.36 | -0.42 | 1.00 | -0.06 | 0.03 | 0.23 | 0.03 | -0.06 | 0.03 | -0.06 | 0.05 | -0.06 | -0.05 | 0.03 | 0.02 | -0.01 |
| Ecoute | -0.26 | -0.30 | -0.06 | 1.00 | 0.10 | 0.12 | -0.08 | 0.00 | -0.03 | -0.06 | 0.03 | 0.04 | 0.05 | 0.02 | 0.04 | 0.09 |
| Disciple | 0.09 | -0.23 | 0.03 | 0.10 | 1.00 | 0.10 | -0.10 | -0.07 | -0.03 | -0.07 | 0.02 | -0.01 | -0.02 | 0.14 | -0.11 | -0.08 |
| Popularite | -0.33 | -0.16 | 0.23 | 0.12 | 0.10 | 1.00 | 0.03 | 0.09 | 0.16 | -0.03 | -0.09 | -0.03 | -0.02 | 0.08 | -0.00 | -0.11 |
| Dansabilite | 0.13 | 0.02 | 0.03 | -0.08 | -0.10 | 0.03 | 1.00 | 0.14 | 0.23 | 0.24 | -0.32 | -0.11 | -0.04 | -0.10 | 0.36 | -0.19 |
| Energie | -0.02 | 0.06 | -0.06 | 0.00 | -0.07 | 0.09 | 0.14 | 1.00 | 0.73 | 0.02 | -0.54 | 0.12 | 0.11 | 0.06 | 0.36 | -0.11 |
| Intensite | -0.01 | 0.03 | 0.03 | -0.03 | -0.03 | 0.16 | 0.23 | 0.73 | 1.00 | -0.02 | -0.48 | 0.04 | 0.10 | 0.08 | 0.30 | -0.25 |
| Parole | 0.11 | 0.04 | -0.06 | -0.06 | -0.07 | -0.03 | 0.24 | 0.02 | -0.02 | 1.00 | -0.13 | 0.07 | 0.11 | -0.09 | 0.04 | -0.14 |
| Acoustique | -0.06 | -0.01 | 0.05 | 0.03 | 0.02 | -0.09 | -0.32 | -0.54 | -0.48 | -0.13 | 1.00 | -0.01 | -0.06 | -0.05 | -0.10 | 0.16 |
| Concert | 0.03 | 0.01 | -0.06 | 0.04 | -0.01 | -0.03 | -0.11 | 0.12 | 0.04 | 0.07 | -0.01 | 1.00 | -0.02 | 0.02 | 0.01 | 0.05 |
| Rythme | 0.02 | 0.03 | -0.05 | 0.05 | -0.02 | -0.02 | -0.04 | 0.11 | 0.10 | 0.11 | -0.06 | -0.02 | 1.00 | -0.00 | 0.06 | -0.01 |
| Duree | -0.02 | -0.03 | 0.03 | 0.02 | 0.14 | 0.08 | -0.10 | 0.06 | 0.08 | -0.09 | -0.05 | 0.02 | -0.00 | 1.00 | -0.12 | 0.02 |
| Positivite | -0.05 | 0.05 | 0.02 | 0.04 | -0.11 | -0.00 | 0.36 | 0.36 | 0.30 | 0.04 | -0.10 | 0.01 | 0.06 | -0.12 | 1.00 | 0.10 |
| Age | -0.09 | 0.04 | -0.01 | 0.09 | -0.08 | -0.11 | -0.19 | -0.11 | -0.25 | -0.14 | 0.16 | 0.05 | -0.01 | 0.02 | 0.10 | 1.00 |
Représentaion de la carte de chaleur
plt.figure(figsize=(12, 6))
sns.heatmap(correlation_matrix,annot=True,fmt=".2f", cmap="GnBu",cbar=True,linewidths=.5)
plt.title('Carte de chaleur de la corrélation des caractéristiques des chansons du Top 200 Charts de Spotify')
plt.show()

Enseignements tirés de la carte de chaleur
- Correlation faible entre disciple et ecoute :0,10
- Correlation faible entre positivite et dansabilité: 0,36
- Correlation forte entre intensite et energie:0.73
- Correlation moyenne et negative entre energie et acoustique:-0,54
- On ne peut pas se baser sur les artistes avec beaucoup de folollers pour garantir l'ecoute
Corrélation entre une variable quantitative et une variable qualitative
Distribution de la variable "Parole" selon le genre de musique
plt.figure(figsize=(12, 4))
sns.boxplot(x='Genre',y='Parole', data=spotify, hue="Genre",palette=colors)
plt.title('Distribution de "Parole" selon "Genre de musique" ')
plt.xlabel('Genre')
plt.ylabel('Parole')
plt.show()

Renseignements
- Grande disparité dans la distribution
- Les genres "Hip hop" et "Rap" ont une distibution plus large que les autres
Distribution de la variable "NiveauEcoute" selon le genre de musique
plt.figure(figsize=(12, 4))
sns.boxplot(x='Genre',y='Ecoute', data=spotify, hue="Genre",palette=colors)
plt.title('Distribution de "NiveauEcoute" selon la variable "Genre de musique" ')
plt.xlabel('Genre')
plt.ylabel('Ecoute')
plt.show()

Renseignement
- Beaucoup de valeurs extrêmes qui empêchent d'analyser la distribution des valeurs
Corrélation entre deux variables qualitatives (catégorielles)
Corrélation entre les variables "Genre" et "NiveauPopularite"
pd.crosstab(spotify.Genre,spotify.NiveauPopularite)
| NiveauPopularite | Faible | Forte |
|---|---|---|
| Genre | ||
| Funk | 3 | 9 |
| Hip hop | 48 | 151 |
| Latin | 1 | 137 |
| Other | 66 | 79 |
| Pop | 82 | 737 |
| Rap | 36 | 165 |
| Rock | 10 | 21 |
plt.figure(figsize=(14,4))
sns.countplot(x='Genre',hue='NiveauPopularite', data=spotify,palette=colors)
plt.title("Diagramme du niveau de popularité des genres");

Renseignement
- Tres forte popularité du genre "Pop"
- L'influence du genre de musique sur la popularité est marqué
Corrélation entre les variables "Genre" et "NiveauEnergie"
pd.crosstab(spotify.Genre,spotify.NiveauEnergie)
| NiveauEnergie | Faible | Forte | Moyenne |
|---|---|---|---|
| Genre | |||
| Funk | 2 | 5 | 5 |
| Hip hop | 31 | 63 | 105 |
| Latin | 6 | 77 | 55 |
| Other | 40 | 65 | 40 |
| Pop | 175 | 299 | 345 |
| Rap | 40 | 46 | 115 |
| Rock | 5 | 14 | 12 |
plt.figure(figsize=(14,4))
sns.countplot(x='Genre',hue='NiveauEnergie', data=spotify,palette=colors);
plt.title("Diagramme du niveau d'énergie des genres");

Renseignement
- L'influence du genre de musique sur l'énergie est nettement marqué.
- Pour les genres "Pop","Hip hop" et "Rap" le nombre de chansons le plus élevé concerne les musiques de niveau d'énergie moyen.
- Pour la musique du genre "Latin", le nombre de chanson avec une énergie forte est plus elevé
Principales conclusions de l'analyse des données
- La musique la plus écoutée est quasiment à 50 millions d'écoutes
- Le rapport est de 1 à 10 entre la musique la plus écoutée et celle la moins écoutée
- Beaucoup de chansons ont un nombre de disciples faible
- Les musiques sont plutôt avec une énergie haute dans l'ensemble.
- Une concentration des valeurs au niveau supérieur pour "Dansabilite", "Energie" et "Positivité".
- On remarque tout de suite les critères faisabilité et énergie ont très fortement la même distribution.
- La variable "Parole" est concentrée sur les valeurs basses pour ces quatre quartiles avec certaines valeurs extrêmes
- L'acoustique est un critère qui occupe toute la longueur du spectre. La positivité est également très étendue
- La concentration des valeurs est très forte au démarrage pour les variables Parole et Acoustique
- Il y a énormément de disparité entre les genres en terme de volume de chansons.
- Les 5 premiers genres représentent plus que 80% des chansons.
- 88% des chansons classées dans le Top Chart 2020-2021 sont sorties entre 2019 et 2021.
- Les musiques dansantes ont donc tendance à être positives
- La dansabilité sera un bon indicateur pour le choisir rapidement les morceaux
- L'indicateur d'intensité semble bien lié à celle de l'énergie.
- Corrélation faible entre disciple et écoute : 0,10
- Corrélation faible entre positivité et dansabilité: 0,36
- Corrélation forte entre intensité et energie:0.73
- Corrélation moyenne et négative entre energie et acoustique:-0,54
- On ne peut pas se baser sur les artistes avec beaucoup de folollers pour garantir l'écoute
- Les genres "Hip hop" et "Rap" ont une distribution plus large que les autres
- Très forte popularité du genre "Pop"
- L'influence du genre de musique sur l'énergie est nettement marqué.
- Pour les genres "Pop, Hip hop" et "Rap" le nombre de chansons le plus élevé concerne les musiques de niveau d'énergie moyen.
- Pour la musique du genre "Latin", le nombre de chanson avec une énergie forte est plus élevé
Deuxième partie :Visualisation des données avec POWER BI
Définition des indicateurs de performances (KPI)
Les indicateurs de performance définis dans le cadres de ce projet sont:
- Le nombre de musiques contenu dans le jeu de données
- Le nombre d'artistes
- Le nombre d'écoutes
- Le nombre de disciples
Définition des rapports requis
Les rapports requis dans le cadres de ce projet sont:
- Le rapport des écoutes par trimestre et par genre
- Le rapport des écoutes par niveau de popularité et genre
- Le rapport des ecoutes par énergie et genre
- Le rapport des écoutes par artiste
- Le rapport des chansons par artiste
- Le rapport des abonnés par artiste
- Le rapport des abonnés par genre
- Le rapport du nombre de musiques par mois d'ecoute
- Le rapport du nombre de musiques par année de sortie
- Le rapport des écoutes par mois et par genre
- L'évolution des écoutes par année et trimestre
- La répartition des écoutes par genre de musique
- La popularité par genre de musique
- La répartition des chanssons par genre
Création des mesures et des colonnes calculées avec le langage DAX


Création des rapports
Rapport des écoutes par trimestre et par genre

Rapport des écoutes par niveau de popularité et genre

Rapport des écoutes par énergie et genre

Rapport des écoutes par artiste

Rapport des chansons par artiste

Rapport des abonnés par artiste

Rapport des abonnés par genre

Rapport du nombre de musiques par mois d'ecoute

Rapport des écoutes par mois et par genre

Rapport des écoutes par popularité,positivité,intensité et rythme

Rapport des ecoutes par niveau acoustique,dansabilité, durée et énergie


Publication des rapports sur Power BI Service
Création du tableau de bord

Création du tableau de bord pour appareils mobiles
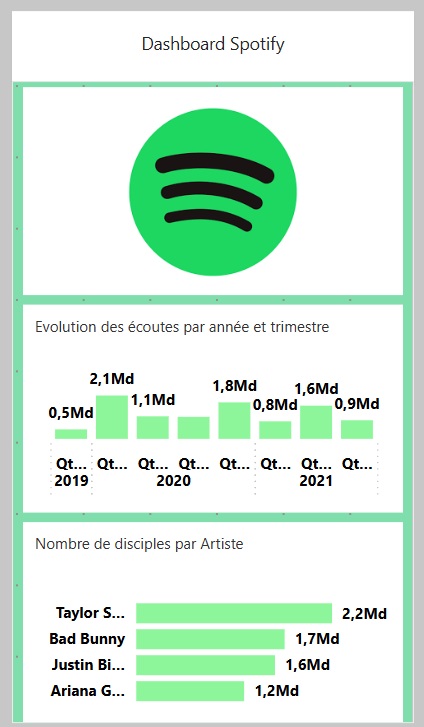
Création de l'application
