Projet: Analyse, Exploration et Visaulisation des données de NETFLIX
Réalisation:Haral Valcourt
Présentation du projet
Le projet consiste à analyser et visualiser un jeu de données de NETFLIX, cette entreprise spécialisée dans la distribution et l'exploitation d'œuvres cinématographiques pour traiter les différents aspects d'un projet d'analyse de données. Dans le cadre de ce projet, on va explorer la façon dont les langages SQL, PLSQL et PYTHON s'intègrent à chaque étape du cycle de vie de l'analyse des données. Dans un premier temps, on va voir comment collecter, nettoyer et analyser des données avec les langages PLSQL et SQL d'Oracle. Dans un deuxième temps, on reprendra les mêmes étapes avec la librairie PANDAS du langage Python. De plus, les librairies Matplotlib et Seaborn seront utilisés pour visualiser les données. En fin, des rapports seront réalisés avec Power BI Desktop puis un tableau de bord et une application seront réalisés avec Power BI Service de Microsoft. Le projet comprend les parties principales suivantes:
- Collecte, Nettoyage, Modélisation et Exploration des donnés avec SQL et PL/SQL;
- Collecte, Nettoyage, Modélisation, Exploration et Analyse des donnés avec Pandas et Seaborn;
- Conception des rapports avec Power BI Desktop.
- Publication des rapports de Power BI Desktop vers Power BI Service.
- Conception du tableau de bord et de l'application avec Power BI Service.
La démarche suivante sera appliquée:
- Les outils technologiques
- Le jeu de données
- La présentation du jeu des données
- La compréhension des données
- L'importation des librairies
- Le traitement des données avec pls/ql et sql;
- Le traitement des données avec pandas
- L'analyse des données avec pandas;
- La visualisation des données avec Power BI desktop et Power BI Service.
Outils technologiques
Les outils suivants sont utilisés pour l'implémentation du projet:
- Le SGBD Oracle 19C
- les langages Python, SQL, PL/SQL
- Le Framework Oracle SQL Developer
- Le logiciel Power BI Desktop
- La plateforme Power BI Service
Jeu de données
Le dataset "Titres Netflix", disponible sur Kaggle.com, est une compilation exhaustive de films et de séries télévisées disponibles sur Netflix, couvrant divers aspects tels que le type de titre, le réalisateur, les acteurs, le pays de production, l'année de sortie, la classification, la durée, les genres et une brève description. Ce dataset est essentiel pour analyser les tendances du contenu de Netflix, comprendre la popularité des genres et examiner la distribution du contenu à travers différentes régions et périodes. Pour les besoins du projet, un fichier relatif au budget a été constitué.
Compréhension des données
Le jeu de données est constitué des colonnes suivantes:
- show_id : Un identifiant unique pour chaque titre.
- type : La catégorie du titre, qui peut être 'Film' ou 'Série télévisée'.
- title : Le nom du film ou de la série télévisée.
- director : Le(s) réalisateur(s) du film ou de la série télévisée.
- cast : La liste des acteurs principaux du titre.
- country : Le pays ou les pays où le film ou la série télévisée a été produit.
- date_added : La date à laquelle le titre a été ajouté à Netflix.
- release_year : L'année de sortie originale du film ou de la série télévisée.
- rating : La classification par âge du titre.
- duration : La durée du titre, en minutes pour les films et en saisons pour les séries télévisées.
- listed_in : Les genres auxquels appartient le titre.
- description : Un bref résumé du titre.
Description des valeurs de la classification du show
- TV-MA: Ce programme est spécifiquement conçu pour être visionné par des adultes.
- TV-14: Cette émission contient des passages inadaptés aux enfants de moins de 14 ans.
- TV-PG: Cette émission contient des éléments inadaptés aux jeunes enfants.
- R: Les moins de 17 ans doivent être accompagnés d'un parent ou d'un tuteur adulte.
- PG-13 : Certains contenus peuvent être inappropriés pour les enfants de moins de 13 ans
- NR ou UR: Indique si un film n'a pas été soumis pour évaluation
- PG: Certains contenus ne conviennent pas aux enfants
- TV-Y7: Ce programme est conçu pour les enfants de 7 ans et plus
- TV-G: Ce programme convient à tous les âges
- TV-Y: Ce programme convient aux enfants y compris ceux âgés entre 2 et 6 ans
- TV-Y7-FV: Ce programme est recommandé pour les 7 ans et plus
- G: Tous les âges sont admis
- NC-17: Programme conçu exclusivement pour les adultes
Importation des librairies
import sys
import oracledb
import os
import pyodbc
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from scipy import stats
import pandasql as ps
import cx_Oracle
import sqlalchemy
from sqlalchemy.exc import SQLAlchemyError
Configuration de base
sns.set_context("paper", font_scale=0.9)
colors = ['#ff9999','#66b3ff','#99ff99','#ffcc99','#FFC1C1']
couleur = ["#FF4040","#FF1493","#FF7D40","#B22222","#C71585","#EE82EE","#FF3030","#FF7D40","#D02090"]
from warnings import filterwarnings
filterwarnings('ignore')
PREMIERE PARTIE: ORACLE SQL et PL/SQL
Collecte, Nettoyage, Modelisation et Exploration des donnés avec PLSQL & SQL
Cette partie est consacrée à l'utilisation des langages PLSQL et SQL. Elle comprend les sections suivantes:
- Collecter les données;
- Explorer les données;
- Nettoyer les données;
- Modéliser les données;
- exploiter les données.
Collection des données
Connexion à la base de données Oracle
conn = oracledb.connect(user="system", password="halrald", dsn="localhost/orcl")
cur= conn.cursor()
Suppression des tables existantes
cur.execute("drop table DATEAJOUT");
cur.execute("drop table LISTE_ACTEUR");
cur.execute("drop table LISTE_PAYS");
cur.execute("drop table LISTE_GENRE");
cur.execute("drop table BUDGET");
cur.execute("drop table NETFLIX");
print('Tables supprimées')
Tables supprimées
Lecture et chargement des données du fichier netflix.csv
data= pd.read_csv('netflix.csv', encoding='latin1')
engine = sqlalchemy.create_engine("oracle+cx_oracle://system:halrald@localhost/?service_name=orcl")
data.to_sql('NETFLIX',engine)
print('Données chargées dans la table')
Données chargées dans la table
Lecture et chargement des données du fichier budget.csv
data= pd.read_csv('budget.csv')
engine = sqlalchemy.create_engine("oracle+cx_oracle://system:halrald@localhost/?service_name=orcl")
data.to_sql('BUDGET',engine)
print('Données chargées dans la table')
Données chargées dans la table
Exploration des donnés
Afficher de la structure de la table Festival
query="select column_name,data_type, data_length from user_tab_columns where table_name='NETFLIX' ";
df = pd.read_sql(query, conn)
df
| COLUMN_NAME | DATA_TYPE | DATA_LENGTH | |
|---|---|---|---|
| 0 | index | NUMBER | 22 |
| 1 | SHOW_ID | CLOB | 4000 |
| 2 | TYPE | CLOB | 4000 |
| 3 | TITLE | CLOB | 4000 |
| 4 | DIRECTOR | CLOB | 4000 |
| 5 | CAST | CLOB | 4000 |
| 6 | COUNTRY | CLOB | 4000 |
| 7 | DATE_ADDED | CLOB | 4000 |
| 8 | RELEASE_YEAR | NUMBER | 22 |
| 9 | RATING | CLOB | 4000 |
| 10 | DURATION | CLOB | 4000 |
| 11 | LISTED_IN | CLOB | 4000 |
| 12 | DESCRIPTION | CLOB | 4000 |
Renommer et modifier les types de données de la table Festival
query="select column_name,data_type, data_length from user_tab_columns where table_name='NETFLIX' ";
df = pd.read_sql(query, conn)
df
| COLUMN_NAME | DATA_TYPE | DATA_LENGTH | |
|---|---|---|---|
| 0 | index | NUMBER | 22 |
| 1 | SHOW_ID | CLOB | 4000 |
| 2 | TYPE | CLOB | 4000 |
| 3 | TITLE | CLOB | 4000 |
| 4 | DIRECTOR | CLOB | 4000 |
| 5 | CAST | CLOB | 4000 |
| 6 | COUNTRY | CLOB | 4000 |
| 7 | DATE_ADDED | CLOB | 4000 |
| 8 | RELEASE_YEAR | NUMBER | 22 |
| 9 | RATING | CLOB | 4000 |
| 10 | DURATION | CLOB | 4000 |
| 11 | LISTED_IN | CLOB | 4000 |
| 12 | DESCRIPTION | CLOB | 4000 |
cur.execute("ALTER TABLE NETFLIX ADD SHOWID VARCHAR2(10)");
cur.execute("UPDATE NETFLIX SET SHOWID=SHOW_ID");
cur.execute("ALTER TABLE NETFLIX DROP COLUMN SHOW_ID");
cur.execute("ALTER TABLE NETFLIX ADD TYPES VARCHAR2(20)");
cur.execute("UPDATE NETFLIX SET TYPES=TYPE");
cur.execute("ALTER TABLE NETFLIX DROP COLUMN TYPE");
cur.execute("ALTER TABLE NETFLIX ADD TITRE VARCHAR2(250)");
cur.execute("UPDATE NETFLIX SET TITRE=TITLE");
cur.execute("ALTER TABLE NETFLIX DROP COLUMN TITLE");
cur.execute("ALTER TABLE NETFLIX ADD DIRECTEUR VARCHAR2(250)");
cur.execute("UPDATE NETFLIX SET DIRECTEUR=DIRECTOR");
cur.execute("ALTER TABLE NETFLIX ADD ACTEUR VARCHAR2(800)");
cur.execute("UPDATE NETFLIX SET ACTEUR=CAST");
cur.execute("ALTER TABLE NETFLIX ADD PAYS VARCHAR2(200)");
cur.execute("UPDATE NETFLIX SET PAYS=COUNTRY");
cur.execute("ALTER TABLE NETFLIX ADD DATES VARCHAR2(30)");
cur.execute("UPDATE NETFLIX SET DATES=DATE_ADDED");
cur.execute("ALTER TABLE NETFLIX DROP COLUMN DATE_ADDED");
cur.execute("ALTER TABLE NETFLIX ADD ANNEE_SORTIE NUMBER(5)");
cur.execute("UPDATE NETFLIX SET ANNEE_SORTIE=RELEASE_YEAR");
cur.execute("ALTER TABLE NETFLIX DROP COLUMN RELEASE_YEAR");
cur.execute("ALTER TABLE NETFLIX ADD NOTATION VARCHAR2(10)");
cur.execute("UPDATE NETFLIX SET NOTATION=RATING");
cur.execute("ALTER TABLE NETFLIX DROP COLUMN RATING");
cur.execute("ALTER TABLE NETFLIX ADD DUREE VARCHAR2(20)");
cur.execute("UPDATE NETFLIX SET DUREE=DURATION");
cur.execute("ALTER TABLE NETFLIX DROP COLUMN DURATION");
cur.execute("ALTER TABLE NETFLIX ADD GENRE VARCHAR2(400)");
cur.execute("UPDATE NETFLIX SET GENRE=LISTED_IN");
cur.execute("ALTER TABLE NETFLIX ADD DESCRIPTIONS VARCHAR2(1000)");
cur.execute("UPDATE NETFLIX SET DESCRIPTIONS=DESCRIPTION");
cur.execute("ALTER TABLE NETFLIX DROP COLUMN DESCRIPTION");
Afficher de la structure de la table Festival
query="select column_name,data_type, data_length from user_tab_columns where table_name='NETFLIX' ";
df = pd.read_sql(query, conn)
df
| COLUMN_NAME | DATA_TYPE | DATA_LENGTH | |
|---|---|---|---|
| 0 | index | NUMBER | 22 |
| 1 | TYPES | VARCHAR2 | 20 |
| 2 | TITRE | VARCHAR2 | 250 |
| 3 | DIRECTEUR | VARCHAR2 | 250 |
| 4 | DIRECTOR | CLOB | 4000 |
| 5 | CAST | CLOB | 4000 |
| 6 | COUNTRY | CLOB | 4000 |
| 7 | ANNEE_SORTIE | NUMBER | 22 |
| 8 | NOTATION | VARCHAR2 | 10 |
| 9 | DUREE | VARCHAR2 | 20 |
| 10 | GENRE | VARCHAR2 | 400 |
| 11 | LISTED_IN | CLOB | 4000 |
| 12 | SHOWID | VARCHAR2 | 10 |
| 13 | ACTEUR | VARCHAR2 | 800 |
| 14 | PAYS | VARCHAR2 | 200 |
| 15 | DATES | VARCHAR2 | 30 |
| 16 | DESCRIPTIONS | VARCHAR2 | 1000 |
Afficher les 5 premières lignes de la table NETFLIX
query=" SELECT* FROM NETFLIX WHERE SHOWID IN (SELECT SHOWID FROM NETFLIX WHERE ROWNUM BETWEEN 1 AND 5)";
df = pd.read_sql(query, conn)
df
| index | DIRECTOR | CAST | COUNTRY | LISTED_IN | SHOWID | TYPES | TITRE | DIRECTEUR | ACTEUR | PAYS | DATES | ANNEE_SORTIE | NOTATION | DUREE | GENRE | DESCRIPTIONS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | Kirsten Johnson | None | United States | Documentaries | s1 | Movie | Dick Johnson Is Dead | Kirsten Johnson | None | United States | 25-Sep-21 | 2020 | PG-13 | 90 min | Documentaries | As her father nears the end of his life, filmm... |
| 1 | 1 | None | Ama Qamata, Khosi Ngema, Gail Mabalane, Thaban... | South Africa | International TV Shows, TV Dramas, TV Mysteries | s2 | TV Show | Blood & Water | None | Ama Qamata, Khosi Ngema, Gail Mabalane, Thaban... | South Africa | 24-Sep-21 | 2021 | TV-MA | 2 Seasons | International TV Shows, TV Dramas, TV Mysteries | After crossing paths at a party, a Cape Town t... |
| 2 | 2 | Julien Leclercq | Sami Bouajila, Tracy Gotoas, Samuel Jouy, Nabi... | None | Crime TV Shows, International TV Shows, TV Act... | s3 | TV Show | Ganglands | Julien Leclercq | Sami Bouajila, Tracy Gotoas, Samuel Jouy, Nabi... | None | 24-Sep-21 | 2021 | TV-MA | 1 Season | Crime TV Shows, International TV Shows, TV Act... | To protect his family from a powerful drug lor... |
| 3 | 3 | None | None | None | Docuseries, Reality TV | s4 | TV Show | Jailbirds New Orleans | None | None | None | 24-Sep-21 | 2021 | TV-MA | 1 Season | Docuseries, Reality TV | Feuds, flirtations and toilet talk go down amo... |
| 4 | 4 | None | Mayur More, Jitendra Kumar, Ranjan Raj, Alam K... | India | International TV Shows, Romantic TV Shows, TV ... | s5 | TV Show | Kota Factory | None | Mayur More, Jitendra Kumar, Ranjan Raj, Alam K... | India | 24-Sep-21 | 2021 | TV-MA | 2 Seasons | International TV Shows, Romantic TV Shows, TV ... | In a city of coaching centers known to train I... |
Afficher la structure de la table Budget
query="select column_name,data_type, data_length from user_tab_columns where table_name='BUDGET' ";
df = pd.read_sql(query, conn)
df
| COLUMN_NAME | DATA_TYPE | DATA_LENGTH | |
|---|---|---|---|
| 0 | index | NUMBER | 22 |
| 1 | SHOW_ID | CLOB | 4000 |
| 2 | COMPANY | CLOB | 4000 |
| 3 | BUDGETS | NUMBER | 22 |
Renommer et modifier les types de données de la table Budget
cur.execute("ALTER TABLE BUDGET ADD SHOWID VARCHAR2(10)");
cur.execute("UPDATE BUDGET SET SHOWID=SHOW_ID");
cur.execute("ALTER TABLE BUDGET DROP COLUMN SHOW_ID");
cur.execute("ALTER TABLE BUDGET ADD COMPAGNIE VARCHAR2(50)");
cur.execute("UPDATE BUDGET SET COMPAGNIE=company");
cur.execute("ALTER TABLE BUDGET DROP COLUMN company");
cur.execute("ALTER TABLE BUDGET ADD COUT NUMBER(15)");
cur.execute("UPDATE BUDGET SET COUT=BUDGETS");
cur.execute("ALTER TABLE BUDGET DROP COLUMN BUDGETS");
Afficher la structure de la table Budget
query="select column_name,data_type, data_length from user_tab_columns where table_name='BUDGET' ";
df = pd.read_sql(query, conn)
df
| COLUMN_NAME | DATA_TYPE | DATA_LENGTH | |
|---|---|---|---|
| 0 | SHOWID | VARCHAR2 | 10 |
| 1 | index | NUMBER | 22 |
| 2 | COMPAGNIE | VARCHAR2 | 50 |
| 3 | COUT | NUMBER | 22 |
Identifier le nombre de valeurs nulles des colonnes
query="select directeur , count(*) ValeurNulle from netflix where directeur is null group by directeur";
df=pd.read_sql(query,conn)
df
| DIRECTEUR | VALEURNULLE | |
|---|---|---|
| 0 | None | 2634 |
query="select acteur, count(*) ValeurNulle from netflix where acteur is null group by acteur"
df=pd.read_sql(query,conn)
df
| ACTEUR | VALEURNULLE | |
|---|---|---|
| 0 | None | 825 |
query="select pays, count(*) nullvalue from netflix where pays is null group by pays";
df=pd.read_sql(query,conn)
df
| PAYS | NULLVALUE | |
|---|---|---|
| 0 | None | 831 |
query="select dates, count(*) nullvalue from netflix where dates is null group by dates";
df=pd.read_sql(query,conn)
df
| DATES | NULLVALUE | |
|---|---|---|
| 0 | None | 10 |
query="select notation, count(*) nullvalue from netflix where notation is null group by notation";
df=pd.read_sql(query,conn)
df
| NOTATION | NULLVALUE | |
|---|---|---|
| 0 | None | 4 |
query="select duree, count(*) nullvalue from netflix where duree is null group by duree";
df=pd.read_sql(query,conn)
df
| DUREE | NULLVALUE | |
|---|---|---|
| 0 | None | 3 |
Identifier les doublons
query="""
select count(*) quantite, types, titre, directeur, acteur, pays, dates,annee_sortie, notation, genre, descriptions, duree
from netflix
group by types, titre, directeur, acteur, pays, dates,annee_sortie, notation, genre, descriptions, duree
having count(*)>1
"""
df=pd.read_sql(query,conn)
df
| QUANTITE | TYPES | TITRE | DIRECTEUR | ACTEUR | PAYS | DATES | ANNEE_SORTIE | NOTATION | GENRE | DESCRIPTIONS | DUREE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | Movie | 22-Jul | Paul Greengrass | Anders Danielsen Lie, Jon Ãigarden, Jonas Str... | Norway, Iceland, United States | 10-Oct-18 | 2018 | R | Dramas, Thrillers | After devastating terror attacks in Norway, a ... | 144 min |
| 1 | 2 | Movie | 15-Aug | Swapnaneel Jayakar | Rahul Pethe, Mrunmayee Deshpande, Adinath Koth... | India | 29-Mar-19 | 2019 | TV-14 | Comedies, Dramas, Independent Movies | On India's Independence Day, a zany mishap in ... | 124 min |
| 2 | 2 | TV Show | 9-Feb | None | Shahd El Yaseen, Shaila Sabt, Hala, Hanadi Al-... | None | 20-Mar-19 | 2018 | TV-14 | International TV Shows, TV Dramas | As a psychology professor faces Alzheimer's, h... | 1 Season |
Nettoyage des données
Remplacer des valeurs nulles des colonnes "direteur" ,"acteur","pays" par "Inconnu"
cur.execute("UPDATE NETFLIX SET DIRECTEUR ='Inconnu' WHERE DIRECTEUR IS NULL");
cur.execute("UPDATE NETFLIX SET ACTEUR='Inconnu' WHERE ACTEUR IS NULL");
cur.execute("UPDATE NETFLIX SET PAYS='Inconnu' WHERE PAYS IS NULL");
Supprimer les lignes pour lesquelles la date, la notation et la durée ne sont pas rensignées
cur.execute("DELETE FROM NETFLIX WHERE DATES IS NULL");
cur.execute("DELETE FROM NETFLIX WHERE NOTATION IS NULL");
cur.execute("DELETE FROM NETFLIX WHERE NOTATION IS NULL");
Eliminer les doublons
query="""
select* from NETFLIX WHERE TITRE IN(
select titre from (
select count(*) quantite, types, titre, directeur, acteur, pays, dates,annee_sortie, notation, genre, descriptions, duree
from netflix
group by types, titre, directeur, acteur, pays, dates,annee_sortie, notation, genre, descriptions, duree
having count(*)>1)
) ORDER BY TITRE
"""
df=pd.read_sql(query,conn)
df
| index | DIRECTOR | CAST | COUNTRY | LISTED_IN | SHOWID | TYPES | TITRE | DIRECTEUR | ACTEUR | PAYS | DATES | ANNEE_SORTIE | NOTATION | DUREE | GENRE | DESCRIPTIONS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3962 | Swapnaneel Jayakar | Rahul Pethe, Mrunmayee Deshpande, Adinath Koth... | India | Comedies, Dramas, Independent Movies | s3963 | Movie | 15-Aug | Swapnaneel Jayakar | Rahul Pethe, Mrunmayee Deshpande, Adinath Koth... | India | 29-Mar-19 | 2019 | TV-14 | 124 min | Comedies, Dramas, Independent Movies | On India's Independence Day, a zany mishap in ... |
| 1 | 5966 | Swapnaneel Jayakar | Rahul Pethe, Mrunmayee Deshpande, Adinath Koth... | India | Comedies, Dramas, Independent Movies | s5967 | Movie | 15-Aug | Swapnaneel Jayakar | Rahul Pethe, Mrunmayee Deshpande, Adinath Koth... | India | 29-Mar-19 | 2019 | TV-14 | 124 min | Comedies, Dramas, Independent Movies | On India's Independence Day, a zany mishap in ... |
| 2 | 4522 | Paul Greengrass | Anders Danielsen Lie, Jon Ãigarden, Jonas Str... | Norway, Iceland, United States | Dramas, Thrillers | s4523 | Movie | 22-Jul | Paul Greengrass | Anders Danielsen Lie, Jon Ãigarden, Jonas Str... | Norway, Iceland, United States | 10-Oct-18 | 2018 | R | 144 min | Dramas, Thrillers | After devastating terror attacks in Norway, a ... |
| 3 | 5965 | Paul Greengrass | Anders Danielsen Lie, Jon Ãigarden, Jonas Str... | Norway, Iceland, United States | Dramas, Thrillers | s5966 | Movie | 22-Jul | Paul Greengrass | Anders Danielsen Lie, Jon Ãigarden, Jonas Str... | Norway, Iceland, United States | 10-Oct-18 | 2018 | R | 144 min | Dramas, Thrillers | After devastating terror attacks in Norway, a ... |
| 4 | 3996 | None | Shahd El Yaseen, Shaila Sabt, Hala, Hanadi Al-... | None | International TV Shows, TV Dramas | s3997 | TV Show | 9-Feb | Inconnu | Shahd El Yaseen, Shaila Sabt, Hala, Hanadi Al-... | Inconnu | 20-Mar-19 | 2018 | TV-14 | 1 Season | International TV Shows, TV Dramas | As a psychology professor faces Alzheimer's, h... |
| 5 | 5964 | None | Shahd El Yaseen, Shaila Sabt, Hala, Hanadi Al-... | None | International TV Shows, TV Dramas | s5965 | TV Show | 9-Feb | Inconnu | Shahd El Yaseen, Shaila Sabt, Hala, Hanadi Al-... | Inconnu | 20-Mar-19 | 2018 | TV-14 | 1 Season | International TV Shows, TV Dramas | As a psychology professor faces Alzheimer's, h... |
cur.execute("DELETE FROM NETFLIX WHERE SHOWID IN ('s3963','s5966','s5965')");
Modélisation des données
Ajouter une clé primaire à la table NETFLIX
query="ALTER TABLE NETFLIX ADD CONSTRAINT PK_NETFLIX PRIMARY KEY (SHOWID)";
cur.execute(query)
print('Contrainte ajoutée')
Contrainte ajoutée
query=" SELECT CONSTRAINT_NAME, CONSTRAINT_TYPE, STATUS FROM USER_CONSTRAINTS WHERE TABLE_NAME='NETFLIX' ";
df = pd.read_sql(query, conn)
df
| CONSTRAINT_NAME | CONSTRAINT_TYPE | STATUS | |
|---|---|---|---|
| 0 | PK_NETFLIX | P | ENABLED |
Ajouter une clé primaire à la table BUDGET
query="ALTER TABLE BUDGET ADD CONSTRAINT PK_BUDGET PRIMARY KEY (SHOWID)";
cur.execute(query)
print('Contrainte ajoutée')
Contrainte ajoutée
Ajouter une clé étrangère à la table BUDGET
query="DELETE FROM BUDGET WHERE SHOWID NOT IN(SELECT SHOWID FROM NETFLIX)";
cur.execute(query)
query="ALTER TABLE BUDGET ADD CONSTRAINT FK_BUDGET_NETFLIX FOREIGN KEY (SHOWID) REFERENCES NETFLIX(SHOWID)";
cur.execute(query)
print('Contrainte ajoutée')
Contrainte ajoutée
Afficher les informations sur les clé primaires et clés étrangères associées aux tables de NETFLIX et BUDGET
query="""
SELECT TABLE_NAME NOMTABLE,
CONSTRAINT_NAME NOM_CONTRAINTE,
CONSTRAINT_TYPE TYPE_CONTRAINTE,
STATUS STATUT_CONTRAINT
FROM USER_CONSTRAINTS
WHERE TABLE_NAME IN('NETFLIX','BUDGET')
""";
df = pd.read_sql(query, conn)
df
| NOMTABLE | NOM_CONTRAINTE | TYPE_CONTRAINTE | STATUT_CONTRAINT | |
|---|---|---|---|---|
| 0 | NETFLIX | PK_NETFLIX | P | ENABLED |
| 1 | BUDGET | PK_BUDGET | P | ENABLED |
| 2 | BUDGET | FK_BUDGET_NETFLIX | R | ENABLED |
Ajouter une nouvelle colonne DATE_AJOUT à la table NETFLIX
query="ALTER TABLE NETFLIX ADD DATE_AJOUT DATE";
cur.execute(query)
print('Colonne ajoutée')
Colonne ajoutée
Mettre à jour la colonne DATE_AJOUT à partir de la colonne DATES
query="UPDATE NETFLIX SET DATE_AJOUT=TO_DATE(DATES, 'MONTH DD, YYYY ') WHERE LENGTH(DATES)>9";
cur.execute(query)
query="UPDATE NETFLIX SET DATE_AJOUT=TO_DATE(DATES, 'DD-MON-YY ') WHERE LENGTH(DATES)<=9";
cur.execute(query)
print('Mise à jour effectuée')
Mise à jour effectuée
Ajouter une colonne MOIS_AJOUT à la table NETFLIX
query="ALTER TABLE NETFLIX ADD MOIS_AJOUT VARCHAR(5)";
cur.execute(query)
print('Colonne ajoutée')
Colonne ajoutée
Traiter la colonne "DUREE"
query=" SELECT TYPES,DUREE FROM NETFLIX WHERE SHOWID IN (SELECT SHOWID FROM NETFLIX WHERE ROWNUM BETWEEN 1 AND 5)";
df = pd.read_sql(query, conn)
df
| TYPES | DUREE | |
|---|---|---|
| 0 | Movie | 90 min |
| 1 | Movie | 126 min |
| 2 | Movie | 116 min |
| 3 | Movie | 104 min |
| 4 | TV Show | 1 Season |
Créer deux nouvelles colonnes "DUREE_FILM" et "DUREE_SERIE"
cur.execute("ALTER TABLE NETFLIX ADD DUREE_FILM VARCHAR(10)")
cur.execute("ALTER TABLE NETFLIX ADD DUREE_SERIE VARCHAR(10)")
print('Colonne ajoutée et mise à jour effectuée')
Colonne ajoutée et mise à jour effectuée
Créer une procedure PLSQL pour remplir les colonnes "DUREE_FILM" et "DUREE_SERIE" en fonction de la colonne "DUREE"
query="""
CREATE OR REPLACE PROCEDURE UPDDUREE
AS
BEGIN
FOR UNSHOW IN(SELECT SHOWID, DUREE FROM NETFLIX)
LOOP
UPDATE NETFLIX SET DUREE_FILM=REPLACE(UNSHOW.DUREE,'min','') WHERE showid=UNSHOW.SHOWID AND TYPES='Movie';
UPDATE NETFLIX SET DUREE_SERIE=UNSHOW.DUREE WHERE showid=UNSHOW.SHOWID AND TYPES='TV Show';
END LOOP;
UPDATE NETFLIX SET DUREE_FILM=0 WHERE TYPES='TV Show';
UPDATE NETFLIX SET DUREE_SERIE=0 WHERE TYPES='Movie';
END;
"""
cur.execute(query)
cur.callproc("UPDDUREE");
print('procédure créée et executée')
query=" SELECT SHOWID,DUREE,DUREE_FILM,DUREE_SERIE FROM NETFLIX WHERE SHOWID IN (SELECT SHOWID FROM NETFLIX WHERE ROWNUM BETWEEN 1 AND 10)";
df = pd.read_sql(query, conn)
df
procédure créée et executée
| SHOWID | DUREE | DUREE_FILM | DUREE_SERIE | |
|---|---|---|---|---|
| 0 | s1 | 90 min | 90 | 0 |
| 1 | s1001 | 126 min | 126 | 0 |
| 2 | s1002 | 86 min | 86 | 0 |
| 3 | s1003 | 97 min | 97 | 0 |
| 4 | s1000 | 116 min | 116 | 0 |
| 5 | s10 | 104 min | 104 | 0 |
| 6 | s100 | 1 Season | 0 | 1 Season |
| 7 | s1005 | 2 Seasons | 0 | 2 Seasons |
| 8 | s1006 | 76 min | 76 | 0 |
| 9 | s1004 | 1 Season | 0 | 1 Season |
Traiter la colonne "Pays"
query=" SELECT SHOWID,PAYS FROM NETFLIX WHERE SHOWID IN (SELECT SHOWID FROM NETFLIX WHERE ROWNUM BETWEEN 1 AND 10)";
df = pd.read_sql(query, conn)
df
| SHOWID | PAYS | |
|---|---|---|
| 0 | s1 | United States |
| 1 | s1001 | Inconnu |
| 2 | s1002 | Canada, Nigeria, United States |
| 3 | s1003 | Mexico |
| 4 | s1000 | Germany, United States |
| 5 | s10 | United States |
| 6 | s100 | France, United States |
| 7 | s1005 | Australia |
| 8 | s1006 | Inconnu |
| 9 | s1004 | Italy |
Créer une table "LISTE_PAYS" pour contenir les pays de chaque show
cur.execute("CREATE TABLE LISTE_PAYS(SHOWID VARCHAR(15), PAYS VARCHAR(40)) ");
print('Table créée')
Table créée
Créer une procédure pour séparer les pays et remplir la table "LISTE_PAYS"
query="""
CREATE OR REPLACE PROCEDURE LISTE_PAYS_SHOW
AS
delimiter CHAR := ',';
debut NUMBER := 1;
fin NUMBER;
item VARCHAR2(255);
BEGIN
FOR ligne IN (SELECT showid, pays FROM netflix) LOOP
debut := 1;
LOOP
fin:= INSTR(ligne.pays, delimiter, debut);
IF fin= 0 THEN
item := SUBSTR(ligne.pays, debut);
EXIT;
END IF;
item := SUBSTR(ligne.pays, debut, fin - debut);
INSERT INTO LISTE_PAYS VALUES(ligne.showid,TRIM(item));
debut := fin + 1;
END LOOP;
END LOOP;
END;
"""
cur.execute(query)
cur.callproc("LISTE_PAYS_SHOW");
print('procédure créée et executée')
query=" SELECT SHOWID,PAYS FROM LISTE_PAYS WHERE SHOWID IN (SELECT SHOWID FROM LISTE_PAYS WHERE ROWNUM BETWEEN 1 AND 10)";
df = pd.read_sql(query, conn)
df
procédure créée et executée
| SHOWID | PAYS | |
|---|---|---|
| 0 | s8 | United States |
| 1 | s8 | Ghana |
| 2 | s8 | Burkina Faso |
| 3 | s8 | United Kingdom |
| 4 | s8 | Germany |
| 5 | s13 | Germany |
| 6 | s30 | United States |
| 7 | s30 | India |
| 8 | s39 | China |
| 9 | s39 | Canada |
Compléter la table LISTE_PAYS
query="""
CREATE OR REPLACE PROCEDURE INSERT_PAYS
AS
BEGIN
FOR UNSHOW IN(select showid, pays from netflix where showid not in(select showid from liste_pays))
LOOP
INSERT INTO LISTE_PAYS VALUES(UNSHOW.SHOWID,UNSHOW.PAYS) ;
END LOOP;
END;
"""
cur.execute(query)
cur.callproc("INSERT_PAYS");
cur.execute("COMMIT");
print('procedure créée et executée')
procedure créée et executée
Analyser les valeurs de la colonne "GENRE"
query=" SELECT SHOWID, GENRE FROM NETFLIX WHERE SHOWID IN (SELECT SHOWID FROM NETFLIX WHERE ROWNUM BETWEEN 1 AND 5)";
df = pd.read_sql(query, conn)
df
| SHOWID | GENRE | |
|---|---|---|
| 0 | s1 | Documentaries |
| 1 | s1001 | Action & Adventure, International Movies |
| 2 | s1000 | Dramas, International Movies, Thrillers |
| 3 | s10 | Comedies, Dramas |
| 4 | s100 | TV Comedies, TV Dramas |
Créer une procédure pour remplacer le caratère "&" par "," dans la table "Netflix"
query="""
CREATE OR REPLACE PROCEDURE UPDGENRE
AS
BEGIN
FOR UNSHOW IN(SELECT SHOWID, GENRE FROM NETFLIX)
LOOP
UPDATE NETFLIX SET GENRE=REPLACE(UNSHOW.GENRE,' & ',',') WHERE showid=UNSHOW.SHOWID ;
END LOOP;
END;
"""
cur.execute(query)
cur.callproc("UPDGENRE");
print('procédure créée et executée')
procédure créée et executée
Creer une table "LISTE_GENRE" pour séparer les genres des shows
cur.execute("CREATE TABLE LISTE_GENRE(SHOWID VARCHAR(15), GENRE VARCHAR(40))");
print('Table créée')
Table créée
Créer une procédure pour séparer les genres des shows et remplir la table "LISTE_GENRE"
query="""
CREATE OR REPLACE PROCEDURE LISTE_GENRE_SHOW
AS
delimiter CHAR := ',';
debut NUMBER := 1;
fin NUMBER;
item VARCHAR2(255);
BEGIN
FOR ligne IN (SELECT showid, genre FROM netflix) LOOP
debut := 1;
LOOP
fin:= INSTR(ligne.genre, delimiter, debut);
IF fin= 0 THEN
item := SUBSTR(ligne.genre, debut);
EXIT;
END IF;
item := SUBSTR(ligne.genre, debut, fin - debut);
INSERT INTO LISTE_GENRE VALUES(ligne.showid,TRIM(item));
debut := fin + 1;
END LOOP;
END LOOP;
END;
"""
cur.execute(query)
cur.callproc("LISTE_GENRE_SHOW");
print('procédure créée et executée')
query=" SELECT SHOWID,GENRE FROM LISTE_GENRE WHERE SHOWID IN (SELECT SHOWID FROM LISTE_GENRE WHERE ROWNUM BETWEEN 1 AND 10)";
df = pd.read_sql(query, conn)
df
procédure créée et executée
| SHOWID | GENRE | |
|---|---|---|
| 0 | s2 | International TV Shows |
| 1 | s2 | TV Dramas |
| 2 | s3 | Crime TV Shows |
| 3 | s3 | International TV Shows |
| 4 | s3 | TV Action |
| 5 | s4 | Docuseries |
| 6 | s5 | International TV Shows |
| 7 | s5 | Romantic TV Shows |
| 8 | s6 | TV Dramas |
| 9 | s6 | TV Horror |
query="""
CREATE OR REPLACE PROCEDURE INSERT_GENRE
AS
BEGIN
FOR UNSHOW IN(select showid, genre from netflix where showid not in(select showid from liste_genre))
LOOP
INSERT INTO LISTE_GENRE VALUES(UNSHOW.SHOWID,UNSHOW.GENRE) ;
END LOOP;
END;
"""
cur.execute(query)
cur.callproc("INSERT_GENRE");
print('procedure créée et executée')
procedure créée et executée
Analyser les valeurs de la colonne "ACTEUR"
query=" SELECT SHOWID, ACTEUR FROM NETFLIX WHERE SHOWID IN (SELECT SHOWID FROM NETFLIX WHERE ROWNUM BETWEEN 1 AND 5)";
df = pd.read_sql(query, conn)
df
| SHOWID | ACTEUR | |
|---|---|---|
| 0 | s1 | Inconnu |
| 1 | s1001 | Nagarjuna Akkineni, Dia Mirza, Saiyami Kher, A... |
| 2 | s1000 | Anna Kendrick, Toni Collette, Daniel Dae Kim, ... |
| 3 | s10 | Melissa McCarthy, Chris O'Dowd, Kevin Kline, T... |
| 4 | s100 | Julie Delpy, Elisabeth Shue, Sarah Jones, Alex... |
Créer une table "LISTE_ACTEUR" pour séparer les acteurs des shows
cur.execute("CREATE TABLE LISTE_ACTEUR(SHOWID VARCHAR(15), ACTEUR VARCHAR(100)) ");
print('Table créée')
Table créée
Créer une procédure pour remplir la table "LISTE_ACTEUR"
query="""
CREATE OR REPLACE PROCEDURE LISTE_ACTEUR_SHOW
AS
delimiter CHAR := ',';
debut NUMBER := 1;
fin NUMBER;
item VARCHAR2(255);
BEGIN
FOR ligne IN (SELECT showid, acteur FROM netflix) LOOP
debut := 1;
LOOP
fin:= INSTR(ligne.acteur, delimiter, debut);
IF fin= 0 THEN
item := SUBSTR(ligne.acteur, debut);
EXIT;
END IF;
item := SUBSTR(ligne.acteur, debut, fin - debut);
INSERT INTO LISTE_ACTEUR VALUES(ligne.showid,TRIM(item));
debut := fin + 1;
END LOOP;
END LOOP;
END;
"""
cur.execute(query)
cur.callproc("LISTE_ACTEUR_SHOW");
print('procédure créée et executée')
query=" SELECT SHOWID,ACTEUR FROM LISTE_ACTEUR WHERE SHOWID IN (SELECT SHOWID FROM LISTE_ACTEUR WHERE ROWNUM BETWEEN 1 AND 10)";
df = pd.read_sql(query, conn)
df
procédure créée et executée
| SHOWID | ACTEUR | |
|---|---|---|
| 0 | s2 | Ama Qamata |
| 1 | s2 | Khosi Ngema |
| 2 | s2 | Gail Mabalane |
| 3 | s2 | Thabang Molaba |
| 4 | s2 | Dillon Windvogel |
| 5 | s2 | Natasha Thahane |
| 6 | s2 | Arno Greeff |
| 7 | s2 | Xolile Tshabalala |
| 8 | s2 | Getmore Sithole |
| 9 | s2 | Cindy Mahlangu |
| 10 | s2 | Ryle De Morny |
| 11 | s2 | Greteli Fincham |
| 12 | s2 | Sello Maake Ka-Ncube |
| 13 | s2 | Odwa Gwanya |
| 14 | s2 | Mekaila Mathys |
| 15 | s2 | Sandi Schultz |
| 16 | s2 | Duane Williams |
| 17 | s2 | Shamilla Miller |
Compléter la table LISTE_ACTEUR
query="""
CREATE OR REPLACE PROCEDURE INSERT_ACTEUR
AS
BEGIN
FOR UNSHOW IN(select showid, acteur from netflix where showid not in(select showid from liste_acteur))
LOOP
INSERT INTO LISTE_ACTEUR VALUES(UNSHOW.SHOWID,UNSHOW.ACTEUR) ;
END LOOP;
END;
"""
cur.execute(query)
cur.callproc("INSERT_ACTEUR");
cur.execute("COMMIT");
print('procédure créée et executée')
procédure créée et executée
Identifier les doublons au niveau des tables "LISTE_PAYS", "LISTE_GENRE" et "LISTE_ACTEUR"
query="select showid,acteur, count(*) from liste_acteur group by showid,acteur having count(*)>1";
df = pd.read_sql(query, conn)
df
| SHOWID | ACTEUR | COUNT(*) | |
|---|---|---|---|
| 0 | s1632 | Micah Hauptman | 2 |
| 1 | s6014 | Adrianna BiedrzyÅska | 2 |
query="select showid,genre, count(*) from liste_genre group by showid,genre having count(*)>1";
df = pd.read_sql(query, conn)
df
| SHOWID | GENRE | COUNT(*) |
|---|
query="select showid,pays, count(*) from liste_pays group by showid,pays having count(*)>1";
df = pd.read_sql(query, conn)
df
| SHOWID | PAYS | COUNT(*) |
|---|
Supprimer les doublons de la table "LISTE_ACTEUR"
query="""
delete from liste_acteur where (showid,acteur) in (
select showid,acteur from liste_acteur
group by showid,acteur
having count(*)>1)
""";
cur.execute(query);
print('Doublons supprimés')
Doublons supprimés
Ajouter les clés primaires et clés etrangères aux tables "LISTE_PAYS", "LISTE_GENRE" et "LISTE_ACTEUR"
cur.execute("ALTER TABLE LISTE_GENRE ADD CONSTRAINT PK_GENRE PRIMARY KEY(SHOWID,GENRE) ");
print('Contraintes clé primaire ajoutée')
Contraintes clé primaire ajoutée
cur.execute("ALTER TABLE LISTE_ACTEUR ADD CONSTRAINT PK_ACTEUR PRIMARY KEY(SHOWID,ACTEUR) ");
print('Contraintes clé primaire ajoutée')
Contraintes clé primaire ajoutée
cur.execute("ALTER TABLE LISTE_PAYS ADD CONSTRAINT PK_PAYS PRIMARY KEY(SHOWID,PAYS) ");
print('Contraintes clé primaire ajoutée')
Contraintes clé primaire ajoutée
cur.execute("ALTER TABLE LISTE_PAYS ADD CONSTRAINT FK_PAYS_NETFLIX FOREIGN KEY(SHOWID) REFERENCES NETFLIX(SHOWID) ");
print('Contraintes clé étrangère ajoutée')
Contraintes clé étrangère ajoutée
cur.execute("ALTER TABLE LISTE_ACTEUR ADD CONSTRAINT FK_ACTEUR_NETFLIX FOREIGN KEY(SHOWID) REFERENCES NETFLIX(SHOWID) ");
print('Contraintes clé étrangère ajoutée')
Contraintes clé étrangère ajoutée
cur.execute("ALTER TABLE LISTE_GENRE ADD CONSTRAINT FK_GENRE_NETFLIX FOREIGN KEY(SHOWID) REFERENCES NETFLIX(SHOWID) ");
print('Contraintes clé étrangère ajoutée')
Contraintes clé étrangère ajoutée
Supprimer les colonnes transformées
cur.execute("ALTER TABLE NETFLIX DROP COLUMN PAYS ");
cur.execute("ALTER TABLE NETFLIX DROP COLUMN GENRE ");
cur.execute("ALTER TABLE NETFLIX DROP COLUMN ACTEUR ");
print('Colonnes supprimées')
Colonnes supprimées
Mettre en place une table temporelle DATEAJOUT
cur.execute("CREATE TABLE DATEAJOUT AS SELECT SHOWID,DATE_AJOUT FROM NETFLIX");
cur.execute("ALTER TABLE DATEAJOUT ADD CONSTRAINT PK_DATEAJOUT_NETFLIX PRIMARY KEY(SHOWID) ");
cur.execute("ALTER TABLE DATEAJOUT ADD CONSTRAINT FK_DATEAJOUT_NETFLIX FOREIGN KEY(SHOWID) REFERENCES NETFLIX(SHOWID) ");
cur.execute("ALTER TABLE DATEAJOUT ADD ANNEE NUMBER(4)");
cur.execute("UPDATE DATEAJOUT SET ANNEE=TO_CHAR(DATE_AJOUT,'YYYY')");
cur.execute("ALTER TABLE DATEAJOUT ADD NUMMOIS NUMBER(4)");
cur.execute("UPDATE DATEAJOUT SET NUMMOIS=TO_NUMBER(TO_CHAR(DATE_AJOUT,'MM'))");
cur.execute("ALTER TABLE DATEAJOUT ADD NOMMOIS VARCHAR(4)");
cur.execute("UPDATE DATEAJOUT SET NOMMOIS=TO_CHAR(DATE_AJOUT,'MON')");
cur.execute("ALTER TABLE DATEAJOUT ADD NUMJOUR NUMBER(4)");
cur.execute("UPDATE DATEAJOUT SET NUMJOUR=TO_NUMBER(TO_CHAR(DATE_AJOUT,'DD'))");
cur.execute("ALTER TABLE DATEAJOUT ADD NOMJOUR VARCHAR(10)");
cur.execute("UPDATE DATEAJOUT SET NOMJOUR=TO_CHAR(DATE_AJOUT,'DAY')");
cur.execute("ALTER TABLE DATEAJOUT ADD TRIMESTRE VARCHAR(4)");
cur.execute("UPDATE DATEAJOUT SET TRIMESTRE=CONCAT('Q',TO_CHAR(DATE_AJOUT,'Q'))");
print('table créée')
query="select * from DATEAJOUT";
df = pd.read_sql(query, conn)
df
table créée
| SHOWID | DATE_AJOUT | ANNEE | NUMMOIS | NOMMOIS | NUMJOUR | NOMJOUR | TRIMESTRE | |
|---|---|---|---|---|---|---|---|---|
| 0 | s4 | 2021-09-24 | 2021 | 9 | SEP | 24 | FRIDAY | Q3 |
| 1 | s11 | 2021-09-24 | 2021 | 9 | SEP | 24 | FRIDAY | Q3 |
| 2 | s12 | 2021-09-23 | 2021 | 9 | SEP | 23 | THURSDAY | Q3 |
| 3 | s16 | 2021-09-22 | 2021 | 9 | SEP | 22 | WEDNESDAY | Q3 |
| 4 | s19 | 2021-09-22 | 2021 | 9 | SEP | 22 | WEDNESDAY | Q3 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 8787 | s4475 | 2018-10-26 | 2018 | 10 | OCT | 26 | FRIDAY | Q4 |
| 8788 | s5663 | 2016-12-16 | 2016 | 12 | DEC | 16 | FRIDAY | Q4 |
| 8789 | s6874 | 2017-07-12 | 2017 | 7 | JUL | 12 | WEDNESDAY | Q3 |
| 8790 | s8313 | 2020-08-21 | 2020 | 8 | AUG | 21 | FRIDAY | Q3 |
| 8791 | s5412 | 2017-07-01 | 2017 | 7 | JUL | 1 | SATURDAY | Q3 |
8792 rows × 8 columns
Mettre en place le schéma de relation entre les tables avec Oracle SQL Developer

Mettre en place un package de gestion des shows
On désire mettre en place un paquetage logiciel permettant de gérer les shows. L’objectif est de disposer de procédures et de fonctions permettant
- De compter le nombre de shows
- D’insérer un nouveau show
- De compter le nombre de shows d'un âge donné.
- De supprimer un show par son showid
- De modifier le titre d'un show à partir de son numéro
Créer une copie de la table NETFLIX
cur.execute("DROP TABLE NETFLIX1");
cur.execute("CREATE TABLE NETFLIX1 AS SELECT SHOWID,TYPES,TITRE,DIRECTEUR,DATES,ANNEE_SORTIE,NOTATION,DUREE, DESCRIPTIONS,DUREE_FILM, DUREE_SERIE FROM NETFLIX");
print('Table créer')
Table créer
Créer l'entête du package
query="""
CREATE OR REPLACE PACKAGE GESTION_SHOW AS
PROCEDURE INSERER_SHOW (
VSHOWID NETFLIX1.SHOWID%TYPE,
VTYPES NETFLIX1.TYPES%TYPE,
VTITRE NETFLIX1.TITRE%TYPE,
VDIRECTEUR NETFLIX1.DIRECTEUR%TYPE,
VDATES NETFLIX1.DATES%TYPE,
VANNEE NETFLIX1.ANNEE_SORTIE %TYPE,
VNOTATION NETFLIX1.NOTATION%TYPE,
VDUREE NETFLIX1.DUREE %TYPE,
VDESCRIPTIONS NETFLIX1.DESCRIPTIONS%TYPE,
VDUREE_FILM NETFLIX1.DUREE_FILM %TYPE,
VDUREE_SERIE NETFLIX1.DUREE_SERIE%TYPE
);
FUNCTION COMPTER_SHOW RETURN INTEGER ;
FUNCTION COMPTER_SHOW_AGE(VAGE INTEGER) RETURN INTEGER;
PROCEDURE DELETE_SHOW(VSHOWID NETFLIX1.SHOWID%TYPE);
PROCEDURE MODIF_TITRE(VSHOWID NETFLIX1.SHOWID%TYPE,VTITRE NETFLIX1.TITRE%TYPE);
END GESTION_SHOW ;
"""
cur.execute(query)
print('Entête du package créer')
Entête du package créer
Créer le corps du package
query="""
CREATE OR REPLACE PACKAGE BODY GESTION_SHOW IS
PROCEDURE INSERER_SHOW (
VSHOWID NETFLIX1.SHOWID%TYPE,
VTYPES NETFLIX1.TYPES%TYPE,
VTITRE NETFLIX1.TITRE %TYPE,
VDIRECTEUR NETFLIX1.DIRECTEUR%TYPE,
VDATES NETFLIX1.DATES %TYPE,
VANNEE NETFLIX1.ANNEE_SORTIE%TYPE,
VNOTATION NETFLIX1.NOTATION%TYPE,
VDUREE NETFLIX1.DUREE %TYPE,
VDESCRIPTIONS NETFLIX1.DESCRIPTIONS%TYPE,
VDUREE_FILM NETFLIX1.DUREE_FILM%TYPE,
VDUREE_SERIE NETFLIX1.DUREE_SERIE%TYPE
)
IS
BEGIN
INSERT INTO NETFLIX1 VALUES(VSHOWID,VTYPES, VTITRE, VDIRECTEUR, VDATES, VANNEE, VNOTATION,VDUREE, VDESCRIPTIONS, VDUREE_FILM, VDUREE_SERIE );
END INSERER_SHOW;
FUNCTION COMPTER_SHOW RETURN INTEGER IS
NBSHOW INTEGER;
BEGIN
SELECT COUNT(*) INTO NBSHOW FROM NETFLIX1;
RETURN NBSHOW;
END COMPTER_SHOW;
FUNCTION COMPTER_SHOW_AGE(VAGE INTEGER) RETURN INTEGER IS
NBSHOW INTEGER;
BEGIN
SELECT COUNT(*) INTO NBSHOW FROM NETFLIX1 WHERE TO_CHAR(SYSDATE,'YYYY')-ANNEE_SORTIE=VAGE;
RETURN NBSHOW;
END COMPTER_SHOW_AGE;
PROCEDURE DELETE_SHOW(VSHOWID NETFLIX1.SHOWID%TYPE) IS
BEGIN
DELETE FROM NETFLIX1 WHERE SHOWID=VSHOWID;
END DELETE_SHOW;
PROCEDURE MODIF_TITRE(VSHOWID NETFLIX1.SHOWID%TYPE,VTITRE NETFLIX1.TITRE%TYPE) IS
BEGIN
UPDATE NETFLIX1 SET TITRE=VTITRE WHERE SHOWID=VSHOWID;
END MODIF_TITRE;
END GESTION_SHOW;
"""
cur.execute(query)
print('Corps du package créer')
Corps du package créer
Utiliser le package
cur.callproc('GESTION_SHOW.INSERER_SHOW',['AA307',' TV Show','Barikad','Thania Valcourt','21-12-24',2025,'ab','30','Show haitien',0,'4 season']);
cur.execute("COMMIT");
print('Insertion effectuée')
Insertion effectuée
df = pd.read_sql("select* from netflix1 where showid='AA307'", conn)
df
| SHOWID | TYPES | TITRE | DIRECTEUR | DATES | ANNEE_SORTIE | NOTATION | DUREE | DESCRIPTIONS | DUREE_FILM | DUREE_SERIE | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | AA307 | TV Show | Barikad | Thania Valcourt | 21-12-24 | 2025 | ab | 30 | Show haitien | 0 | 4 season |
query="select GESTION_SHOW.COMPTER_SHOW() NOMBRE FROM DUAL";
df = pd.read_sql(query, conn)
df
| NOMBRE | |
|---|---|
| 0 | 8793 |
query="select GESTION_SHOW.COMPTER_SHOW_AGE(4) NOMBRE FROM DUAL";
df = pd.read_sql(query, conn)
df
| NOMBRE | |
|---|---|
| 0 | 592 |
Exploitation des donnés
Dans cette partie du projet, on va répondre aux questions suivantes à travers des requêtes SQL. Certaines des réponses seront accompagnées d'une visualisation avec Seaborn.
- Répartition entre les types de show 'Movie' et 'TV Show' ?
- Trouver les années pour lesquelles le nombre de shows sortis dépasse 1000
- Afficher le nombre de shows ajoutés par année quand ce nombre dépasse 500 shows
- Trouver les cinq années avec le plus grand nombre de shows ajoutés
- Quel est le top 5 des catégories de shows les plus ajoutées
- Quel est le top 5 des acteurs les plus plébiscités aux États-Unis
- Quelle est la répartition des shows ajoutés en fonction du jour de la semaine
- Dans quel pays sont produits le plus de documentaires ?
- Combien de saisons ont les séries, en moyenne,
- Quelle est la répartition des films ajoutés en fonction de l'année et du trimestre
- Quelle est la répartition des séries ajoutées en fonction de l'année et du trimestre à partir de 2017
- Combien de shows ont pour thématiques (love, war, drug, sex, peace, kill, life, money) ?
- Trouvez les 5 classifications les plus courantes pour les films et les séries
- Trouver les 5 pays avec le plus de contenu sur Netflix
- Afficher pour chaque pays le show avec le plus d'acteur quand le nombre d'acteurs dépasse 20
- Afficher le premier show avec plus que 12 acteurs ajouté pour chaque pays
- Comparer le nombre de shows ajoutés une année avec celui de l'année précédente et une colonne indiquant une croissance ou une décroissance
- Comparer le nombre de shows ajoutés une année avec celui de l'année suivante et une colonne indiquant une croissance ou une décroissance
Répartition entre les types de show 'Movie' et 'TV Show' ?
query="""
SELECT
TYPES,
COUNT(*)
FROM NETFLIX
GROUP BY TYPES
""";
df = pd.read_sql(query, conn)
df
| TYPES | COUNT(*) | |
|---|---|---|
| 0 | TV Show | 2664 |
| 1 | Movie | 6128 |
Trouver les années pour lesquelles le nombre de shows sortis dépasse 1000
query="""
SELECT ANNEE_SORTIE, COUNT(SHOWID) "NOMBRE DE SHOW" ,TYPES FROM NETFLIX
GROUP BY ANNEE_SORTIE,TYPES
HAVING COUNT(SHOWID)>100
ORDER BY ANNEE_SORTIE
""";
df = pd.read_sql(query, conn)
df
| ANNEE_SORTIE | NOMBRE DE SHOW | TYPES | |
|---|---|---|---|
| 0 | 2008 | 113 | Movie |
| 1 | 2009 | 118 | Movie |
| 2 | 2010 | 154 | Movie |
| 3 | 2011 | 145 | Movie |
| 4 | 2012 | 173 | Movie |
| 5 | 2013 | 225 | Movie |
| 6 | 2014 | 265 | Movie |
| 7 | 2015 | 397 | Movie |
| 8 | 2015 | 159 | TV Show |
| 9 | 2016 | 658 | Movie |
| 10 | 2016 | 243 | TV Show |
| 11 | 2017 | 766 | Movie |
| 12 | 2017 | 265 | TV Show |
| 13 | 2018 | 766 | Movie |
| 14 | 2018 | 378 | TV Show |
| 15 | 2019 | 632 | Movie |
| 16 | 2019 | 397 | TV Show |
| 17 | 2020 | 517 | Movie |
| 18 | 2020 | 436 | TV Show |
| 19 | 2021 | 277 | Movie |
| 20 | 2021 | 315 | TV Show |
sns.set_context("paper", font_scale=0.9)
plt.figure(figsize=(12,4))
data=df
sns.barplot(x="ANNEE_SORTIE",y="NOMBRE DE SHOW", hue="TYPES",data=data,palette="Reds").set_title("Répartition des shows sortis par années");
plt.show()

Afficher le nombre de shows ajoutés par année quand ce nombre dépasse 500 shows
query="""
SELECT TO_CHAR(DATE_AJOUT,'YYYY') ANNEE_AJOUT,
COUNT(SHOWID) "NOMBRE DE SHOWS" ,
TYPES FROM NETFLIX
GROUP BY TO_CHAR(DATE_AJOUT,'YYYY'),TYPES
HAVING COUNT(SHOWID)>100
ORDER BY TO_CHAR(DATE_AJOUT,'YYYY')
""";
df = pd.read_sql(query, conn)
df
| ANNEE_AJOUT | NOMBRE DE SHOWS | TYPES | |
|---|---|---|---|
| 0 | 2016 | 253 | Movie |
| 1 | 2016 | 175 | TV Show |
| 2 | 2017 | 837 | Movie |
| 3 | 2017 | 349 | TV Show |
| 4 | 2018 | 1236 | Movie |
| 5 | 2018 | 411 | TV Show |
| 6 | 2019 | 1423 | Movie |
| 7 | 2019 | 591 | TV Show |
| 8 | 2020 | 1284 | Movie |
| 9 | 2020 | 595 | TV Show |
| 10 | 2021 | 993 | Movie |
| 11 | 2021 | 505 | TV Show |
plt.figure(figsize=(12,4))
data=df
sns.barplot(x="ANNEE_AJOUT",y="NOMBRE DE SHOWS",data=data,hue="TYPES" ,palette="Reds").set_title("Répartition des shows ajoutés par année");
plt.show()

Trouver les cinq années avec le plus grand nombre de shows ajoutés
query="""
WITH CINQSHOW AS
(
SELECT TO_CHAR(DATE_AJOUT,'YYYY') ANNEE ,
TYPES,
COUNT(SHOWID) NOMBRE
FROM NETFLIX
GROUP BY TO_CHAR(DATE_AJOUT,'YYYY'),TYPES
ORDER BY COUNT(SHOWID) DESC)
SELECT ROWNUM,ANNEE,TYPES, NOMBRE FROM CINQSHOW WHERE ROWNUM<=5
""";
df = pd.read_sql(query, conn)
df
| ROWNUM | ANNEE | TYPES | NOMBRE | |
|---|---|---|---|---|
| 0 | 1 | 2019 | Movie | 1423 |
| 1 | 2 | 2020 | Movie | 1284 |
| 2 | 3 | 2018 | Movie | 1236 |
| 3 | 4 | 2021 | Movie | 993 |
| 4 | 5 | 2017 | Movie | 837 |
plt.figure(figsize=(12,4))
data=df
sns.barplot(x="ANNEE",y="NOMBRE",data=data ,palette="Reds").set_title("Répartition des shows ajoutés par années");
plt.show()

Quel est le top 5 des catégories de shows les plus ajoutées
query="""
WITH CINQGENRE AS
(
SELECT GENRE,TYPES, COUNT(GENRE) NOMBRE
FROM LISTE_GENRE L
JOIN NETFLIX N
ON L.SHOWID=N.SHOWID
GROUP BY GENRE,TYPES
ORDER BY COUNT(GENRE) DESC)
SELECT ROWNUM,GENRE,TYPES, NOMBRE FROM CINQGENRE
WHERE ROWNUM<=5
""";
df = pd.read_sql(query, conn)
df
| ROWNUM | GENRE | TYPES | NOMBRE | |
|---|---|---|---|---|
| 0 | 1 | Dramas | Movie | 2251 |
| 1 | 2 | Comedies | Movie | 1409 |
| 2 | 3 | International TV Shows | TV Show | 1127 |
| 3 | 4 | International Movies | Movie | 966 |
| 4 | 5 | Action | Movie | 859 |
plt.figure(figsize=(12,4))
data=df
sns.barplot(y="GENRE",x="NOMBRE",data=data ,palette="RdPu" ,hue="TYPES").set_title("Top 5 des catégories de shows les plus ajoutées");
plt.show()

Quel est le top 5 des acteurs les plus plébiscités aux États-Unis
query="""
WITH CINQACTEUR AS
(
SELECT ACTEUR,PAYS, COUNT(ACTEUR) NOMBRE
FROM LISTE_ACTEUR A
JOIN NETFLIX N ON A.SHOWID=N.SHOWID
JOIN LISTE_PAYS P ON P.SHOWID=N.SHOWID
GROUP BY ACTEUR,PAYS
ORDER BY COUNT(ACTEUR) DESC )
SELECT ROWNUM,ACTEUR,PAYS, NOMBRE FROM CINQACTEUR
WHERE ROWNUM<=5 AND PAYS='United States'
AND ACTEUR<>'Inconnu'
""";
df = pd.read_sql(query, conn)
df
| ROWNUM | ACTEUR | PAYS | NOMBRE | |
|---|---|---|---|---|
| 0 | 1 | Samuel L. Jackson | United States | 21 |
| 1 | 2 | Adam Sandler | United States | 20 |
| 2 | 3 | Tara Strong | United States | 19 |
| 3 | 4 | Fred Tatasciore | United States | 18 |
| 4 | 5 | Nicolas Cage | United States | 17 |
Quelle est la répartition des shows ajoutés en fonction du jour de la semaine
query="""
SELECT NOMJOUR,TYPES, COUNT(N.SHOWID) AS NOMBRE
FROM
DATEAJOUT D JOIN NETFLIX N
ON D.SHOWID=N.SHOWID
GROUP BY NOMJOUR,TYPES
ORDER BY COUNT(N.SHOWID)
""";
df = pd.read_sql(query, conn)
df
| NOMJOUR | TYPES | NOMBRE | |
|---|---|---|---|
| 0 | SUNDAY | TV Show | 182 |
| 1 | MONDAY | TV Show | 223 |
| 2 | SATURDAY | TV Show | 259 |
| 3 | THURSDAY | TV Show | 341 |
| 4 | TUESDAY | TV Show | 345 |
| 5 | WEDNESDAY | TV Show | 381 |
| 6 | SATURDAY | Movie | 557 |
| 7 | SUNDAY | Movie | 569 |
| 8 | MONDAY | Movie | 628 |
| 9 | TUESDAY | Movie | 852 |
| 10 | WEDNESDAY | Movie | 904 |
| 11 | FRIDAY | TV Show | 933 |
| 12 | THURSDAY | Movie | 1052 |
| 13 | FRIDAY | Movie | 1566 |
plt.figure(figsize=(12,4))
data=df
sns.barplot(x="NOMJOUR",y="NOMBRE",data=data ,palette="RdPu" ,hue="TYPES").set_title("Répartition des shows ajoutés en fonction du jour de la semaine");
plt.show()

Dans quel pays sont produits le plus de documentaires ?
query="""
WITH MAXDOC AS
(
SELECT PAYS, COUNT(P.SHOWID) AS NOMBRE
FROM
LISTE_PAYS P JOIN LISTE_GENRE G
ON P.SHOWID=G.SHOWID
WHERE G.GENRE='Documentaries'
GROUP BY PAYS
ORDER BY COUNT(P.SHOWID) DESC)
SELECT ROWNUM, PAYS,NOMBRE FROM MAXDOC WHERE ROWNUM=1
""";
df = pd.read_sql(query, conn)
df
| ROWNUM | PAYS | NOMBRE | |
|---|---|---|---|
| 0 | 1 | United States | 445 |
Combien de saisons ont les séries,en moyenne ?
query="""
with cte as
(
select showid, types,duree_serie,replace(duree_serie,'Seasons','') duree from netflix where duree_serie like('%Seasons')
union
select showid,types,duree_serie, replace(duree_serie,'Season','') duree from netflix where duree_serie like('%Season')
) select round(trunc( avg(duree),2)) dureemoy from cte
""";
df = pd.read_sql(query, conn)
df
| DUREEMOY | |
|---|---|
| 0 | 2 |
Quelle est la répartition des films ajoutés en fonction de l'année et du trimestre
query="""
select annee, trimestre, count(n.showid) NOMBRE from
netflix n join dateajout d
on n.showid=d.showid
where types='Movie'
having count(n.showid)>150
group by annee,trimestre
order by annee, count(n.showid)
""";
df = pd.read_sql(query, conn)
df
| ANNEE | TRIMESTRE | NOMBRE | |
|---|---|---|---|
| 0 | 2017 | Q2 | 194 |
| 1 | 2017 | Q3 | 203 |
| 2 | 2017 | Q1 | 208 |
| 3 | 2017 | Q4 | 232 |
| 4 | 2018 | Q2 | 207 |
| 5 | 2018 | Q1 | 306 |
| 6 | 2018 | Q3 | 336 |
| 7 | 2018 | Q4 | 387 |
| 8 | 2019 | Q3 | 271 |
| 9 | 2019 | Q2 | 332 |
| 10 | 2019 | Q1 | 337 |
| 11 | 2019 | Q4 | 483 |
| 12 | 2020 | Q3 | 300 |
| 13 | 2020 | Q1 | 317 |
| 14 | 2020 | Q4 | 320 |
| 15 | 2020 | Q2 | 347 |
| 16 | 2021 | Q1 | 236 |
| 17 | 2021 | Q2 | 353 |
| 18 | 2021 | Q3 | 404 |
plt.figure(figsize=(12,4))
data=df
sns.set_style("white")
sns.barplot(x="ANNEE",y="NOMBRE",data=data,palette="pastel",hue="TRIMESTRE").set_title("Répartition des films par année et trimestre ");
plt.show()

Quelle est la répartition des séries ajoutées en fonction de l'année et du trimestre à partir de 2017
query="""
select annee, trimestre, count(n.showid) NOMBRE from
netflix n join dateajout d
on n.showid=d.showid
where types='TV Show'
and annee>2016
group by annee,trimestre
having count(n.showid)>50
order by annee, count(n.showid)
""";
df = pd.read_sql(query, conn)
df
| ANNEE | TRIMESTRE | NOMBRE | |
|---|---|---|---|
| 0 | 2017 | Q1 | 69 |
| 1 | 2017 | Q2 | 79 |
| 2 | 2017 | Q4 | 97 |
| 3 | 2017 | Q3 | 104 |
| 4 | 2018 | Q1 | 82 |
| 5 | 2018 | Q2 | 83 |
| 6 | 2018 | Q3 | 104 |
| 7 | 2018 | Q4 | 142 |
| 8 | 2019 | Q1 | 134 |
| 9 | 2019 | Q2 | 137 |
| 10 | 2019 | Q3 | 140 |
| 11 | 2019 | Q4 | 180 |
| 12 | 2020 | Q1 | 139 |
| 13 | 2020 | Q3 | 143 |
| 14 | 2020 | Q2 | 143 |
| 15 | 2020 | Q4 | 170 |
| 16 | 2021 | Q1 | 117 |
| 17 | 2021 | Q2 | 174 |
| 18 | 2021 | Q3 | 214 |
plt.figure(figsize=(12,4))
data=df
sns.set_style("white")
sns.barplot(x="ANNEE",y="NOMBRE",data=data,palette='Pastel2',hue="TRIMESTRE").set_title("Répartition des séries par année et trimestre ");
plt.show()

Combien de shows ont pour thématique (love, war, drug, sex, peace, kill, life, money) ?
query="""
select
case
when descriptions like('%love%') then 'Love'
when descriptions like('%war%') then 'War'
when descriptions like('%drug%') then 'Drug'
when descriptions like('%sex%') then 'Sex'
when descriptions like('%peace%') then 'Peace'
when descriptions like('%kill%') then 'Kill'
when descriptions like('%live%') then 'Life'
when descriptions like('%money%') then 'Money'
else 'autres'
end sujet,
count(showid) nombre
from netflix
group by
case
when descriptions like('%love%') then 'Love'
when descriptions like('%war%') then 'War'
when descriptions like('%drug%') then 'Drug'
when descriptions like('%sex%') then 'Sex'
when descriptions like('%peace%') then 'Peace'
when descriptions like('%kill%') then 'Kill'
when descriptions like('%live%') then 'Life'
when descriptions like('%money%') then 'Money'
else 'autres'
end
order by count(showid)
""";
df = pd.read_sql(query, conn)
df
| SUJET | NOMBRE | |
|---|---|---|
| 0 | Peace | 37 |
| 1 | Money | 61 |
| 2 | Drug | 137 |
| 3 | Sex | 138 |
| 4 | Kill | 266 |
| 5 | War | 377 |
| 6 | Life | 430 |
| 7 | Love | 688 |
| 8 | autres | 6658 |
Trouvez les 5 classifications les plus courantes pour les films et les séries
query="""
WITH CINQCLASS AS
(
SELECT NOTATION , COUNT(NOTATION) NOMBRE
FROM NETFLIX
GROUP BY NOTATION
ORDER BY COUNT(NOTATION) DESC)
SELECT ROWNUM,NOTATION, NOMBRE FROM CINQCLASS
WHERE ROWNUM<=5
""";
df = pd.read_sql(query, conn)
df
| ROWNUM | NOTATION | NOMBRE | |
|---|---|---|---|
| 0 | 1 | TV-MA | 3206 |
| 1 | 2 | TV-14 | 2155 |
| 2 | 3 | TV-PG | 861 |
| 3 | 4 | R | 798 |
| 4 | 5 | PG-13 | 490 |
Trouver les 5 pays avec le plus de contenu sur Netflix
query="""
WITH CINQPAYS AS
(
SELECT PAYS, COUNT(PAYS) NOMBRE
FROM LISTE_PAYS L
JOIN NETFLIX N
ON L.SHOWID=N.SHOWID
WHERE PAYS<>'Inconnu'
GROUP BY PAYS
ORDER BY COUNT(PAYS) DESC)
SELECT ROWNUM,PAYS,NOMBRE FROM CINQPAYS
WHERE ROWNUM<=5
""";
df = pd.read_sql(query, conn)
df
| ROWNUM | PAYS | NOMBRE | |
|---|---|---|---|
| 0 | 1 | United States | 3291 |
| 1 | 2 | India | 1021 |
| 2 | 3 | United Kingdom | 704 |
| 3 | 4 | Canada | 330 |
| 4 | 5 | France | 301 |
sns.set_style("whitegrid")
plt.figure(figsize=(5,5))
plt.pie(df['NOMBRE'], labels=df['PAYS'], autopct='%1.1f%%')
plt.title('Les pays les plus producteurs')
plt.show()

Afficher pour chaque pays les shows avec plus que 20 acteurs
query="""
WITH PAYSACTEUR
AS
(
SELECT PAYS, N.SHOWID,TITRE,COUNT(ACTEUR) NOMBRE,
DENSE_RANK() OVER(PARTITION BY PAYS ORDER BY COUNT(ACTEUR) DESC) RANG
FROM NETFLIX N
JOIN LISTE_ACTEUR A ON N.SHOWID=A.SHOWID
JOIN LISTE_PAYS P ON P.SHOWID=A.SHOWID
GROUP BY PAYS,N.SHOWID,TITRE
ORDER BY PAYS,COUNT(ACTEUR) DESC
)
SELECT* FROM PAYSACTEUR WHERE PAYSACTEUR.RANG=1
AND PAYSACTEUR.NOMBRE>20
AND PAYSACTEUR.PAYS<>'Inconnu'
order by PAYSACTEUR.NOMBRE DESC
""";
df = pd.read_sql(query, conn)
df
| PAYS | SHOWID | TITRE | NOMBRE | RANG | |
|---|---|---|---|---|---|
| 0 | United Kingdom | s3775 | Black Mirror | 49 | 1 |
| 1 | United States | s1855 | Social Distance | 49 | 1 |
| 2 | Australia | s1640 | Heartbreak High | 46 | 1 |
| 3 | Colombia | s5306 | Narcos | 41 | 1 |
| 4 | Denmark | s2065 | Borgen | 30 | 1 |
| 5 | Japan | s6732 | Fairy Tail | 29 | 1 |
| 6 | France | s8483 | The Returned | 28 | 1 |
| 7 | Canada | s1066 | Slasher | 27 | 1 |
| 8 | Thailand | s8575 | ThirTEEN Terrors | 26 | 1 |
| 9 | Mexico | s4168 | Club of Crows | 26 | 1 |
| 10 | Spain | s2977 | Unauthorized Living | 26 | 1 |
| 11 | Brazil | s1772 | Afronta! Facing It! | 25 | 1 |
| 12 | South Korea | s4677 | Ultimate Beastmaster | 24 | 1 |
| 13 | Argentina | s2386 | Underdogs | 22 | 1 |
| 14 | India | s298 | Navarasa | 21 | 1 |
plt.figure(figsize=(12,4))
data=df
sns.barplot(y="PAYS",x="NOMBRE",data=data ,palette="pastel" ,hue="TITRE").set_title("Shows avec le plus que 20 acteurs par pays");
plt.xlabel("Nombre d'acteurs")
plt.show()

Afficher le premier show avec plus que 12 acteurs ajouté pour chaque pays
query="""
WITH PAYSSHOW
AS
(
SELECT P.PAYS, N.SHOWID,TITRE, D.DATE_AJOUT,COUNT(ACTEUR) NOMBRE,
DENSE_RANK() OVER(PARTITION BY PAYS ORDER BY D.DATE_AJOUT DESC) RANG
FROM NETFLIX N JOIN DATEAJOUT D ON N.SHOWID=D.SHOWID
JOIN LISTE_PAYS P ON P.SHOWID=N.SHOWID
JOIN LISTE_ACTEUR A ON N.SHOWID=A.SHOWID
GROUP BY PAYS, N.SHOWID,TITRE, D.DATE_AJOUT
)
SELECT* FROM PAYSSHOW WHERE PAYSSHOW.RANG=1
AND PAYSSHOW.NOMBRE>=12
AND PAYSSHOW.PAYS<>'Inconnu'
""";
df = pd.read_sql(query, conn)
df
| PAYS | SHOWID | TITRE | DATE_AJOUT | NOMBRE | RANG | |
|---|---|---|---|---|---|---|
| 0 | Croatia | s4227 | The Paper | 2019-01-01 | 13 | 1 |
| 1 | Indonesia | s453 | A Perfect Fit | 2021-07-15 | 15 | 1 |
| 2 | Ireland | s213 | Rebellion | 2021-08-27 | 12 | 1 |
| 3 | Japan | s60 | Naruto Shippuden: The Movie | 2021-09-15 | 20 | 1 |
| 4 | Japan | s61 | Naruto Shippuden: The Movie: The Lost Tower | 2021-09-15 | 13 | 1 |
| 5 | Japan | s59 | Naruto Shippûden the Movie: The Will of Fire | 2021-09-15 | 12 | 1 |
| 6 | Nigeria | s50 | Castle and Castle | 2021-09-15 | 13 | 1 |
| 7 | Paraguay | s4065 | The Last Runway | 2019-03-01 | 12 | 1 |
| 8 | Saudi Arabia | s437 | The Tambour of Retribution | 2021-07-19 | 12 | 1 |
| 9 | South Africa | s2 | Blood & Water | 2021-09-24 | 18 | 1 |
| 10 | Syria | s840 | The Day I lost My Shadow | 2021-05-27 | 13 | 1 |
| 11 | United States | s8809 | Serena | 2024-04-05 | 35 | 1 |
| 12 | West Germany | s7994 | Shaka Zulu | 2019-01-10 | 14 | 1 |
Comparer le nombre de shows ajoutés une année avec celui de l'année précédente et Ajouter une colonne indiquant une croissance ou une décroissance
query="""
SELECT
ANNEE,
COUNT(SHOWID) NOMBRE,
LAG(COUNT(SHOWID)) OVER (ORDER BY ANNEE) AS NOMBRE_AVANT,
CASE
WHEN COUNT(SHOWID) - LAG(COUNT(SHOWID)) OVER (ORDER BY ANNEE)>0 THEN 'Croissance'
WHEN COUNT(SHOWID) - LAG(COUNT(SHOWID)) OVER (ORDER BY ANNEE)<0 THEN 'Décroissance'
WHEN COUNT(SHOWID) - LAG(COUNT(SHOWID)) OVER (ORDER BY ANNEE)=0 THEN 'Stable'
ELSE 'Pas de valeur'
END REMARQUE
FROM DATEAJOUT
GROUP BY ANNEE
ORDER BY ANNEE
""";
df = pd.read_sql(query, conn)
df
| ANNEE | NOMBRE | NOMBRE_AVANT | REMARQUE | |
|---|---|---|---|---|
| 0 | 2008 | 2 | NaN | Pas de valeur |
| 1 | 2009 | 2 | 2.0 | Stable |
| 2 | 2010 | 1 | 2.0 | Décroissance |
| 3 | 2011 | 13 | 1.0 | Croissance |
| 4 | 2012 | 3 | 13.0 | Décroissance |
| 5 | 2013 | 11 | 3.0 | Croissance |
| 6 | 2014 | 24 | 11.0 | Croissance |
| 7 | 2015 | 82 | 24.0 | Croissance |
| 8 | 2016 | 428 | 82.0 | Croissance |
| 9 | 2017 | 1186 | 428.0 | Croissance |
| 10 | 2018 | 1647 | 1186.0 | Croissance |
| 11 | 2019 | 2014 | 1647.0 | Croissance |
| 12 | 2020 | 1879 | 2014.0 | Décroissance |
| 13 | 2021 | 1498 | 1879.0 | Décroissance |
| 14 | 2024 | 2 | 1498.0 | Décroissance |
plt.figure(figsize=(12,4))
sns.set_style("white")
data=df
sns.lineplot(x=data["ANNEE"], y=data["NOMBRE"], label='Shows ajoutés année courante',color='r', linewidth=2, marker='o', markersize=3)
sns.lineplot(x=data["ANNEE"], y=data["NOMBRE_AVANT"], label='Shows ajoutés année précedente',color='y', linewidth=2, marker='o', markersize=3)
plt.title('Courbes des shows ajoutés par années et années précédentes')
plt.xlabel('Année ajout')
plt.ylabel('Shows ajoutés')
plt.legend()
plt.show()

Comparer le nombre de shows ajoutés une année avec celui de l'année suivante et une colonne indiquant une croissance ou une décroissance
query="""
SELECT
ANNEE,
COUNT(SHOWID) NOMBRE,
LEAD(COUNT(SHOWID)) OVER (ORDER BY ANNEE) AS NOMBRE_AVANT,
CASE
WHEN COUNT(SHOWID) - LEAD(COUNT(SHOWID)) OVER (ORDER BY ANNEE)>0 THEN 'Croissance'
WHEN COUNT(SHOWID) - LEAD(COUNT(SHOWID)) OVER (ORDER BY ANNEE)<0 THEN 'Décroissance'
WHEN COUNT(SHOWID) - LEAD(COUNT(SHOWID)) OVER (ORDER BY ANNEE)=0 THEN 'Stable'
ELSE 'Pas de valeur'
END REMARQUE
FROM DATEAJOUT
GROUP BY ANNEE
ORDER BY ANNEE
""";
df = pd.read_sql(query, conn)
df
| ANNEE | NOMBRE | NOMBRE_AVANT | REMARQUE | |
|---|---|---|---|---|
| 0 | 2008 | 2 | 2.0 | Stable |
| 1 | 2009 | 2 | 1.0 | Croissance |
| 2 | 2010 | 1 | 13.0 | Décroissance |
| 3 | 2011 | 13 | 3.0 | Croissance |
| 4 | 2012 | 3 | 11.0 | Décroissance |
| 5 | 2013 | 11 | 24.0 | Décroissance |
| 6 | 2014 | 24 | 82.0 | Décroissance |
| 7 | 2015 | 82 | 428.0 | Décroissance |
| 8 | 2016 | 428 | 1186.0 | Décroissance |
| 9 | 2017 | 1186 | 1647.0 | Décroissance |
| 10 | 2018 | 1647 | 2014.0 | Décroissance |
| 11 | 2019 | 2014 | 1879.0 | Croissance |
| 12 | 2020 | 1879 | 1498.0 | Croissance |
| 13 | 2021 | 1498 | 2.0 | Croissance |
| 14 | 2024 | 2 | NaN | Pas de valeur |
sns.set_style("white")
data=df
plt.figure(figsize=(12, 4))
sns.lineplot(x=data["ANNEE"], y=data["NOMBRE"], label='Shows ajoutés année courante',color='r', linewidth=2, marker='o', markersize=3)
sns.lineplot(x=data["ANNEE"], y=data["NOMBRE_AVANT"], label='Shows ajoutés année précedente',color='#FF00FF', linewidth=2, marker='o', markersize=3)
plt.title('Courbes des schows ajoutés par années et années suivantes')
plt.xlabel('Année ajout')
plt.ylabel('Shows ajoutés')
plt.legend()
plt.show()

DEUXIEME PARTIE: PYTHON-PANDAS
Collecte, Nettoyage, Modelisation et Analyse des donnés avec PANDAS;
Cette partie est consacrée à l'utilisation du langage Python à travers les librairies Numpy, Pandas, Matplotlib et Seaborn. Elle consistera à :
- Collecter les données;
- Explorer les données;
- Nettoyer les données;
- Modéliser les données;
- Exploiter les données.
Collecte des donnés
Importer des données
import pandas as pd
import numpy as np
netflix = pd.read_csv('netflix_titles.csv' , encoding='latin1')
netflix.head(3)
| show_id | type | title | director | cast | country | date_added | release_year | rating | duration | listed_in | description | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | s1 | Movie | Dick Johnson Is Dead | Kirsten Johnson | NaN | United States | September 25, 2021 | 2020 | PG-13 | 90 min | Documentaries | As her father nears the end of his life, filmm... |
| 1 | s2 | TV Show | Blood & Water | NaN | Ama Qamata, Khosi Ngema, Gail Mabalane, Thaban... | South Africa | September 24, 2021 | 2021 | TV-MA | 2 Seasons | International TV Shows, TV Dramas, TV Mysteries | After crossing paths at a party, a Cape Town t... |
| 2 | s3 | TV Show | Ganglands | Julien Leclercq | Sami Bouajila, Tracy Gotoas, Samuel Jouy, Nabi... | NaN | September 24, 2021 | 2021 | TV-MA | 1 Season | Crime TV Shows, International TV Shows, TV Act... | To protect his family from a powerful drug lor... |
Afficher les colonnes du DataFrame
netflix.columns
Index(['show_id', 'type', 'title', 'director', 'cast', 'country', 'date_added',
'release_year', 'rating', 'duration', 'listed_in', 'description'],
dtype='object')
Afficher les informations sur les colonnes
netflix.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 8809 entries, 0 to 8808 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 show_id 8809 non-null object 1 type 8809 non-null object 2 title 8809 non-null object 3 director 6175 non-null object 4 cast 7984 non-null object 5 country 7978 non-null object 6 date_added 8799 non-null object 7 release_year 8809 non-null int64 8 rating 8805 non-null object 9 duration 8806 non-null object 10 listed_in 8809 non-null object 11 description 8809 non-null object dtypes: int64(1), object(11) memory usage: 826.0+ KB
Afficher le nombre de valeurs nulles par colonne
netflix.isnull().sum()
show_id 0 type 0 title 0 director 2634 cast 825 country 831 date_added 10 release_year 0 rating 4 duration 3 listed_in 0 description 0 dtype: int64
Data Cleaning
Afficher le pourcentage de valeurs nulles par colonne
netflix.isnull().mean() * 100
show_id 0.000000 type 0.000000 title 0.000000 director 29.901237 cast 9.365422 country 9.433534 date_added 0.113520 release_year 0.000000 rating 0.045408 duration 0.034056 listed_in 0.000000 description 0.000000 dtype: float64
Vérifier que la colonne "Show_id" ne possède ni valeur nulle ni doublon
print(len(netflix['show_id']))
print(netflix['show_id'].nunique())
8809 8809
Définir un nouvel index avec show_id
netflix.set_index('show_id', inplace=True)
netflix.head(3)
| type | title | director | cast | country | date_added | release_year | rating | duration | listed_in | description | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| show_id | |||||||||||
| s1 | Movie | Dick Johnson Is Dead | Kirsten Johnson | NaN | United States | September 25, 2021 | 2020 | PG-13 | 90 min | Documentaries | As her father nears the end of his life, filmm... |
| s2 | TV Show | Blood & Water | NaN | Ama Qamata, Khosi Ngema, Gail Mabalane, Thaban... | South Africa | September 24, 2021 | 2021 | TV-MA | 2 Seasons | International TV Shows, TV Dramas, TV Mysteries | After crossing paths at a party, a Cape Town t... |
| s3 | TV Show | Ganglands | Julien Leclercq | Sami Bouajila, Tracy Gotoas, Samuel Jouy, Nabi... | NaN | September 24, 2021 | 2021 | TV-MA | 1 Season | Crime TV Shows, International TV Shows, TV Act... | To protect his family from a powerful drug lor... |
Gestion de la colonne: 'date_added'
Modifier le format des valeurs
netflix['date_added'] = pd.to_datetime(netflix['date_added'].str.strip(), format='%B %d, %Y')
netflix['date_added']
show_id
s1 2021-09-25
s2 2021-09-24
s3 2021-09-24
s4 2021-09-24
s5 2021-09-24
...
s8805 2019-11-01
s8806 2020-01-11
s8807 2019-03-02
s8808 2024-04-05
s8809 2024-04-05
Name: date_added, Length: 8809, dtype: datetime64[ns]
Gestion de la colonne: 'duration'
Trouver les valeurs uniques de la colonne: type
print(netflix['type'].unique())
['Movie' 'TV Show']
Verifier la répartition des valeurs de duration aux types de show
netflix.groupby(['type','duration'])['duration'].count()
type duration
Movie 10 min 1
100 min 108
101 min 116
102 min 122
103 min 114
...
TV Show 5 Seasons 65
6 Seasons 33
7 Seasons 23
8 Seasons 17
9 Seasons 9
Name: duration, Length: 220, dtype: int64
Créer une colonne "duree_film" pour y stocker la durée des films
#Création d'une colonne vide
netflix['duree_film'] = np.nan
#Remplir la colonne vide des valeurs de "duration" correspondant aux films
netflix.loc[netflix['type'] == 'Movie', 'duree_film'] = netflix.loc[netflix['type'] == 'Movie', 'duration']
#Remplacer la chaine 'min' par le caractère vide
netflix['duree_film']=netflix['duree_film'].str.replace(' min', '')
#Convertir en float la colonne 'duree_film'
netflix['duree_film'] = netflix['duree_film'].astype(float)
netflix['duree_film']
show_id
s1 90.0
s2 NaN
s3 NaN
s4 NaN
s5 NaN
...
s8805 88.0
s8806 88.0
s8807 111.0
s8808 NaN
s8809 110.0
Name: duree_film, Length: 8809, dtype: float64
Créer une colonne "dure_serie" pour y stocker la durée des colonnes
#Création d'une colonne vide
netflix['duree_serie'] = np.nan
#Remplir la colonne vide des valeurs de "duration" correspondant aux films
netflix.loc[netflix['type'] == 'TV Show', 'duree_serie'] = netflix.loc[netflix['type'] == 'TV Show', 'duration']
#Remplacer la chaine 'Seasons' par le caractère vide
netflix['duree_serie']=netflix['duree_serie'].str.replace('Seasons', '')
#Remplacer la chaine 'Season' par le caractère vide
netflix['duree_serie']=netflix['duree_serie'].str.replace('Season', '')
#Convertir en float la colonne 'duree_film'
netflix['duree_serie'] = netflix['duree_serie'].astype(float)
netflix['duree_serie']
show_id
s1 NaN
s2 2.0
s3 1.0
s4 1.0
s5 2.0
...
s8805 NaN
s8806 NaN
s8807 NaN
s8808 1.0
s8809 NaN
Name: duree_serie, Length: 8809, dtype: float64
Supprimer la colonne 'duration'
netflix.drop(columns=['duration'], inplace=True)
print('Colonne supprimée')
Colonne supprimée
Gestion de la colonne muli-valeurs "country"
Afficher les dix premières valeurs
netflix['country'].head(10)
show_id s1 United States s2 South Africa s3 NaN s4 NaN s5 India s6 NaN s7 NaN s8 United States, Ghana, Burkina Faso, United Kin... s9 United Kingdom s10 United States Name: country, dtype: object
Créer un nouveau dataset liste_pays pour stocker la liste des pays d'un show
netflix['pays'] = netflix['country'].str.split(', ')
liste_pays= netflix.explode('pays')
liste_pays=liste_pays['pays']
liste_pays.head(10)
show_id s1 United States s2 South Africa s3 NaN s4 NaN s5 India s6 NaN s7 NaN s8 United States s8 Ghana s8 Burkina Faso Name: pays, dtype: object
Gestion de la colonne muli-valeurs "listed_in"
Créer un nouveau dataset liste_genre pour y stocker la liste des genres d'un show
netflix['genres'] = netflix['listed_in'].str.split(', ')
liste_genres = netflix.explode('genres')
liste_genres = liste_genres['genres']
liste_genres.head(10)
show_id s1 Documentaries s2 International TV Shows s2 TV Dramas s2 TV Mysteries s3 Crime TV Shows s3 International TV Shows s3 TV Action & Adventure s4 Docuseries s4 Reality TV s5 International TV Shows Name: genres, dtype: object
Gestion de la colonne muli-valeurs "cast"
Créer un nouveau dataset liste_acteurs pour y stocker la liste des acteurs d'un show
netflix['acteurs'] = netflix['cast'].str.split(', ')
liste_acteurs = netflix.explode('acteurs')
liste_acteurs= liste_acteurs['acteurs']
liste_acteurs.head(10)
show_id s1 NaN s2 Ama Qamata s2 Khosi Ngema s2 Gail Mabalane s2 Thabang Molaba s2 Dillon Windvogel s2 Natasha Thahane s2 Arno Greeff s2 Xolile Tshabalala s2 Getmore Sithole Name: acteurs, dtype: object
Supprimer les colonnes transformées
netflix.columns
Index(['type', 'title', 'director', 'cast', 'country', 'date_added',
'release_year', 'rating', 'listed_in', 'description', 'duree_film',
'duree_serie', 'pays', 'genres', 'acteurs'],
dtype='object')
netflix.drop(columns=['pays', 'genres', 'acteurs'], inplace=True)
netflix.head(3)
| type | title | director | cast | country | date_added | release_year | rating | listed_in | description | duree_film | duree_serie | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| show_id | ||||||||||||
| s1 | Movie | Dick Johnson Is Dead | Kirsten Johnson | NaN | United States | 2021-09-25 | 2020 | PG-13 | Documentaries | As her father nears the end of his life, filmm... | 90.0 | NaN |
| s2 | TV Show | Blood & Water | NaN | Ama Qamata, Khosi Ngema, Gail Mabalane, Thaban... | South Africa | 2021-09-24 | 2021 | TV-MA | International TV Shows, TV Dramas, TV Mysteries | After crossing paths at a party, a Cape Town t... | NaN | 2.0 |
| s3 | TV Show | Ganglands | Julien Leclercq | Sami Bouajila, Tracy Gotoas, Samuel Jouy, Nabi... | NaN | 2021-09-24 | 2021 | TV-MA | Crime TV Shows, International TV Shows, TV Act... | To protect his family from a powerful drug lor... | NaN | 1.0 |
Créer des colonnes temporelles à partir de la colonne 'date_added'
Ajouter les colonnes 'annee_ajout', 'mois_ajout' et 'jour_ajout'
netflix['annee_ajout'] = netflix['date_added'].dt.year
netflix['mois_ajout'] = netflix['date_added'].dt.month
netflix['nom_mois'] = netflix['date_added'].dt.month_name()
netflix['nom_mois_abr'] = netflix['date_added'].dt.strftime('%b')
netflix['jour_ajout'] = netflix['date_added'].dt.dayofweek
netflix['nom_jour'] = netflix['date_added'].dt.day_name()
netflix[['date_added','annee_ajout','mois_ajout','jour_ajout','nom_jour','nom_mois','nom_mois_abr']].head(5)
| date_added | annee_ajout | mois_ajout | jour_ajout | nom_jour | nom_mois | nom_mois_abr | |
|---|---|---|---|---|---|---|---|
| show_id | |||||||
| s1 | 2021-09-25 | 2021.0 | 9.0 | 5.0 | Saturday | September | Sep |
| s2 | 2021-09-24 | 2021.0 | 9.0 | 4.0 | Friday | September | Sep |
| s3 | 2021-09-24 | 2021.0 | 9.0 | 4.0 | Friday | September | Sep |
| s4 | 2021-09-24 | 2021.0 | 9.0 | 4.0 | Friday | September | Sep |
| s5 | 2021-09-24 | 2021.0 | 9.0 | 4.0 | Friday | September | Sep |
Convertir les colonnes en float
netflix['annee_ajout'] = netflix['annee_ajout'].astype(float)
netflix['mois_ajout'] = netflix['mois_ajout'].astype(float)
netflix['jour_ajout'] = netflix['jour_ajout'].astype(float)
print('Conversion effectuée')
Conversion effectuée
Gestion des valeurs nulles
netflix.info()
<class 'pandas.core.frame.DataFrame'> Index: 8809 entries, s1 to s8809 Data columns (total 18 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 type 8809 non-null object 1 title 8809 non-null object 2 director 6175 non-null object 3 cast 7984 non-null object 4 country 7978 non-null object 5 date_added 8799 non-null datetime64[ns] 6 release_year 8809 non-null int64 7 rating 8805 non-null object 8 listed_in 8809 non-null object 9 description 8809 non-null object 10 duree_film 6129 non-null float64 11 duree_serie 2677 non-null float64 12 annee_ajout 8799 non-null float64 13 mois_ajout 8799 non-null float64 14 nom_mois 8799 non-null object 15 nom_mois_abr 8799 non-null object 16 jour_ajout 8799 non-null float64 17 nom_jour 8799 non-null object dtypes: datetime64[ns](1), float64(5), int64(1), object(11) memory usage: 1.5+ MB
netflix.isnull().sum()
type 0 title 0 director 2634 cast 825 country 831 date_added 10 release_year 0 rating 4 listed_in 0 description 0 duree_film 2680 duree_serie 6132 annee_ajout 10 mois_ajout 10 nom_mois 10 nom_mois_abr 10 jour_ajout 10 nom_jour 10 dtype: int64
(netflix.isnull().sum()/netflix.shape[0])*100
type 0.000000 title 0.000000 director 29.901237 cast 9.365422 country 9.433534 date_added 0.113520 release_year 0.000000 rating 0.045408 listed_in 0.000000 description 0.000000 duree_film 30.423431 duree_serie 69.610625 annee_ajout 0.113520 mois_ajout 0.113520 nom_mois 0.113520 nom_mois_abr 0.113520 jour_ajout 0.113520 nom_jour 0.113520 dtype: float64
Afficher la carte de chaleur des valeurs nulles
plt.figure(figsize=(12,4))
sns.heatmap(netflix.isnull())
plt.show()

Afficher les colonnes de type texte
for i in netflix.select_dtypes(include="object").columns:
print(i)
type title director cast country rating listed_in description nom_mois nom_mois_abr nom_jour
Remplacer les valeurs nulles par la donnée la plus fréquente
for i in netflix.select_dtypes(include="object").columns:
netflix[i].fillna(netflix[i].mode()[0],inplace=True)
Afficher les colonnes de type numérique
netflix.select_dtypes(include="float64").columns
Index(['duree_film', 'duree_serie', 'annee_ajout', 'mois_ajout', 'jour_ajout'], dtype='object')
Remplacer les valeurs nulles par la donnée la plus fréquente
for i in netflix.select_dtypes(include="float64").columns:
netflix[i].fillna(netflix[i].mode()[0],inplace=True)
Afficher le pourcentage les valeurs nulles des colonnes
(netflix.isnull().sum()/netflix.shape[0])*100
type 0.00000 title 0.00000 director 0.00000 cast 0.00000 country 0.00000 date_added 0.11352 release_year 0.00000 rating 0.00000 listed_in 0.00000 description 0.00000 duree_film 0.00000 duree_serie 0.00000 annee_ajout 0.00000 mois_ajout 0.00000 nom_mois 0.00000 nom_mois_abr 0.00000 jour_ajout 0.00000 nom_jour 0.00000 dtype: float64
Remplacer les valeurs nulles de "date_added" par la valeur la plus fréquente
netflix["date_added"].fillna(netflix["date_added"].mode()[0],inplace=True)
netflix.isna().sum()
type 0 title 0 director 0 cast 0 country 0 date_added 0 release_year 0 rating 0 listed_in 0 description 0 duree_film 0 duree_serie 0 annee_ajout 0 mois_ajout 0 nom_mois 0 nom_mois_abr 0 jour_ajout 0 nom_jour 0 dtype: int64
plt.figure(figsize=(12,4))
sns.heatmap(netflix.isnull())
plt.show()

Exploitation des données
Combien de "show" sont présents dans ce dataset ?
len(netflix)
8809
Quelle est la répartition entre les types Movie et TV Show ?
netflix['type'].value_counts()
type Movie 6132 TV Show 2677 Name: count, dtype: int64
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
netflix['type'].value_counts().plot.bar(color=couleur)
plt.title('Répartition entre les types Movie et TV Show')
plt.subplot(1,2,2)
netflix['type'].value_counts().plot.pie(autopct = '%1.1f%%',cmap = 'Set1')
plt.title('Répartition entre les types Movie et TV Show')
plt.show()

Quelle est la répartition des ajouts de show en fonction de l'année ?
netflix['annee_ajout'].value_counts()
annee_ajout 2019.0 2026 2020.0 1879 2018.0 1649 2021.0 1498 2017.0 1188 2016.0 429 2015.0 82 2014.0 24 2011.0 13 2013.0 11 2012.0 3 2009.0 2 2008.0 2 2024.0 2 2010.0 1 Name: count, dtype: int64
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
netflix['annee_ajout'].value_counts().head(6).plot.bar(color=couleur)
plt.title('Répartition des ajouts de shows à partir de 2016')
plt.xlabel("Année d'ajout")
plt.subplot(1,2,2)
netflix['annee_ajout'].value_counts().head(6).plot.pie(autopct = '%1.1f%%',cmap = 'Set1')
plt.title('Répartition des ajouts de shows à partir de 2016')
plt.show()

Quel est le top 5 des catégories de show les plus ajoutées ?
liste_genres.value_counts().head(5)
genres International Movies 2752 Dramas 2427 Comedies 1674 International TV Shows 1351 Documentaries 869 Name: count, dtype: int64
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
liste_genres.value_counts().head(5).plot.bar(color=couleur)
plt.title('Top 5 des catégories de show les plus ajoutés')
plt.xlabel("Catégories")
plt.subplot(1,2,2)
liste_genres.value_counts().head(5).plot.pie(autopct = '%1.1f%%',cmap = 'Set1')
plt.title('Top 5 des catégories de show les plus ajoutés')
plt.show()

Quel est le top 5 des acteurs les plus plébiscités aux États-Unis ?
top5actceur = pd.merge(liste_acteurs, netflix, how='inner', left_index=True, right_index=True)
top5actceur[top5actceur['country'].str.contains('United States') == True]['acteurs'].value_counts().head(5)
acteurs Julie Tejwani 26 Rupa Bhimani 25 Samuel L. Jackson 24 Fred Tatasciore 23 Andrea Libman 22 Name: count, dtype: int64
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
top5actceur[top5actceur['country'].str.contains('United States') == True]['acteurs'].value_counts().head(5).plot.bar(color=couleur)
plt.title('Top 5 des acteurs les plus plébiscités aux États-Unis')
plt.xlabel("Acteurs")
plt.subplot(1,2,2)
top5actceur[top5actceur['country'].str.contains('United States') == True]['acteurs'].value_counts().head(5).plot.pie(
autopct = '%1.1f%%',cmap = 'Set1')
plt.title('Top 5 des acteurs les plus plébiscités aux États-Unis')
plt.show()

Quelle est la répartition des ajouts en fonction du jour de la semaine ?
netflix['nom_jour'].value_counts()
nom_jour Friday 2510 Thursday 1396 Wednesday 1288 Tuesday 1197 Monday 851 Saturday 816 Sunday 751 Name: count, dtype: int64
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
netflix['nom_jour'].value_counts().plot.bar(color=couleur)
plt.title('Répartition des ajouts en fonction du jour de la semaine')
plt.xlabel("Jours de la semaine")
plt.subplot(1,2,2)
netflix['nom_jour'].value_counts().plot.pie(autopct = '%1.1f%%',cmap = 'Set1')
plt.title('Répartition des ajouts en fonction du jour de la semaine')
plt.show()

Quel est les top 5 pays producteurs de documentaires
toppaysdoc = pd.merge(liste_pays, netflix , how='inner', left_index=True, right_index=True)
toppaysdoc[toppaysdoc['listed_in'].str.contains('Documentaries') == True]['pays'].value_counts().head(5)
pays United States 511 United Kingdom 127 France 44 Canada 42 India 27 Name: count, dtype: int64
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
toppaysdoc[toppaysdoc['listed_in'].str.contains('Documentaries') == True]['pays'].value_counts().head(5).plot.bar(color = couleur)
plt.title('Top 5 pays producteurs de documentaires ')
plt.xlabel("Pays")
plt.subplot(1,2,2)
toppaysdoc[toppaysdoc['listed_in'].str.contains('Documentaries') == True]['pays'].value_counts().head(5).plot.pie(
autopct = '%1.1f%%',cmap = 'Set1')
plt.title('Top 5 pays producteurs de documentaires ')
plt.show()

Combien de shows ont pour thématique la drogue
showdrogue = netflix[netflix['description'].str.contains('drug')]
print(len(showdrogue))
showdrogue[['type','title','description']].head(3)
158
| type | title | description | |
|---|---|---|---|
| show_id | |||
| s3 | TV Show | Ganglands | To protect his family from a powerful drug lor... |
| s18 | TV Show | Falsa identidad | Strangers Diego and Isabel flee their home in ... |
| s37 | Movie | The Stronghold | Tired of the small-time grind, three Marseille... |
Pour chaque année, analyser si Netflix se concentre sur les series plutôt que sur les films
data=netflix.groupby('annee_ajout')['type'].value_counts()
data
annee_ajout type
2008.0 Movie 1
TV Show 1
2009.0 Movie 2
2010.0 Movie 1
2011.0 Movie 13
2012.0 Movie 3
2013.0 Movie 6
TV Show 5
2014.0 Movie 19
TV Show 5
2015.0 Movie 56
TV Show 26
2016.0 Movie 253
TV Show 176
2017.0 Movie 839
TV Show 349
2018.0 Movie 1237
TV Show 412
2019.0 Movie 1424
TV Show 602
2020.0 Movie 1284
TV Show 595
2021.0 Movie 993
TV Show 505
2024.0 Movie 1
TV Show 1
Name: count, dtype: int64
plt.figure(figsize = (12,4))
sns.countplot(x= 'annee_ajout', hue = 'type', data = netflix,palette=couleur)
plt.title("Nombre de productions par année selon le type");

Quelle est la tendance des acquisitions de Netflix de 2011 à 2021
df = netflix.groupby(['annee_ajout','type']).size().reset_index(name = 'Nombre de productions')
df = df[df['annee_ajout']>=2011]
sns.set_style("white")
data=df
plt.figure(figsize=(12, 4))
sns.lineplot(x=data["annee_ajout"], y=data["Nombre de productions"],hue=data["type"],palette=couleur)
plt.title("Tendance d'ajout sur Netflix par année à partir de 2011")
plt.xlabel('Année ajout')
plt.ylabel('Shows ajoutés')
plt.legend()
plt.show()

Quel est le nombre de production sur Netflix de chaque type selon la classification (rating)
plt.figure(figsize = (12,4))
sns.countplot(x = 'rating', hue = 'type', data = netflix,palette=couleur)
plt.title("Nombre de productions selon le type et la catégorie d'évaluation");

Quel est le nombre de productions du top 10 pays producteurs selon le type (Movie ou Show TV)
pays = netflix.set_index('title').country.str.split(', ', expand = True).stack().reset_index(level = 1, drop = True)
pays.value_counts().head(10)
United States 4521 India 1046 United Kingdom 804 Canada 445 France 393 Japan 318 South Korea 232 Spain 232 Germany 226 Mexico 169 Name: count, dtype: int64
data_producteurs = netflix[(netflix['country']=="United States")|(netflix['country']=="India")
|(netflix['country']=="United Kingdom")|(netflix['country']=="Canada")
|(netflix['country']=="France")|(netflix['country']=="Japan")
|(netflix['country']=="Spain")|(netflix['country']=="South Korea")
|(netflix['country']=="Germany")|(netflix['country']=="Mexico")]
plt.figure(figsize = (12,4))
sns.countplot(x = 'country', hue = 'type', data = data_producteurs,palette=couleur);

Analyse statistique des donnés
L'objectif de cette analyse exploratoire de ce jeu de données est de mieux connaitre le type de contenu rependu sur Netflix, determiner la corrélation entre certaines variables et de pouvoir répondre à certaines questions concernant les differents shows. La démarche suivante sera suivie:
- Analyse univariée
- Analyse bivariée
- Analyse multivariée
Analyse univariée
Dans Cette partie du projet on va procéder à l'étude de certaines variables quantitative ou qualitative.
Pour les variables quantitatives, on va s'intéresser à identifier:
- La modalité;
- Les valeurs extrêmes (Maximum et Minimum);
- L'étendue des valeurs;
- La moyenne et la médiane;
- Les quartiles;
- Les valeurs aberrantes;
- La distribution.
Pour les variables qualitatives, on va s'intéresser à identifier:
- Le nombre de valeurs
- Les valeurs uniques
- La valeur la plus fréquente
- La modalité de la valeur la plus fréquente
- La répartition des valeurs
Analyse univariée des variables quantitatives
Identification des colonnes de type numerique
col_number = netflix.select_dtypes(include=np.number).columns.tolist()
col_number
['release_year', 'duree_film', 'duree_serie', 'annee_ajout', 'mois_ajout', 'jour_ajout']
Considération de la variable "release_year"
Modalité de "release_year"
netflix['release_year'].unique()
array([2020, 2021, 1993, 2018, 1996, 1998, 1997, 2010, 2013, 2017, 1975,
1978, 1983, 1987, 2012, 2001, 2014, 2002, 2003, 2004, 2011, 2008,
2009, 2007, 2005, 2006, 1994, 2015, 2019, 2016, 1982, 1989, 1990,
1991, 1999, 1986, 1992, 1984, 1980, 1961, 2000, 1995, 1985, 1976,
1959, 1988, 1981, 1972, 1964, 1945, 1954, 1979, 1958, 1956, 1963,
1970, 1973, 1925, 1974, 1960, 1966, 1971, 1962, 1969, 1977, 1967,
1968, 1965, 1946, 1942, 1955, 1944, 1947, 1943, 2024], dtype=int64)
Données statistiques de "release_year"
release_year_max=netflix['release_year'].max()
release_year_min=netflix['release_year'].min()
etendue_release_year=netflix['release_year'].max()-netflix['release_year'].min()
moyenne_release_year=netflix['release_year'].mean()
mediane_release_year=netflix['release_year'].median()
print(f'la valeur maximale de release_year est: {"%.0f"% release_year_max}')
print(f'la valeur minimale de release_year est: {"%.0f"% release_year_min}')
print(f'la valeur moyenne de release_year est : {"%.0f"% moyenne_release_year}')
print(f'la valeur mediane de release_year est: {"%.0f"% mediane_release_year}')
print('l\'étendue de release_year: '+ str("%.0f"% etendue_release_year))
la valeur maximale de release_year est: 2024 la valeur minimale de release_year est: 1925 la valeur moyenne de release_year est : 2014 la valeur mediane de release_year est: 2017 l'étendue de release_year: 99
Calcul des quartiles
quartiles=netflix['release_year'].quantile([0.25, 0.5, 0.75])
quartiles
0.25 2013.0 0.50 2017.0 0.75 2019.0 Name: release_year, dtype: float64
Valeurs extremes de "release_year"
# Fonction permettant de retrouver les valeurs extremes basée sur IQR (interquartile range: Q3-Q1)
def valeurs_extreme(data,colonne):
#calcul de l'IQR de Q1 et Q3
iqr =stats.iqr(data[colonne])
q1=data[colonne].quantile(0.25)
q3=data[colonne].quantile(0.75)
#calcul de Q1-1.5IQR et de Q3+1.5IQR
lower=q1 - 1.5*iqr
upper=q3 + 1.5*iqr
#dataframe des valeurs aberrantes
df_extreme=data[(data[colonne]< lower) | (data[colonne]> upper)]
return df_extreme[colonne].unique()
valeurs_extreme(data = netflix,colonne='release_year')
array([1993, 1996, 1998, 1997, 1975, 1978, 1983, 1987, 2001, 2002, 2003,
1994, 1982, 1989, 1990, 1991, 1999, 1986, 1992, 1984, 1980, 1961,
2000, 1995, 1985, 1976, 1959, 1988, 1981, 1972, 1964, 1945, 1954,
1979, 1958, 1956, 1963, 1970, 1973, 1925, 1974, 1960, 1966, 1971,
1962, 1969, 1977, 1967, 1968, 1965, 1946, 1942, 1955, 1944, 1947,
1943], dtype=int64)
Distribution des valeurs de "release_year"
data=netflix
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
ax = sns.countplot(y="release_year", data=netflix, palette="Spectral", order=netflix['release_year'].value_counts().index[0:15])
plt.title('Distribution countplot de la variable "release_year" ')
plt.subplot(1,2,2)
sns.boxplot(data=data[['release_year']], showmeans=True,palette=colors).set(xticklabels=[])
plt.title('Distribution boxplot de la variable "release_year" ')
plt.show()

Renseignement sur des valeurs de "release_year"
- Les années de forte sortie de shows s'étallent entre 2016 et 2020. L'année 2018 étant celle qui a été le plus prolifique.
- Certaines valeurs extrêmes sont aussi identifiées pour certaines années lointaines
Considération de la variable "annee_ajout"
Modalité de "annee_ajout"
netflix['annee_ajout'].unique()
array([2021., 2020., 2019., 2018., 2017., 2016., 2015., 2014., 2013.,
2012., 2011., 2009., 2008., 2010., 2024.])
Données statistiques de "annee_ajout"
# identification des valeurs extemes,l'etendue de ses valeurs,la moyenne et la mediane de la variable "annee_ajout"
annee_ajout_max=netflix['annee_ajout'].max()
annee_ajout_min=netflix['annee_ajout'].min()
etendue_annee_ajout=netflix['annee_ajout'].max()-netflix['annee_ajout'].min()
moyenne_annee_ajout=netflix['annee_ajout'].mean()
mediane_annee_ajout=netflix['annee_ajout'].median()
print(f'la valeur maximale de annee_ajout est: {"%.0f"% annee_ajout_max}')
print(f'la valeur minimale de annee_ajout est: {"%.0f"% annee_ajout_min}')
print(f'la valeur moyenne de annee_ajout est : {"%.0f"% moyenne_annee_ajout}')
print(f'la valeur mediane de annee_ajout est: {"%.0f"% mediane_annee_ajout}')
print('l\'étendue de annee_ajout: '+ str("%.0f"% etendue_annee_ajout))
la valeur maximale de annee_ajout est: 2024 la valeur minimale de annee_ajout est: 2008 la valeur moyenne de annee_ajout est : 2019 la valeur mediane de annee_ajout est: 2019 l'étendue de annee_ajout: 16
Calcul des quartiles
quartiles=netflix['annee_ajout'].quantile([0.25, 0.5, 0.75])
quartiles
0.25 2018.0 0.50 2019.0 0.75 2020.0 Name: annee_ajout, dtype: float64
Valeurs extremes de "annee_ajout"
valeurs_extreme(data = netflix,colonne='annee_ajout')
array([2014., 2013., 2012., 2011., 2009., 2008., 2010., 2024.])
Distribution des valeurs de "annee_ajout"
data=netflix
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
ax = sns.countplot(y="annee_ajout", data=netflix, palette="pastel", order=netflix['annee_ajout'].value_counts().index[0:15])
plt.title('Distribution countplot de la variable "annee_ajout" ')
plt.subplot(1,2,2)
sns.boxplot(data=data[['annee_ajout']], showmeans=True,palette=colors).set(xticklabels=[])
plt.title('Distribution boxplot de la variable "annee_ajout" ')
plt.show()

Renseignement sur des valeurs de "annee_ajout"
- Les années d'ajout de shows s'étallent entre 2014 et 2019. L'année 2019 étant celle pour laquelle le plus grand nombre de shows a été ajouté.
- Certaines valeurs extrêmes sont aussi identifiées pour pour l'année 2024 et avant 2014
Résumé des données statistiques de certaines variables numeriques
netflix[['release_year', 'duree_film', 'duree_serie', 'annee_ajout' ,'mois_ajout' , 'jour_ajout']].describe()
| release_year | duree_film | duree_serie | annee_ajout | mois_ajout | jour_ajout | |
|---|---|---|---|---|---|---|
| count | 8809.000000 | 8809.000000 | 8809.000000 | 8809.000000 | 8809.000000 | 8809.000000 |
| mean | 2014.181292 | 96.664661 | 1.232376 | 2018.873198 | 6.654785 | 3.018163 |
| std | 8.818932 | 24.003745 | 0.940518 | 1.575073 | 3.434465 | 1.726835 |
| min | 1925.000000 | 3.000000 | 1.000000 | 2008.000000 | 1.000000 | 0.000000 |
| 25% | 2013.000000 | 90.000000 | 1.000000 | 2018.000000 | 4.000000 | 2.000000 |
| 50% | 2017.000000 | 90.000000 | 1.000000 | 2019.000000 | 7.000000 | 3.000000 |
| 75% | 2019.000000 | 106.000000 | 1.000000 | 2020.000000 | 10.000000 | 4.000000 |
| max | 2024.000000 | 312.000000 | 17.000000 | 2024.000000 | 12.000000 | 6.000000 |
Analyse univariée des variables qualitatives
Identification des colonnes de type object
col_objet = netflix.select_dtypes(include="object").columns.tolist()
col_objet
['type', 'title', 'director', 'cast', 'country', 'rating', 'listed_in', 'description', 'nom_mois', 'nom_mois_abr', 'nom_jour']
On va s'intéresser à identifier pour certaines de ces variables:
- Le nombre de valeurs
- Les valeurs uniques
- La valeur la plus fréquente
- La modalité de la valeur la plus fréquente
- La répartition des valeurs
Résumé des données des variables catégorielles
netflix.describe(include='O')
| type | title | director | cast | country | rating | listed_in | description | nom_mois | nom_mois_abr | nom_jour | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 8809 | 8809 | 8809 | 8809 | 8809 | 8809 | 8809 | 8809 | 8809 | 8809 | 8809 |
| unique | 2 | 8806 | 4529 | 7694 | 748 | 18 | 516 | 8777 | 12 | 12 | 7 |
| top | Movie | 22-Jul | Rajiv Chilaka | David Attenborough | United States | TV-MA | Dramas, International Movies | Paranormal activity at a lush, abandoned prope... | July | Jul | Friday |
| freq | 6132 | 2 | 2653 | 844 | 3650 | 3212 | 362 | 4 | 837 | 837 | 2510 |
Répartition des valeurs certaines colonnes catégorielles
Répartition des valeurs de la colonne "type"
# Valeurs uniques
df=netflix['type'].value_counts()
df
type Movie 6132 TV Show 2677 Name: count, dtype: int64
data=df
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
sns.barplot(x=data.index,y=data.values,palette=colors).set(title='Répartition des valeurs de la colonne "type" ')
plt.title('Distribution des valeurs de la colonne "type" ')
plt.subplot(1,2,2)
plt.pie(x=data.values, labels=data.index, autopct='%1.1f%%', colors=colors)
plt.title('Pourcentage des valeurs de la la variable "type" ')
plt.show()

Renseignement sur des valeurs de "type"
Près de 70% des shows disponibles sur Netflix sont des films. Les séries représentent un peu plus que 30%
Répartition des valeurs de la colonne "rating"
# Valeurs uniques
df=netflix['rating'].value_counts()
df
rating TV-MA 3212 TV-14 2160 TV-PG 863 R 799 PG-13 490 TV-Y7 334 TV-Y 307 PG 287 TV-G 220 NR 80 G 41 TV-Y7-FV 6 NC-17 3 UR 3 74 min 1 84 min 1 66 min 1 A 1 Name: count, dtype: int64
data=df.head(10)
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
sns.barplot(y=data.index,x=data.values,palette=colors)
plt.title('répartition des valeurs de la colonne "rating" ')
plt.xlabel('Fréquence')
plt.ylabel('Evaluation')
plt.subplot(1,2,2)
plt.pie(x=data.values, labels=data.index, autopct='%1.1f%%', colors=colors)
plt.title("Distibution des categories d'evaluation")
plt.show()

Renseignement sur des valeurs de "rating"
- Les deux classifications "TV-MA" et "TV-14" apparaissent dans 62% des cas.
- Certaines autres n'apparaissent qu'une seul fois dans le jeu de donnée
Analyse bivariée
Dans cette partie du projet, on va s'intéresser aux liens ou relations entre les variables deux à deux. On cherchera à identifier la fluctuation entre les deux variables. Du point de vue visuel, la représentation graphique en nuage de points permettra d'observer la corrélation entre les deux variables. Nous allons procéder de la manière suivante:
- Corrélation entre deux variables quantitatives
- Corrélation entre une variable quantitative et une variable qualitative
- Corrélation entre une variable qualitative et une variable quantitative
Matrice de corrélation des variables numériques deux à deux
netflix_num=netflix[['release_year', 'duree_film', 'duree_serie', 'annee_ajout', 'mois_ajout', 'jour_ajout']]
corr=netflix_num.corr()
corr
| release_year | duree_film | duree_serie | annee_ajout | mois_ajout | jour_ajout | |
|---|---|---|---|---|---|---|
| release_year | 1.000000 | -0.219014 | 0.037928 | 0.111735 | -0.039297 | 0.025474 |
| duree_film | -0.219014 | 1.000000 | -0.068608 | 0.097437 | -0.001608 | 0.007660 |
| duree_serie | 0.037928 | -0.068608 | 1.000000 | 0.029626 | 0.007088 | 0.023965 |
| annee_ajout | 0.111735 | 0.097437 | 0.029626 | 1.000000 | -0.160778 | -0.048075 |
| mois_ajout | -0.039297 | -0.001608 | 0.007088 | -0.160778 | 1.000000 | 0.030863 |
| jour_ajout | 0.025474 | 0.007660 | 0.023965 | -0.048075 | 0.030863 | 1.000000 |
Carte de chaleur
plt.figure(figsize=(12,4))
sns.heatmap(corr,xticklabels=corr.columns,yticklabels=corr.columns,annot=True, cmap="flare")
plt.title('Matrice de corrélation des variables numériques deux à deux ')
Text(0.5, 1.0, 'Matrice de corrélation des variables numériques deux à deux ')

Vérification de la corrélation des variables numériques 'release_year' et 'duree_film'
netflix.plot(kind='scatter',x='release_year',y='duree_film',figsize=(12,4),color="#DC143C")
plt.title("Corrélation des variables numériques 'release_year' et 'duree_film'")
plt.show()

Renseignement sur la corrélation des variables 'release_year' et'duree_film'
On remarque une corrélation tres faible entre ces deux variables
Vérification de la corrélation entre une variable numériques 'release_year' et la variable catégorielle 'rating'
netflix.plot(kind='scatter',x='release_year',y='rating',figsize=(12,4),color="#DC143C");

list_values = ['74 min', '66 min','84 min','A']
data = netflix[~netflix['rating'].isin(list_values)]
plt.figure(figsize=(12, 4))
sns.boxplot(x='rating', y='release_year', data=data, palette='pastel' )
plt.title('Distribution de "Release Years" par "Rating" ')
plt.xlabel('Rating')
plt.ylabel('Release Year')
plt.xticks(rotation=45)
plt.show()

Renseignement sur la corrélation des variables 'release_year' et'rating'
- Le diagramme en boîte montre que l'année de sortie médiane de la plupart des classifications est relativement récente.
- Les contenus classés « TV-Y » et « TV-Y7 » ont tendance à être plus anciens que les autres classifications.
- Il n'y a probablement pas de relation linéaire simple et forte entre l'année de sortie et la notation d'un contenu sur Netflix.
- La distribution des différentes notations sur la plateforme a clairement évolué au fil du temps
Principales conclusions de l'analyse des données
- La majorité du contenu sur Netflix est classée comme "Films"(70%) par rapport aux "Séries télévisées"(30%) .
- Les États-Unis possèdent le plus grand nombre de titres, suivis par l'Inde.
- Les genres les plus fréquents sont "International Movies" (Films internationaux) et "Dramas" (Drames).
- "TV-MA" et "TV-14" sont très fréquents, cela indique une forte présence de contenu destiné à un public adulte sur Netflix
- La distribution des années de sortie culmine au cours des dernières années.
TROISIEME PARTIE : POWER BI - DAX
Visualisation des donnés avec POWER BI
Cette partie du projet est consacrée a l'utilisation de l'outil POWER BI Desktop et le langage DAX pour visualisation des données a travers des rapports et d'un tableau de bord. Elle comprend les étapes suivantes:
- Téléchargement et installation du logiciel : Oracle Data Access Client;
- Connexion de Power BI à la Base de données Oracle 19C;
- Chargement des différentes tables dans Power BI;
- Définition les indicateurs clés requis(KPI);
- Définition les rapports requis;
- Création de nouvelles colonnes avec DAX;
- Création de nouvelles mesures avec DAX;
- Création de la relation entre les tables;
- Création des rapports avec Power BI Desktop;
- Création du tableau de bord avec Power BI Service;
- Création de l'application Power BI Service;
Connexion de Power BI à la Base de données Oracle 19C;

Chargement des différentes tables dans Power BI;

Définition des indicateurs clés requis(KPI);
Les indicateurs clés sont les suivants:
- Le nombre de genres
- le nombres de shows
- Le nombre de pays
- Le nombre d'acteurs
- Le nombre de directeurs
- Le nombre de compagnies
Définition des rapports requis
Les rapports requis sont les suivants:
- La répartition des shows ajoutés par année
- La répartition des shows sortis par année
- La répartition des shows par genres
- La répartition des shows par pays
- La répartition des shows par acteur
- La répartition des shows par compagnie
- La répartition des shows par durée
- La répartition des shows par classification
- La comparaison des shows ajoutés d'une année à l'autre
- La comparaison des shows ajoutés d'un trimestre à l'autre
- La comparaison des shows ajoutés d'un mois à l'autre
- Les 5 pays avec le plus de shows
- les 5 acteurs avec le plus de show
- les 5 compagnies avec le plus de show
- les 5 genres les plus fréquents
Création de nouvelles colonnes

Création de nouvelles mesures avec DAX

Création de la relation entre les tables avec Power Query

Création des rapports avec Power BI Desktop













Publication des rapports Power BI Destop sur Power BI Service
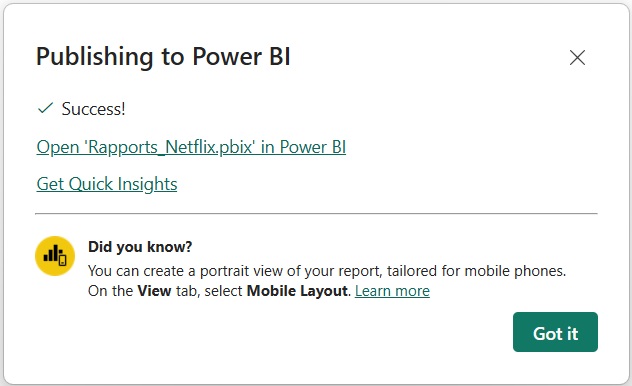
Création du tableau de bord dans Power BI Service

Création du tableau de bord pour appareils mobiles dans Power BI Service

Création de l'application dans Power BI Service
