Projet " Panorama des festivals"
Réalisation: Harald Valcourt
Présentation du projet
Le projet consiste à analyser le " Panorama des festivals", photographie des événements culturels répertoriés par le mistère de la culture du gouvernement francais. Il présente les informations clés sur les festivales dans tous les domaines culturels et sur tout le territoire Francais. le panorama des festivals compile plusieurs milliers de manifestations et intègre les spectacles de cinémas, de salons, de rencontres le domaine des arts visuels, du livre, du patrimoine etc.
Le projet est divisé en quatres étapes principales:
- Première partie consacrée au langage Python
- Deuxième partie consacrée au langage SQL
- Troisième partie consacrée au langage DAX
- Quatrième partie est consacrée à Power BI Desktop et Power BI Service
La démarche appliquée
La démarche appliquée est la suivante:
- Identification de la source de données
- Installation et importation des libraires
- Collecte des donnés
- Préparation des données
- Modélisation des données
- Transmision des données sur la plateforme cloud de Snowflake
- Création de la Base de données
- Création des tables
- Chargement des données
- Modélisation des données
- Manipilation des données
- Connexion de Power BI à Snoflake
- Définition des besoins
- Définition des indicateurs
- Définition des rapports
- Création des rapports
- Réalisation du tableau de bord
Identification de la source de données
Le jeu de données est disponible sur le site du gouvernement Français: data.gouv.fr à l'url suivant:
Il est de format csv et est initialement constité de Colonnes : 37 Colonnes et 3136 lignes. Les principales colonnes sont les suivantes:
- Nom de la manifestation
- Région
- Domaine
- Complément domaine
- Département
- Périodicité
- Mois habituel de début
- Site web
- N° Identification
- Commune principale
- Autres communes
- N° de l'édition 2018
- Date de création
- Soutenu en 2017 par le ministère de la culture
- Soutenu en 2017 par le Centre national du cinéma
- Soutenu en 2017 par le Centre national du livre
- Soutenu en 2017 par le Centre national des variétés
- Soutenu en 2018 par le ministère de la culture
- Soutenu en 2018 par le Centre national du cinéma
- Soutenu en 2018 par le Centre national du livre
- Soutenu en 2018 par le Centre national des variétés
- Code postal
- Code INSEE
- coordonnees_insee
- Libellé commune pour calcul CP, INSEE
- Dépt SK
- Nom Département
- Commentaires
- N° de l'édition 2019
- Check édition
- Mois indicatif en chiffre, y compris double mois
- Mois indicatif
- Date début ancien
- Date de fin ancien
- Soutien 2017 MCC à la structure
- Part festival sur soutien à la structure
- Enquête DRAC 2017
Première partie:Le langage Python
Installation et importation des librairies
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import os
from pandasql import sqldf
import snowflake.connector
from snowflake.connector import connect,DictCursor
from snowflake.connector.pandas_tools import write_pandas
from warnings import filterwarnings
filterwarnings('ignore')
Collecte des données
Lecture du fichier 'panorama-des-festivals.csv'
df=pd.read_csv('panorama-des-festivals.csv',sep=';', encoding='UTF-8')
df.head()
| Nom de la manifestation | Région | Domaine | Complément domaine | Département | Périodicité | Mois habituel de début | Site web | N° Identification | Commune principale | ... | Commentaires | N° de l'édition 2019 | Check édition | Mois indicatif en chiffre, y compris double mois | Mois indicatif | Date début ancien | Date de fin ancien | Soutien 2017 MCC à la structure | Part festival sur soutien à la structure | Enquête DRAC 2017 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | FESTIVAL DIVERSCENES | Pays de la Loire | Musiques actuelles | Musiques traditionnelles et du monde | 53 | Biennale années impaires | 01 (janvier) | http://diverscene.jimdo.com | LD085 | CHANGE | ... | NaN | 29.0 | -20.0 | 1.0 | NaN | 2019-01-06 | 2019-02-02 | NaN | NaN | NaN |
| 1 | Paris des femmes | Île-de-France | Transdisciplinaire | NaN | 75 | Annuelle | 01 (janvier) | www.parisdesfemmes.com | HA026 | PARIS | ... | NaN | 8.0 | 0.0 | 1.0 | NaN | 2019-01-10 | 2019-01-12 | NaN | NaN | NaN |
| 2 | FESTIVAL A PARTIR DU REEL | Normandie | Théâtre | NaN | 14 | Annuelle | 01 (janvier) | https://www.larenaissance-mondeville.fr | IG002 | MONDEVILLE | ... | Montant de la subvention non indiqué par la DRAC | 15.0 | 0.0 | 1.0 | NaN | 2019-01-10 | 2019-02-07 | 0.0 | NaN | NaN |
| 3 | FESTIVAL TRACE | Île-de-France | Musiques actuelles | NaN | 92 | Annuelle | 01 (janvier) | festivaltrace.com | NaN | CHAVILLE | ... | NaN | 19.0 | 0.0 | 1.0 | NaN | 2019-01-12 | 2019-02-16 | NaN | NaN | NaN |
| 4 | Festival International du Film de comédie de l... | Auvergne-Rhône-Alpes | Cinéma et audiovisuel | NaN | 38 | Annuelle | 01 (janvier) | http://www.festival-alpedhuez.com | AJ031 | HUEZ | ... | NaN | 22.0 | 0.0 | 1.0 | NaN | 2019-01-15 | 2019-01-20 | NaN | NaN | NaN |
5 rows × 37 columns
Affichage des colonnes du DataFrame
df.columns
Index(['Nom de la manifestation', 'Région', 'Domaine', 'Complément domaine',
'Département', 'Périodicité', 'Mois habituel de début', 'Site web',
'N° Identification', 'Commune principale', 'Autres communes',
'N° de l'édition 2018', 'Date de création',
'Soutenu en 2017 par le ministère de la culture ',
'Soutenu en 2017 par le Centre national du cinéma ',
'Soutenu en 2017 par le Centre national du livre ',
'Soutenu en 2017 par le Centre national des variétés ',
'Soutenu en 2018 par le ministère de la culture ',
'Soutenu en 2018 par le Centre national du cinéma ',
'Soutenu en 2018 par le Centre national du livre ',
'Soutenu en 2018 par le Centre national des variétés ', 'Code postal',
'Code INSEE', 'coordonnees_insee',
'Libellé commune pour calcul CP, INSEE', 'Dépt SK', 'Nom Département',
'Commentaires', 'N° de l'édition 2019', 'Check édition',
'Mois indicatif en chiffre, y compris double mois', 'Mois indicatif',
'Date début ancien', 'Date de fin ancien',
'Soutien 2017 MCC à la structure',
'Part festival sur soutien à la structure', 'Enquête DRAC 2017'],
dtype='object')
Préparation des données
Suppression des colonnes inutiles
df.drop([
'Soutenu en 2017 par le ministère de la culture ',
'Soutenu en 2017 par le Centre national du cinéma ',
'Soutenu en 2017 par le Centre national du livre ',
'Soutenu en 2017 par le Centre national des variétés ',
'Soutenu en 2018 par le ministère de la culture ',
'Soutenu en 2018 par le Centre national du cinéma ',
'Soutenu en 2018 par le Centre national du livre ',
'Soutenu en 2018 par le Centre national des variétés ',
'Commentaires', "N° de l'édition 2019", 'Check édition',
'Mois indicatif en chiffre, y compris double mois', 'Mois indicatif',
'Soutien 2017 MCC à la structure','Part festival sur soutien à la structure',
'Enquête DRAC 2017','Libellé commune pour calcul CP, INSEE'
],
axis=1,inplace=True)
Affichage des colonnes retenues
df.columns
Index(['Nom de la manifestation', 'Région', 'Domaine', 'Complément domaine',
'Département', 'Périodicité', 'Mois habituel de début', 'Site web',
'N° Identification', 'Commune principale', 'Autres communes',
'N° de l'édition 2018', 'Date de création', 'Code postal', 'Code INSEE',
'coordonnees_insee', 'Dépt SK', 'Nom Département', 'Date début ancien',
'Date de fin ancien'],
dtype='object')
Renommage des colonnes
df.rename(mapper= {
'Nom de la manifestation' :'NomManif',
'Région':'Region',
'Domaine':'Domaine',
'Complément domaine':'ComplementDomaine',
'Département':'Departement',
'Périodicité':'Periodicite',
'Mois habituel de début':'MoisHabituel',
'Site web':'SiteWeb',
'N° Identification':'NoId',
'Commune principale':'Commune',
'Autres communes':'AutreCommunes',
"N° de l'édition 2018":'NoEdition',
'Date de création':'DateCreation',
'Code postal':'CodePostal',
'Code INSEE':'CodeINSEE',
'coordonnees_insee':'CoordonnesInsee',
'Dépt SK':'DeptSK',
'Nom Département':'NomDeptartement',
'Date début ancien':'DateDebut',
'Date de fin ancien':'DateFin'},
axis=1, inplace=True)
Affichage des informations sur le DataFrame
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 3136 entries, 0 to 3135 Data columns (total 20 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 NomManif 3136 non-null object 1 Region 3136 non-null object 2 Domaine 3136 non-null object 3 ComplementDomaine 2044 non-null object 4 Departement 3136 non-null int64 5 Periodicite 2626 non-null object 6 MoisHabituel 3136 non-null object 7 SiteWeb 2914 non-null object 8 NoId 3098 non-null object 9 Commune 3136 non-null object 10 AutreCommunes 326 non-null object 11 NoEdition 2383 non-null float64 12 DateCreation 2671 non-null object 13 CodePostal 3136 non-null int64 14 CodeINSEE 3136 non-null object 15 CoordonnesInsee 3134 non-null object 16 DeptSK 3112 non-null float64 17 NomDeptartement 3136 non-null object 18 DateDebut 2797 non-null object 19 DateFin 2797 non-null object dtypes: float64(2), int64(2), object(16) memory usage: 490.1+ KB
Nombre de valeurs nulles par colonne
df.isnull().sum()
NomManif 0 Region 0 Domaine 0 ComplementDomaine 1092 Departement 0 Periodicite 510 MoisHabituel 0 SiteWeb 222 NoId 38 Commune 0 AutreCommunes 2810 NoEdition 753 DateCreation 465 CodePostal 0 CodeINSEE 0 CoordonnesInsee 2 DeptSK 24 NomDeptartement 0 DateDebut 339 DateFin 339 dtype: int64
Recherche des colonnes numérique
dfnum=df.select_dtypes(include=['int64','float64']).columns
dfnum
Index(['Departement', 'NoEdition', 'CodePostal', 'DeptSK'], dtype='object')
Recherche des colonnes categorielles
dfcat=df.select_dtypes(include=['object']).columns
dfcat
Index(['NomManif', 'Region', 'Domaine', 'ComplementDomaine', 'Periodicite',
'MoisHabituel', 'SiteWeb', 'NoId', 'Commune', 'AutreCommunes',
'DateCreation', 'CodeINSEE', 'CoordonnesInsee', 'NomDeptartement',
'DateDebut', 'DateFin'],
dtype='object')
Affichage du nombre de valeurs des colonnes numériques
df[dfnum].isnull().sum().sort_values(ascending=False)[:10]
NoEdition 753 DeptSK 24 Departement 0 CodePostal 0 dtype: int64
Considération sur la colonne 'AutreCommunes'
#Identification du nombre de valeur nulles
df['AutreCommunes'].isnull().sum()
2810
# Suppression de la colonne 'AutreCommunes' pour laquelle plus que 90% des valeurs sont manquantes
df.drop('AutreCommunes', axis=1,inplace=True)
df.columns
Index(['NomManif', 'Region', 'Domaine', 'ComplementDomaine', 'Departement',
'Periodicite', 'MoisHabituel', 'SiteWeb', 'NoId', 'Commune',
'NoEdition', 'DateCreation', 'CodePostal', 'CodeINSEE',
'CoordonnesInsee', 'DeptSK', 'NomDeptartement', 'DateDebut', 'DateFin'],
dtype='object')
Considération sur les colonnes 'CodePostal', 'CodeINSEE'
df[['CodePostal', 'CodeINSEE']]
| CodePostal | CodeINSEE | |
|---|---|---|
| 0 | 53810 | 53054 |
| 1 | 75001 | 75101 |
| 2 | 14120 | 14437 |
| 3 | 92370 | 92022 |
| 4 | 38750 | 38191 |
| ... | ... | ... |
| 3131 | 13001 | 13201 |
| 3132 | 34200 | 34301 |
| 3133 | 75001 | 75101 |
| 3134 | 13001 | 13201 |
| 3135 | 67100 | 67482 |
3136 rows × 2 columns
#Suppression de la colonne 'CodeINSEE' étant un doublon de la colonne 'CodePostal'
df.drop('CodeINSEE',axis=1,inplace=True)
df.columns
Index(['NomManif', 'Region', 'Domaine', 'ComplementDomaine', 'Departement',
'Periodicite', 'MoisHabituel', 'SiteWeb', 'NoId', 'Commune',
'NoEdition', 'DateCreation', 'CodePostal', 'CoordonnesInsee', 'DeptSK',
'NomDeptartement', 'DateDebut', 'DateFin'],
dtype='object')
Considération sur les colonnes 'Departement' et 'DeptSK'
df[['Departement','DeptSK']]
| Departement | DeptSK | |
|---|---|---|
| 0 | 53 | 53.0 |
| 1 | 75 | 75.0 |
| 2 | 14 | 14.0 |
| 3 | 92 | 92.0 |
| 4 | 38 | 38.0 |
| ... | ... | ... |
| 3131 | 13 | 13.0 |
| 3132 | 34 | 34.0 |
| 3133 | 75 | 75.0 |
| 3134 | 13 | 13.0 |
| 3135 | 67 | 67.0 |
3136 rows × 2 columns
Suppression de la colonne 'DeptSK' étant un doublon de la colonne 'Departement'
df.drop('DeptSK',axis=1,inplace=True)
df.columns
Index(['NomManif', 'Region', 'Domaine', 'ComplementDomaine', 'Departement',
'Periodicite', 'MoisHabituel', 'SiteWeb', 'NoId', 'Commune',
'NoEdition', 'DateCreation', 'CodePostal', 'CoordonnesInsee',
'NomDeptartement', 'DateDebut', 'DateFin'],
dtype='object')
Modification du type des colonnes 'DateCreation' , 'DateDebut' et 'DateFin'
df['DateCreation'] = pd.to_datetime(df['DateCreation'])
df['DateDebut'] = pd.to_datetime(df['DateDebut'])
df['DateFin'] = pd.to_datetime(df['DateFin'])
df[['DateCreation' , 'DateDebut' ,'DateFin']].info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 3136 entries, 0 to 3135 Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 DateCreation 2671 non-null datetime64[ns] 1 DateDebut 2797 non-null datetime64[ns] 2 DateFin 2797 non-null datetime64[ns] dtypes: datetime64[ns](3) memory usage: 73.6 KB
Considération sur les valeurs de la colonne 'Periodicite'
df['Periodicite'].unique()
array(['Biennale années impaires', 'Annuelle', nan, 'Biennale',
'ANNUELLE', 'Biennale années paires', 'annuelle', 'Irrégulière',
'Bi-Annuelle', 'Bi-annuelle'], dtype=object)
Remplacer les valeurs 'ANNUELLE' par 'Annuelle'
df['Periodicite'].replace('ANNUELLE','Annuelle',inplace=True)
df['Periodicite'].replace('annuelle','Annuelle',inplace=True)
df['Periodicite'].replace('Biennale années impaires','Biennale',inplace=True)
df['Periodicite'].replace('Biennale années paires','Biennale',inplace=True)
df['Periodicite'].replace('Bi-annuelle','Bi-Annuelle',inplace=True)
df['Periodicite'].replace('Bi-Annuelle','Biennale',inplace=True)
df['Periodicite'].unique()
array(['Biennale', 'Annuelle', nan, 'Irrégulière'], dtype=object)
Nombre de valeurs nulle de la colonne "Périodicité"
df['Periodicite'].isnull().sum()
510
df['Periodicite'].fillna('Non Specifie',inplace=True)
df['Periodicite'].isnull().sum()
0
Considération sur les valeurs de la colonne 'Region'
df['Region'].unique()
array(['Pays de la Loire', 'Île-de-France', 'Normandie',
'Auvergne-Rhône-Alpes', 'Bretagne', 'Nouvelle-Aquitaine',
'Grand Est', "Provence-Alpes-Côte d'Azur", 'Polynésie française',
'Occitanie', 'Hauts-de-France', 'Mayotte', 'Centre-Val de Loire',
'Martinique', 'Bourgogne-Franche-Comté', 'Corse',
'Nouvelle Calédonie', 'Guyane', 'La Réunion', 'Guadeloupe'],
dtype=object)
Considération sur les valeurs de la colonne 'Region'
Modalité de la variable 'Region'
df['Region'].value_counts()
Region Auvergne-Rhône-Alpes 431 Île-de-France 399 Occitanie 382 Nouvelle-Aquitaine 362 Provence-Alpes-Côte d'Azur 319 Bretagne 219 Grand Est 217 Pays de la Loire 190 Hauts-de-France 167 Bourgogne-Franche-Comté 145 Normandie 128 Centre-Val de Loire 119 Corse 24 La Réunion 10 Guadeloupe 6 Martinique 5 Mayotte 4 Polynésie française 3 Nouvelle Calédonie 3 Guyane 3 Name: count, dtype: int64
Considération sur les valeurs de la colonne 'NoEdition'
# Modalité de la variable 'NoEdition'
df['NoEdition'].value_counts()
NoEdition
4.0 141
3.0 131
10.0 112
8.0 107
6.0 102
...
53.0 1
72.0 1
85.0 1
83.0 1
62.0 1
Name: count, Length: 69, dtype: int64
Considération sur la colonne 'CoordonnesInsee'
df['CoordonnesInsee']
0 48.1079801148, -0.800104772023
1 48.8626304852, 2.33629344655
2 49.1693649378, -0.310691187417
3 48.8076083562, 2.19234061062
4 45.0969425761, 6.08474810987
...
3131 43.2999009436, 5.38227869795
3132 43.3917705831, 3.64705148296
3133 48.8626304852, 2.33629344655
3134 43.2999009436, 5.38227869795
3135 48.5712679849, 7.76752679517
Name: CoordonnesInsee, Length: 3136, dtype: object
Séparez la colonne 'CoordonnesInsee' en deux colonnes distinctes 'Lattitude' et 'Logitude'
def split_part1(Coordonnes):
if pd.notnull(Coordonnes):
split_part1 = str(Coordonnes).split(',')
return split_part1[0]
else:
return np.nan
def split_part2(Coordonnes):
if pd.notnull(Coordonnes):
split_part2 = str(Coordonnes).split(',')
return split_part2[1]
else:
return np.nan
df['Lattitude'] = df['CoordonnesInsee'].apply(split_part1)
df['Longitude'] = df['CoordonnesInsee'].apply(split_part2)
df.head(3)
| NomManif | Region | Domaine | ComplementDomaine | Departement | Periodicite | MoisHabituel | SiteWeb | NoId | Commune | NoEdition | DateCreation | CodePostal | CoordonnesInsee | NomDeptartement | DateDebut | DateFin | Lattitude | Longitude | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | FESTIVAL DIVERSCENES | Pays de la Loire | Musiques actuelles | Musiques traditionnelles et du monde | 53 | Biennale | 01 (janvier) | http://diverscene.jimdo.com | LD085 | CHANGE | NaN | 2011-01-01 | 53810 | 48.1079801148, -0.800104772023 | Mayenne | 2019-01-06 | 2019-02-02 | 48.1079801148 | -0.800104772023 |
| 1 | Paris des femmes | Île-de-France | Transdisciplinaire | NaN | 75 | Annuelle | 01 (janvier) | www.parisdesfemmes.com | HA026 | PARIS | 7.0 | 2012-01-01 | 75001 | 48.8626304852, 2.33629344655 | Paris | 2019-01-10 | 2019-01-12 | 48.8626304852 | 2.33629344655 |
| 2 | FESTIVAL A PARTIR DU REEL | Normandie | Théâtre | NaN | 14 | Annuelle | 01 (janvier) | https://www.larenaissance-mondeville.fr | IG002 | MONDEVILLE | 4.0 | 2005-01-01 | 14120 | 49.1693649378, -0.310691187417 | Calvados | 2019-01-10 | 2019-02-07 | 49.1693649378 | -0.310691187417 |
Determiner nombre de valeurs nulles de la colonne 'CoordonnesInsee'
df['CoordonnesInsee'].isnull().sum()
2
Supprimer les lignes pour lesquelles 'CoordonnesInsee' sont nulles
df.dropna(subset=['CoordonnesInsee'], inplace=True)
Supprimer de la colonne CoordonnesInsee
df.drop('CoordonnesInsee', axis=1,inplace=True)
Affichage du nombre de valeurs nulles par ordre decroissant
df.isnull().sum().sort_values(ascending=False)[:10]
ComplementDomaine 1091 NoEdition 753 DateCreation 465 DateFin 339 DateDebut 339 SiteWeb 222 NoId 38 NomManif 0 Lattitude 0 NomDeptartement 0 dtype: int64
Remplacer les valeurs nulles des colonnes 'DateCreation', 'DateFin' et 'DateDebut' par la valeur minimale de la colonne correspondante
df['DateCreation']=df['DateCreation'].fillna(df['DateCreation'].min())
df['DateFin']=df['DateFin'].fillna(df['DateFin'].min())
df['DateDebut']=df['DateDebut'].fillna(df['DateDebut'].min())
df[['DateCreation','DateFin','DateDebut']]
| DateCreation | DateFin | DateDebut | |
|---|---|---|---|
| 0 | 2011-01-01 | 2019-02-02 | 2019-01-06 |
| 1 | 2012-01-01 | 2019-01-12 | 2019-01-10 |
| 2 | 2005-01-01 | 2019-02-07 | 2019-01-10 |
| 3 | 2001-01-01 | 2019-02-16 | 2019-01-12 |
| 4 | 1998-01-01 | 2019-01-20 | 2019-01-15 |
| ... | ... | ... | ... |
| 3131 | 1869-01-01 | 2018-12-15 | 2018-12-05 |
| 3132 | 2015-01-01 | 2018-12-09 | 2018-12-07 |
| 3133 | 1869-01-01 | 2018-12-12 | 2018-12-10 |
| 3134 | 2018-01-01 | 2018-12-22 | 2018-12-13 |
| 3135 | 2018-01-01 | 2019-03-03 | 2018-12-15 |
3134 rows × 3 columns
Considération sur la colonne 'ComplementDomaine'
Remplacer les valeurs manquantes de la colonne'ComplementDomaine' par 'Non Renseigné
df['ComplementDomaine']=df['ComplementDomaine'].fillna('Non Renseigné')
Suppression des lignes pour lesquelles les numéros d'identification 'NoId' ne sont pas renseignés
df.dropna(subset=['NoId'], inplace=True)
onsidération sur les valeurs de la colonne 'SiteWeb'
df['SiteWeb'].head()
0 http://diverscene.jimdo.com 1 www.parisdesfemmes.com 2 https://www.larenaissance-mondeville.fr 4 http://www.festival-alpedhuez.com 5 http://centreculturel.fougeres-communaute.bzh/ Name: SiteWeb, dtype: object
Supprimer les préfix http:// de la colonne 'SiteWeb'
df['SiteWeb']=df['SiteWeb'].str.replace('www.','')
df['SiteWeb']=df['SiteWeb'].str.replace('http://','')
df['SiteWeb']=df['SiteWeb'].str.replace('https://','')
df['SiteWeb']=df['SiteWeb'].str.replace('/','')
Remplacer les valeur nulles de la colonne 'SiteWeb' "Non Specifie"
df['SiteWeb']=df['SiteWeb'].fillna('Non Specifie')
Considération sur les valeurs de la colonne 'MoisHabituel'
df['MoisHabituel'].head(3)
0 01 (janvier) 1 01 (janvier) 2 01 (janvier) Name: MoisHabituel, dtype: object
Séparez la colonne 'MoisHabiteul' en deux colonnes distinctes 'NumMoisHabituel' et 'NomMoisHabituel'
def split_part1(var):
if pd.notnull(var):
split_part1 = str(var).split(' ')
return split_part1[0]
else:
return np.nan
def split_part2(var):
if pd.notnull(var):
split_part2 = str(var).split(' ')
return split_part2[1]
else:
return np.nan
df['NumMoisHabituel'] = df['MoisHabituel'].apply(split_part1)
df['NumMoisHabituel'] = pd.to_numeric(df['NumMoisHabituel'])
df['NomMoisHabituel'] = df['MoisHabituel'].apply(split_part2)
df['NomMoisHabituel']=df['NomMoisHabituel'].str.replace('(','')
df['NomMoisHabituel']=df['NomMoisHabituel'].str.replace(')','')
Supprimer de la colonne 'MoisHabituel'
df.drop('MoisHabituel',axis=1,inplace=True)
Considération sur les valeurs de la colonne 'NoEdition'
df['NoEdition'].value_counts()
NoEdition
4.0 139
3.0 130
10.0 112
8.0 107
2.0 100
...
53.0 1
72.0 1
85.0 1
83.0 1
62.0 1
Name: count, Length: 69, dtype: int64
Nombre de valeurs manquantes
df['NoEdition'].isnull().sum()
735
Remplacer les valeurs manquantes par 0
df['NoEdition']=df['NoEdition'].fillna(0)
Mettre en majuscule la première lettre de chaque mot des colonnes catégorielle
dfcat=df.select_dtypes(include=['object']).columns
for i in dfcat:
df[i]=df[i].str.title()
Considération sur les valeurs de la colonne 'NoId'
Recherche des valeurs dupliquées
df['NoId'].duplicated().value_counts()
NoId False 2991 True 105 Name: count, dtype: int64
Supprimer les doublons de 'NoId' en conservant la dernière occurence.
df.drop_duplicates(subset='NoId', keep='last', inplace=True)
print('Doublons supprimés')
Doublons supprimés
Renommer des collones du DataFrame
df.rename(mapper= {
'NomManif' :'NOM_MANIF',
'Region' :'REGION',
'Domaine' :'DOMAINE',
'ComplementDomaine' :'COMPLEMENT_DOMAINE',
'Departement' :'DEPARTEMENT',
'Periodicite' :'PERIODICITE',
'SiteWeb' :'SITE_WEB',
'NoId' :'NO_ID',
'Commune' :'COMMUNE',
'NoEdition' :'NO_EDITION',
'DateCreation' :'DATE_CREATION',
'CodePostal' :'CODE_POSTAL',
'NomDeptartement' :'NOM_DEPARTEMENT',
'DateDebut' :'DATE_DEBUT',
'DateFin' :'DATE_FIN',
'Lattitude' :'LATTITUDE',
'Longitude' :'LONGITUDE',
'NumMoisHabituel' :'NUM_MOIS_HABITUEL',
'NomMoisHabituel':'NOM_MOIS_HABITUEL' },
axis=1, inplace=True)
Conversion des colonnes 'DATE_CREATION', 'DATE_DEBUT' et DATE_FIN' du DataFrame en string
df['DATE_CREATION'] = df['DATE_CREATION'].astype(str)
df['DATE_DEBUT'] = df['DATE_DEBUT'].astype(str)
df['DATE_FIN'] = df['DATE_FIN'].astype(str)
print('Conversions de type effectuées')
Conversions de type effectuées
Mettre en majuscule les valeurs de la colonne 'NO_ID' du DataFrame
df['NO_ID']=df['NO_ID'].str.upper()
df['NO_ID'].head(3)
0 LD085 1 HA026 2 IG002 Name: NO_ID, dtype: object
Lecture du fichier des participants
participants=pd.read_csv('PARTICIPANTS.csv')
participants.head()
| NO_ID | NOMBRE2017 | NOMBRE2018 | PRIX | |
|---|---|---|---|---|
| 0 | AJ030 | 269 | 250 | 54 |
| 1 | MD205 | 150 | 250 | 30 |
| 2 | KD098 | 499 | 250 | 100 |
| 3 | BK006 | 454 | 250 | 91 |
| 4 | KK014 | 362 | 250 | 72 |
Recherche des valeurs dupliquées de la colonne 'NoId' de Participants
participants['NO_ID'].duplicated().value_counts()
NO_ID False 3028 True 105 Name: count, dtype: int64
Suppression des doublons de 'NO_ID' en conservant la derniere occurence.
participants.drop_duplicates(subset='NO_ID', keep='last', inplace=True)
print('Doublons supprimés')
Doublons supprimés
Deuxième partie : Langage SQL sur Snowflake
Cette partie du projet est consacrée à l'utilisation du langage SQL à travers la plateforme Snowflake. Les différents aspects suivants seront abordés:
- Connexion à la plateforme Snowflake
- Création de la Base de données
- Création du schéma
- Création des tables
- Chargement des données
- Commande de definition de données
- Commade de manipulation de données
- Commandes de contôle de Données
Connexion à la plateforme Snowflake
conn=snowflake.connector.connect(
user='VALCOURTH',
password='HARALDVALCOURT',
account='JIOLUVT-VE58757',
warehouse='COMPUTE_WH',
database='FESTIVALS',
schema='FESTIVALS_SCHEMA',
role='ACCOUNTADMIN'
)
print('Connexion établie')
Connexion établie
Création de la nouvelle Base de données et du schéma
#Création de la Base de données FESTIVALS et du SCHEMA FESTIVALS_SCHEMA
cur=conn.cursor()
cur.execute('create or replace database FESTIVALS;')
cur.execute('create or replace schema FESTIVALS_SCHEMA;')
cur.close()
print('Database et Schema créés ')
Database et Schema créés
Connexion à la nouvelle Base de données
conn=snowflake.connector.connect(
user='hvalcourt',
password='H@raldvalcourt070164',
account='JIOLUVT-VE58757',
warehouse='COMPUTE_WH',
database='FESTIVALS',
schema='FESTIVALS_SCHEMA',
role='ACCOUNTADMIN'
)
print('Connexion établie')
Connexion établie
Creation de la table FESTIVALES dans Snowflake
cur=conn.cursor()
query="""
CREATE OR REPLACE TABLE FESTIVALS (
NOM_MANIF varchar(250),
REGION varchar(250),
DOMAINE varchar(250),
COMPLEMENT_DOMAINE varchar(250),
DEPARTEMENT varchar(250),
PERIODICITE varchar(250),
SITE_WEB varchar(250),
NO_ID varchar(250),
COMMUNE varchar(250),
NO_EDITION float,
DATE_CREATION
varchar(50),
CODE_POSTAL float,
NOM_DEPARTEMENT varchar(250),
DATE_DEBUT varchar(50),
DATE_FIN varchar(50),
LATTITUDE varchar(50),
LONGITUDE varchar(50),
NUM_MOIS_HABITUEL int,
NOM_MOIS_HABITUEL varchar(50));
"""
cur.execute(query)
print('Table FESTIVALS créée ')
Table FESTIVALS créée
Chargement des données dans les tables FESTIVALS et PARTICIPANTS
Chargement des données de la table FESTIVAL
write_pandas(conn,df,table_name="FESTIVALS")
print('Table FESTIVALS chargée')
Table FESTIVALS chargée
Récupération des données depuis la plateforme Snowflake
query='select TOP 3 * from FESTIVALS'
cur=conn.cursor(DictCursor)
cur.execute(query)
data_fetch=cur.fetchall()
festival=pd.DataFrame(data_fetch)
festival
| NOM_MANIF | REGION | DOMAINE | COMPLEMENT_DOMAINE | DEPARTEMENT | PERIODICITE | SITE_WEB | NO_ID | COMMUNE | NO_EDITION | DATE_CREATION | CODE_POSTAL | NOM_DEPARTEMENT | DATE_DEBUT | DATE_FIN | LATTITUDE | LONGITUDE | NUM_MOIS_HABITUEL | NOM_MOIS_HABITUEL | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Festival Diverscenes | Pays De La Loire | Musiques Actuelles | Musiques Traditionnelles Et Du Monde | 53 | Biennale | Diverscene.Jimdo.Com | LD085 | Change | 0.0 | 2011-01-01 | 53810.0 | Mayenne | 2019-01-06 | 2019-02-02 | 48.1079801148 | -0.800104772023 | 1 | Janvier |
| 1 | Paris Des Femmes | Île-De-France | Transdisciplinaire | Non Renseigné | 75 | Annuelle | Parisdesfemmes.Com | HA026 | Paris | 7.0 | 2012-01-01 | 75001.0 | Paris | 2019-01-10 | 2019-01-12 | 48.8626304852 | 2.33629344655 | 1 | Janvier |
| 2 | Festival A Partir Du Reel | Normandie | Théâtre | Non Renseigné | 14 | Annuelle | Larenaissance-Mondeville.Fr | IG002 | Mondeville | 4.0 | 2005-01-01 | 14120.0 | Calvados | 2019-01-10 | 2019-02-07 | 49.1693649378 | -0.310691187417 | 1 | Janvier |
Chanrgement du fichier relatifs aux participants dans Snowflake
Créer la table PARTICIPANTS
cur=conn.cursor()
cur.execute('CREATE OR REPLACE TABLE "PARTICIPANTS" ("NO_ID" varchar(250), "NOMBRE2018" INT, "NOMBRE2017" INT , "PRIX" INT);')
print('Table PARTICIPANTS créée ')
Table PARTICIPANTS créée
Charger des données dans la table PARTICIPANTS
write_pandas(conn,participants,table_name="PARTICIPANTS")
print('Table PARTICIPANTS chargée')
Table PARTICIPANTS chargée
Récupérer les trois premières lignes de la table PARTICIPANTS
query='select TOP 3 * from PARTICIPANTS'
cur=conn.cursor(DictCursor)
cur.execute(query)
data_fetch=cur.fetchall()
participant=pd.DataFrame(data_fetch)
participant
| NO_ID | NOMBRE2018 | NOMBRE2017 | PRIX | |
|---|---|---|---|---|
| 0 | AJ030 | 250 | 269 | 54 |
| 1 | MD205 | 250 | 150 | 30 |
| 2 | KD098 | 250 | 499 | 100 |
Commandes de definitions de données
Ajouter de nouvelles colonnes de format date DATECREATION, DATEDEBUT et DATEFIN à la table FESTIVALS
cur.execute('ALTER TABLE FESTIVALS ADD COLUMN DATECREATION DATE')
cur.execute('ALTER TABLE FESTIVALS ADD COLUMN DATEDEBUT DATE')
cur.execute('ALTER TABLE FESTIVALS ADD COLUMN DATEFIN DATE')
cur.execute('UPDATE FESTIVALS SET DATEDEBUT = TO_DATE(DATE_DEBUT)')
cur.execute('UPDATE FESTIVALS SET DATEFIN = TO_DATE(DATE_FIN)')
cur.execute('UPDATE FESTIVALS SET DATECREATION = TO_DATE(DATE_CREATION)')
print('Colonnes ajoutées')
Colonnes ajoutées
Ajouter une colonne conditionnelle à la table PARTICIPANTS en fonction des valeurs des colonne 'NOMBRE2018' et 'NOMBRE2017'
cur.execute("ALTER TABLE PARTICIPANTS ADD COLUMN PARTICIPANT VARCHAR(20);")
cur.execute("UPDATE PARTICIPANTS SET PARTICIPANT=CASE WHEN NOMBRE2017>NOMBRE2018 THEN 'Décroissant' \r\n"
"WHEN NOMBRE2017<NOMBRE2018 THEN 'Croissant' ELSE 'Stable' END")
print('Colonne ajoutée et complétée')
Colonne ajoutée et complétée
Ajouter une colonne 'TOTAL_PARTICIPANT' à la table PARTICIPANTS
cur=conn.cursor()
cur.execute('ALTER TABLE PARTICIPANTS ADD COLUMN TOTAL_PARTICIPANT NUMERIC')
cur.execute('UPDATE PARTICIPANTS SET TOTAL_PARTICIPANT=NOMBRE2017 + NOMBRE2018')
print('Colonne ajoutée et mise à jour')
Colonne ajoutée et mise à jour
Ajouter une contrainte clé primare à la table FESTIVALS sur la colonne NO_ID
cur=conn.cursor()
cur.execute('ALTER TABLE FESTIVALS ADD CONSTRAINT PK_FESTIVALS PRIMARY KEY(NO_ID)')
print('Contrainte ajoutée')
Contrainte ajoutée
Ajouter une contrainte clé primare à la table PARTICIPANTS sur la colonne NO_ID
cur=conn.cursor()
cur.execute('ALTER TABLE PARTICIPANTS ADD CONSTRAINT PK_PARTICIPANTS PRIMARY KEY(NO_ID)')
print('Contrainte ajoutée')
Contrainte ajoutée
Supprimer les lignes de la table 'PARTICIPANTS' pour lesquelles les'NO_ID' n'ont pas de correspondance dans la table 'FESTIVALS'
cur=conn.cursor()
cur.execute('DELETE FROM PARTICIPANTS WHERE NO_ID NOT IN( SELECT NO_ID FROM FESTIVALS);')
print('Suppression effectuée')
Suppression effectuée
Ajouter une contrainte référentielle à la table PARTICIPANTS faisant référence à la table FESTIVALES
cur=conn.cursor()
cur.execute('ALTER TABLE PARTICIPANTS ADD CONSTRAINT FK_PARTI_FESTI FOREIGN KEY(NO_ID) REFERENCES FESTIVALS(NO_ID);')
print('Contrainte ajoutée')
Contrainte ajoutée
Créer une vue qui contient l'agrégation des participants aux festivals par REGION et par années
cur=conn.cursor()
query="""
CREATE OR REPLACE VIEW PARTICIPANT_REGION
AS SELECT REGION, SUM(NOMBRE2017) TOTAL2017,SUM(NOMBRE2018) TOTAL2018
FROM PARTICIPANTS,FESTIVALS
WHERE PARTICIPANTS.NO_ID=FESTIVALS.NO_ID
GROUP BY REGION;
"""
cur.execute(query)
print('vue créée')
vue créée
Récupérer des données à partir de la vue PARTICIPANT_REGION
query='select * from PARTICIPANT_REGION'
cur=conn.cursor(DictCursor)
cur.execute(query)
data_fetch=cur.fetchall()
participant_region=pd.DataFrame(data_fetch)
participant_region
| REGION | TOTAL2017 | TOTAL2018 | |
|---|---|---|---|
| 0 | Auvergne-Rhône-Alpes | 119391 | 163504 |
| 1 | Provence-Alpes-Côte D'Azur | 84147 | 127388 |
| 2 | Occitanie | 104909 | 156548 |
| 3 | Bourgogne-Franche-Comté | 37996 | 54025 |
| 4 | Hauts-De-France | 48712 | 61543 |
| 5 | Île-De-France | 112372 | 157651 |
| 6 | Pays De La Loire | 52602 | 81502 |
| 7 | Nouvelle-Aquitaine | 102645 | 155379 |
| 8 | Bretagne | 64551 | 90248 |
| 9 | Centre-Val De Loire | 32216 | 47996 |
| 10 | Corse | 6766 | 10360 |
| 11 | Guyane | 1305 | 800 |
| 12 | Mayotte | 1413 | 1661 |
| 13 | Nouvelle Calédonie | 674 | 1217 |
| 14 | La Réunion | 3160 | 4092 |
| 15 | Polynésie Française | 1004 | 1877 |
| 16 | Grand Est | 60646 | 90765 |
| 17 | Normandie | 37438 | 54800 |
| 18 | Guadeloupe | 1166 | 3313 |
| 19 | Martinique | 1330 | 2541 |
Créer une fonction qui retourne les noms des festivales en fonction de la l'année de création
cur=conn.cursor()
cur.execute("""
CREATE OR REPLACE FUNCTION GET_MANIF_YEAR(ANNEE INT)
RETURNS TABLE(MANIF STRING) AS
'SELECT NOM_MANIF FROM FESTIVALS WHERE YEAR(DATECREATION) =ANNEE'
""")
print('Fonction créee')
Fonction créee
Appeler la fonction stockée GET_MANIF_YEAR pour afficher 10 des festivals réalisés en 2017
query="SELECT TOP 10 * FROM TABLE(GET_MANIF_YEAR(2017));"
cur=conn.cursor(DictCursor)
cur.execute(query)
data_fetch=cur.fetchall()
NomFestivalParis=pd.DataFrame(data_fetch)
NomFestivalParis
| MANIF | |
|---|---|
| 0 | Electrochic |
| 1 | Festival L'Autre Cirque |
| 2 | Festival Variations |
| 3 | Festival Eldorado |
| 4 | La Tour Met Les Watts |
| 5 | La Magnifique Society |
| 6 | Festho'Rock |
| 7 | Festivalceou |
| 8 | Allotropiques |
| 9 | Les Singuliers |
Créer une fonction qui retourne les noms des festivales en fonction de la commune passée en argument
cur=conn.cursor()
cur.execute("""
CREATE OR REPLACE FUNCTION GET_MANIF(COMMUNE STRING)
RETURNS TABLE(MANIF STRING) AS
'SELECT NOM_MANIF FROM FESTIVALS WHERE COMMUNE=COMMUNE ORDER BY NOM_MANIF DESC' ;
""")
print('Fonction créee')
Fonction créee
Appeler la fonction stockée GET_MANIF pour afficher 10 des festivals réalisés à Paris
query="SELECT TOP 10 * FROM TABLE(GET_MANIF('Paris'));"
cur=conn.cursor(DictCursor)
cur.execute(query)
data_fetch=cur.fetchall()
NomFestivalParis=pd.DataFrame(data_fetch)
NomFestivalParis
| MANIF | |
|---|---|
| 0 | Ô Mauvais Buisson |
| 1 | Ô Les Choeurs |
| 2 | Évasion Festival |
| 3 | Été Musical En Bergerac |
| 4 | Été Frappé |
| 5 | Été Du Temps Du Tango |
| 6 | Émotions De Rue |
| 7 | Éclats De Voix (Preignan) |
| 8 | Éclats De Voix (Mauléon) |
| 9 | Éclats De Cirque |
Créer une procédure stockée qui retourne le nombre de lignes des tables de la Base de données FESTIVALS
cur=conn.cursor()
cur.execute("""
CREATE OR REPLACE PROCEDURE NombreLignes()
RETURNS VARCHAR
LANGUAGE SQL AS
DECLARE
fest INTEGER;
part INTEGER;
BEGIN
SELECT COUNT(*) into :fest FROM FESTIVALS;
SELECT COUNT(*) into :part FROM PARTICIPANTS;
RETURN 'Festivals: '||fest||' lignes'||',Participants:'||part ||' lignes';
END;
""")
print('Procédure créee')
Procédure créee
Appeler la procédure NombreLignes()
query="CALL NombreLignes();"
cur=conn.cursor(DictCursor)
cur.execute(query)
data_fetch=cur.fetchall()
NombreLignes=pd.DataFrame(data_fetch)
NombreLignes
| NOMBRELIGNES | |
|---|---|
| 0 | Festivals: 2991 lignes,Participants:2990 lignes |
Ecrire une procédure qui permet d'afficher les différentes tables de la Base de données FESTIVALS
cur.execute("""
CREATE OR REPLACE PROCEDURE info_base()
RETURNS VARCHAR
LANGUAGE SQL
AS
DECLARE
moncurseur CURSOR FOR
SELECT table_name FROM FESTIVALS.information_schema.tables
WHERE table_schema = 'FESTIVALS_SCHEMA' AND table_type= 'BASE TABLE' ORDER BY table_name;
reponse VARCHAR DEFAULT '';
BEGIN
FOR variable in moncurseur DO
reponse := variable.table_name||', '||reponse;
END FOR;
RETURN reponse;
END;
""")
print('Procédure créée')
Procédure créée
Appeler la procédure info_base() pour afficher les tables de la Base de Données
query="call info_base();"
cur=conn.cursor(DictCursor)
cur.execute(query)
data_fetch=cur.fetchall()
LesTables=pd.DataFrame(data_fetch)
print(f'Les differentes tables de la Base de Données:{LesTables}')
Les differentes tables de la Base de Données: INFO_BASE 0 PARTICIPANTS, FESTIVALS,
Commandes de manipulation de données
Afficher le nombre de communes par région
query=" SELECT REGION, COUNT(COMMUNE) NOMBRE_COMMUNE FROM FESTIVALS GROUP BY REGION ORDER BY REGION ;"
cur=conn.cursor(DictCursor)
cur.execute(query)
data_fetch=cur.fetchall()
reponse=pd.DataFrame(data_fetch)
reponse
| REGION | NOMBRE_COMMUNE | |
|---|---|---|
| 0 | Auvergne-Rhône-Alpes | 404 |
| 1 | Bourgogne-Franche-Comté | 138 |
| 2 | Bretagne | 216 |
| 3 | Centre-Val De Loire | 111 |
| 4 | Corse | 23 |
| 5 | Grand Est | 208 |
| 6 | Guadeloupe | 5 |
| 7 | Guyane | 3 |
| 8 | Hauts-De-France | 159 |
| 9 | La Réunion | 10 |
| 10 | Martinique | 5 |
| 11 | Mayotte | 4 |
| 12 | Normandie | 125 |
| 13 | Nouvelle Calédonie | 3 |
| 14 | Nouvelle-Aquitaine | 349 |
| 15 | Occitanie | 364 |
| 16 | Pays De La Loire | 183 |
| 17 | Polynésie Française | 3 |
| 18 | Provence-Alpes-Côte D'Azur | 298 |
| 19 | Île-De-France | 380 |
Afficher le nombre de festivals par région
query=" SELECT REGION, COUNT(NO_ID) NOMBRE_FESTIVAL FROM FESTIVALS GROUP BY REGION ORDER BY COUNT(NO_ID) DESC ;"
cur=conn.cursor(DictCursor)
cur.execute(query)
data=cur.fetchall()
reponse=pd.DataFrame(data)
reponse
| REGION | NOMBRE_FESTIVAL | |
|---|---|---|
| 0 | Auvergne-Rhône-Alpes | 404 |
| 1 | Île-De-France | 380 |
| 2 | Occitanie | 364 |
| 3 | Nouvelle-Aquitaine | 349 |
| 4 | Provence-Alpes-Côte D'Azur | 298 |
| 5 | Bretagne | 216 |
| 6 | Grand Est | 208 |
| 7 | Pays De La Loire | 183 |
| 8 | Hauts-De-France | 159 |
| 9 | Bourgogne-Franche-Comté | 138 |
| 10 | Normandie | 125 |
| 11 | Centre-Val De Loire | 111 |
| 12 | Corse | 23 |
| 13 | La Réunion | 10 |
| 14 | Martinique | 5 |
| 15 | Guadeloupe | 5 |
| 16 | Mayotte | 4 |
| 17 | Nouvelle Calédonie | 3 |
| 18 | Polynésie Française | 3 |
| 19 | Guyane | 3 |
sns.set_style("white")
sns.barplot(y="REGION",x="NOMBRE_FESTIVAL",data=reponse ,palette="seismic").set_title("Répartition des festivals par région ");
plt.show()

Afficher le chiffre d'affaire annuel par domaine et complément de domaine
query="""
SELECT
YEAR(DATEDEBUT) ANNEE,
DOMAINE,
COMPLEMENT_DOMAINE,
SUM(PRIX*TOTAL_PARTICIPANT) REVENU_ANNUEL
FROM FESTIVALS JOIN PARTICIPANTS
ON PARTICIPANTS.NO_ID=FESTIVALS.NO_ID
GROUP BY YEAR(DATEDEBUT),DOMAINE,COMPLEMENT_DOMAINE
ORDER BY YEAR(DATEDEBUT),DOMAINE;
"""
cur.execute(query)
data=cur.fetchall()
reponse=pd.DataFrame(data)
reponse
| ANNEE | DOMAINE | COMPLEMENT_DOMAINE | REVENU_ANNUEL | |
|---|---|---|---|---|
| 0 | 2017 | Arts Plastiques Et Visuels | Non Renseigné | 60413 |
| 1 | 2017 | Arts Plastiques Et Visuels | Photographie | 75000 |
| 2 | 2017 | Arts Plastiques Et Visuels | Design | 70629 |
| 3 | 2017 | Cinéma Et Audiovisuel | Non Renseigné | 221404 |
| 4 | 2017 | Cinéma Et Audiovisuel | Courts-Métrages | 76332 |
| ... | ... | ... | ... | ... |
| 226 | 2020 | Arts Plastiques Et Visuels | Non Renseigné | 22034 |
| 227 | 2020 | Cinéma Et Audiovisuel | Audiovisuel | 74796 |
| 228 | 2020 | Musiques Actuelles | Jazz, Blues Et Musiques Improvisées | 13050 |
| 229 | 2020 | Musiques Actuelles | Musiques Amplifiées Ou Électroniques | 72756 |
| 230 | 2020 | Pluridisciplinaire Spectacle Vivant | Non Renseigné | 29736 |
231 rows × 4 columns
sns.set_style("white")
palette = ["g", "b", "r", "y", "#4CC9F0"]
sns.barplot(y="DOMAINE", x="REVENU_ANNUEL", hue="ANNEE",data=reponse,palette=palette).set_title("Répartition des revenus par année et domaine ");
plt.show()

Afficher le nombre de festivals par mois ainsi que le nombre de participants et le revenu
query="""
SELECT
MONTH(DATEDEBUT) NUM_MOIS,
MONTHNAME(DATEDEBUT) NOM_MOIS,
COUNT(DATEDEBUT) NB_FESTIVAL,
SUM(TOTAL_PARTICIPANT) TOTAL_PARTICIPANT,
SUM(PRIX*TOTAL_PARTICIPANT) REVENU
FROM FESTIVALS JOIN PARTICIPANTS
ON PARTICIPANTS.NO_ID=FESTIVALS.NO_ID
GROUP BY MONTH(DATEDEBUT),MONTHNAME(DATEDEBUT)
ORDER BY MONTH(DATEDEBUT);
"""
cur=conn.cursor(DictCursor)
cur.execute(query)
data=cur.fetchall()
reponse=pd.DataFrame(data)
reponse
| NUM_MOIS | NOM_MOIS | NB_FESTIVAL | TOTAL_PARTICIPANT | REVENU | |
|---|---|---|---|---|---|
| 0 | 1 | Jan | 56 | 40877 | 2065372 |
| 1 | 2 | Feb | 65 | 45850 | 2700679 |
| 2 | 3 | Mar | 205 | 144384 | 8720062 |
| 3 | 4 | Apr | 171 | 117349 | 6787649 |
| 4 | 5 | May | 255 | 192338 | 11537937 |
| 5 | 6 | Jun | 329 | 236359 | 13965442 |
| 6 | 7 | Jul | 470 | 325803 | 18717790 |
| 7 | 8 | Aug | 313 | 223690 | 13169085 |
| 8 | 9 | Sep | 594 | 430668 | 25130479 |
| 9 | 10 | Oct | 281 | 202967 | 12035563 |
| 10 | 11 | Nov | 208 | 147751 | 8866698 |
| 11 | 12 | Dec | 43 | 33617 | 2078149 |
sns.set_style("white")
sns.barplot(x="NOM_MOIS",y="TOTAL_PARTICIPANT",data=reponse,palette="cubehelix").set_title("Répartition des participants par mois ");
plt.show()
plt.show()

sns.set_style("white")
sns.barplot(x="NOM_MOIS",y="REVENU",data=reponse,palette="pastel").set_title("Répartition des revenus par mois ");
plt.show()
plt.show()

Afficher les informations statistiques sur la répartition des festivals par région
query="""
SELECT
REGION,
SUM(TOTAL_PARTICIPANT) SUM_PARTICIPANT,
ROUND(AVG(TOTAL_PARTICIPANT),2) AVG_PARTICIPANT ,
MIN(TOTAL_PARTICIPANT) MIN_PARTICIPANT,
MAX(TOTAL_PARTICIPANT) MAX_PARTICIPANT
FROM FESTIVALS JOIN PARTICIPANTS
ON FESTIVALS.NO_ID=PARTICIPANTS.NO_ID
GROUP BY REGION
ORDER BY SUM(TOTAL_PARTICIPANT) DESC ;
"""
cur=conn.cursor(DictCursor)
cur.execute(query)
data_fetch=cur.fetchall()
reponse=pd.DataFrame(data_fetch)
reponse
| REGION | SUM_PARTICIPANT | AVG_PARTICIPANT | MIN_PARTICIPANT | MAX_PARTICIPANT | |
|---|---|---|---|---|---|
| 0 | Auvergne-Rhône-Alpes | 282895 | 701.97 | 345 | 1427 |
| 1 | Île-De-France | 270023 | 710.59 | 350 | 1476 |
| 2 | Occitanie | 261457 | 718.29 | 326 | 1453 |
| 3 | Nouvelle-Aquitaine | 258024 | 739.32 | 345 | 1457 |
| 4 | Provence-Alpes-Côte D'Azur | 211535 | 709.85 | 309 | 1409 |
| 5 | Bretagne | 154799 | 716.66 | 352 | 1415 |
| 6 | Grand Est | 151411 | 727.94 | 350 | 1402 |
| 7 | Pays De La Loire | 134104 | 732.81 | 334 | 1439 |
| 8 | Hauts-De-France | 110255 | 693.43 | 358 | 1420 |
| 9 | Normandie | 92238 | 737.90 | 355 | 1394 |
| 10 | Bourgogne-Franche-Comté | 92021 | 666.82 | 350 | 1340 |
| 11 | Centre-Val De Loire | 80212 | 722.63 | 344 | 1388 |
| 12 | Corse | 17126 | 744.61 | 380 | 1364 |
| 13 | La Réunion | 7252 | 725.20 | 420 | 1057 |
| 14 | Guadeloupe | 4479 | 895.80 | 485 | 1166 |
| 15 | Martinique | 3871 | 774.20 | 393 | 1278 |
| 16 | Mayotte | 3074 | 768.50 | 547 | 1175 |
| 17 | Polynésie Française | 2881 | 960.33 | 371 | 1382 |
| 18 | Guyane | 2105 | 701.67 | 605 | 750 |
| 19 | Nouvelle Calédonie | 1891 | 630.33 | 441 | 967 |
Afficher le nombre de participants par domaine dépassant 10000 participants
query="""
SELECT DOMAINE,SUM(TOTAL_PARTICIPANT) PARTICIPANT
FROM FESTIVALS JOIN PARTICIPANTS
ON FESTIVALS.NO_ID=PARTICIPANTS.NO_ID
GROUP BY DOMAINE
HAVING SUM(TOTAL_PARTICIPANT)>10000
ORDER BY SUM(TOTAL_PARTICIPANT) DESC ;
"""
cur=conn.cursor(DictCursor)
cur.execute(query)
data_fetch=cur.fetchall()
reponse=pd.DataFrame(data_fetch)
reponse
| DOMAINE | PARTICIPANT | |
|---|---|---|
| 0 | Musiques Actuelles | 1144691 |
| 1 | Cirque Et Arts De La Rue | 159647 |
| 2 | Cinéma Et Audiovisuel | 156463 |
| 3 | Musiques Classiques | 140565 |
| 4 | Pluridisciplinaire Spectacle Vivant | 138238 |
| 5 | Livre Et Littérature | 124737 |
| 6 | Transdisciplinaire | 86395 |
| 7 | Divers Spectacle Vivant | 64774 |
| 8 | Pluridisciplinaire Musique | 36304 |
| 9 | Arts Plastiques Et Visuels | 31984 |
| 10 | Danse | 30100 |
| 11 | Théâtre | 20231 |
sns.set_style("white")
sns.barplot(y="DOMAINE",x="PARTICIPANT",data=reponse ,palette="mako").set_title("Répartition des participants par domaines ");
plt.show()

Afficher les communes pour lesquelles un festival du méme domaine à été réalisé plus que trois fois en Janvier, Février ou, Mars
query="""
SELECT COMMUNE, DOMAINE ,COUNT(NO_ID) FREQUENCE
FROM FESTIVALS
WHERE NOM_MOIS_HABITUEL IN ('Janvier','Fevrier','Mars')
GROUP BY COMMUNE,DOMAINE
HAVING COUNT(NO_ID)>3
ORDER BY COMMUNE,DOMAINE DESC;
"""
cur=conn.cursor(DictCursor)
cur.execute(query)
data_fetch=cur.fetchall()
reponse=pd.DataFrame(data_fetch)
reponse
| COMMUNE | DOMAINE | FREQUENCE | |
|---|---|---|---|
| 0 | Lyon | Musiques Actuelles | 4 |
| 1 | Paris | Transdisciplinaire | 4 |
| 2 | Paris | Musiques Actuelles | 8 |
Classer les festivals en fonction du nombre de participants. Afficher le nom du festival, le domaine, la commune, le departement, le nombre de participant à ce festival, le nombre total de participants et le pourcentage du total
query="""
SELECT TOP 10
NOM_MANIF ,DOMAINE,COMMUNE,DEPARTEMENT
TOTAL_PARTICIPANT ,
SUM(TOTAL_PARTICIPANT) OVER() TOTAL,
ROUND((TOTAL_PARTICIPANT/SUM(TOTAL_PARTICIPANT) OVER())*100,3) POURCENTAGE
FROM FESTIVALS JOIN PARTICIPANTS
ON PARTICIPANTS.NO_ID=FESTIVALS.NO_ID
ORDER BY TOTAL_PARTICIPANT DESC;
"""
ur=conn.cursor(DictCursor)
cur.execute(query)
data_fetch=cur.fetchall()
reponse=pd.DataFrame(data_fetch)
reponse
| NOM_MANIF | DOMAINE | COMMUNE | TOTAL_PARTICIPANT | TOTAL | POURCENTAGE | |
|---|---|---|---|---|---|---|
| 0 | Blues Up Orchestra | Musiques Actuelles | Le Mont Dore | 988 | 2141653 | 0.023 |
| 1 | Festival Du Cinéma Des Peuples Anuu-Ru-Aboro | Cinéma Et Audiovisuel | Poindimie | 988 | 2141653 | 0.045 |
| 2 | Festival Du Cinéma De La Foa | Cinéma Et Audiovisuel | La Foa | 988 | 2141653 | 0.021 |
| 3 | Salon International Du Livre Océanien | Livre Et Littérature | Papeete | 987 | 2141653 | 0.053 |
| 4 | Lire En Polynésie | Livre Et Littérature | Papeete | 987 | 2141653 | 0.065 |
| 5 | Festival International Du Film Documentaire Oc... | Cinéma Et Audiovisuel | Papeete | 987 | 2141653 | 0.017 |
| 6 | Festival De L'Image Sous-Marine | Cinéma Et Audiovisuel | Mamoudzou | 976 | 2141653 | 0.028 |
| 7 | Festival Hip Hop Évolution | Danse | Bandraboua | 976 | 2141653 | 0.036 |
| 8 | Ciné Musafiri | Cinéma Et Audiovisuel | Mamoudzou | 976 | 2141653 | 0.026 |
| 9 | Festival Milatsika | Musiques Actuelles | Chiconi | 976 | 2141653 | 0.055 |
Afficher les festivals les plus rentables pour les communes du département 95. Afficher aussi le montant du festival ainsi que le revenu total de la commune et du département
query="""
SELECT TOP 15
NOM_MANIF ,COMMUNE,DEPARTEMENT,PRIX,TOTAL_PARTICIPANT PARTICIPANT,PRIX*TOTAL_PARTICIPANT MONTANT_MANIF,
SUM(TOTAL_PARTICIPANT*PRIX) OVER(PARTITION BY COMMUNE) REVENU_COMMUNE,
SUM(TOTAL_PARTICIPANT*PRIX) OVER(PARTITION BY DEPARTEMENT) REVENU_DEPARTEMENT,
FROM FESTIVALS JOIN PARTICIPANTS
ON PARTICIPANTS.NO_ID=FESTIVALS.NO_ID
WHERE DEPARTEMENT=95
ORDER BY PRIX*TOTAL_PARTICIPANT DESC,DEPARTEMENT ;
"""
cur=conn.cursor(DictCursor)
cur.execute(query)
data_fetch=cur.fetchall()
reponse=pd.DataFrame(data_fetch)
reponse
| NOM_MANIF | COMMUNE | DEPARTEMENT | PRIX | PARTICIPANT | MONTANT_MANIF | REVENU_COMMUNE | REVENU_DEPARTEMENT | |
|---|---|---|---|---|---|---|---|---|
| 0 | Charivari Au Village | Cergy Pontoise | 95 | 98 | 1350 | 132300 | 394252 | 1288999 |
| 1 | World Of Words | Cergy Pontoise | 95 | 95 | 1368 | 129960 | 394252 | 1288999 |
| 2 | Festival Theatral Du Val D'Oise | Eaubonne | 95 | 99 | 907 | 89793 | 168993 | 1288999 |
| 3 | Ecrans Vo Festival Image Par Image | Pontoise | 95 | 80 | 1111 | 88880 | 169956 | 1288999 |
| 4 | Rencontres D'Ici Et D'Ailleurs | Garges Les Gonesse | 95 | 94 | 918 | 86292 | 86292 | 1288999 |
| 5 | Salon Du Livre Jeunesse D'Eaubonne | Eaubonne | 95 | 96 | 825 | 79200 | 168993 | 1288999 |
| 6 | Royaumont | Asnieres Sur Oise | 95 | 91 | 864 | 78624 | 78624 | 1288999 |
| 7 | Barriere Enghien Jazz Festival | Enghien Les Bains | 95 | 96 | 782 | 75072 | 112604 | 1288999 |
| 8 | Un Air De Voyage | Cergy Pontoise | 95 | 98 | 740 | 72520 | 394252 | 1288999 |
| 9 | Festival Des Carrieres Saint Roch | Luzarches | 95 | 92 | 762 | 70104 | 70104 | 1288999 |
| 10 | Friendstival | Pontoise | 95 | 85 | 676 | 57460 | 169956 | 1288999 |
| 11 | Jazz Au Fil De L'Oise | Montmorency | 95 | 64 | 853 | 54592 | 92938 | 1288999 |
| 12 | Automne Musical De Taverny | Taverny | 95 | 55 | 921 | 50655 | 50655 | 1288999 |
| 13 | Festival Musical D'Automne Des Jeunes Interpre... | Montmorency | 95 | 66 | 581 | 38346 | 92938 | 1288999 |
| 14 | Bains Numériques | Enghien Les Bains | 95 | 44 | 853 | 37532 | 112604 | 1288999 |
Afficher les informations sur le festival le plus rentable pour chaque domaine
query="""
WITH CTE_DOMAINE
AS
(
SELECT
FESTIVALS.NO_ID,NOM_MANIF ,DOMAINE,PRIX,TOTAL_PARTICIPANT PARTICIPANT,PRIX*TOTAL_PARTICIPANT MONTANT_MANIF,
SUM(TOTAL_PARTICIPANT*PRIX) OVER(PARTITION BY DOMAINE) MONTANT_DOMAINE,
DENSE_RANK() OVER(PARTITION BY DOMAINE ORDER BY PRIX*TOTAL_PARTICIPANT DESC) RANG
FROM FESTIVALS JOIN PARTICIPANTS
ON PARTICIPANTS.NO_ID=FESTIVALS.NO_ID
ORDER BY PRIX*TOTAL_PARTICIPANT DESC
)
SELECT* FROM CTE_DOMAINE WHERE CTE_DOMAINE.RANG=1;
"""
cur=conn.cursor(DictCursor)
cur.execute(query)
data_fetch=cur.fetchall()
reponse=pd.DataFrame(data_fetch)
reponse
| NO_ID | NOM_MANIF | DOMAINE | PRIX | PARTICIPANT | MONTANT_MANIF | MONTANT_DOMAINE | RANG | |
|---|---|---|---|---|---|---|---|---|
| 0 | HJ055 | Festival Cinébanlieue - Paris/Saint-Denis | Cinéma Et Audiovisuel | 98 | 1476 | 144648 | 9107987 | 1 |
| 1 | AD298 | Morzine Harley Days | Musiques Actuelles | 98 | 1427 | 139846 | 68012449 | 1 |
| 2 | JM010 | Chapit'Otertre | Cirque Et Arts De La Rue | 94 | 1457 | 136958 | 9378260 | 1 |
| 3 | HK009 | Festival Vo/Vf, La Parole Aux Traducteurs | Livre Et Littérature | 98 | 1394 | 136612 | 7387950 | 1 |
| 4 | IG003 | Festival Ado | Théâtre | 97 | 1394 | 135218 | 1234475 | 1 |
| 5 | AB041 | Merci Bonsoir Festival | Pluridisciplinaire Spectacle Vivant | 94 | 1407 | 132258 | 7642052 | 1 |
| 6 | HA001 | Festival Des Cultures Juives | Transdisciplinaire | 91 | 1415 | 128765 | 5235734 | 1 |
| 7 | JE022 | Musical Ocean | Musiques Classiques | 93 | 1330 | 123690 | 8017750 | 1 |
| 8 | JH035 | Marais Vous Bien | Divers Spectacle Vivant | 91 | 1354 | 123214 | 3785822 | 1 |
| 9 | HL001 | Festival De L'Histoire De L'Art De Fontainebleau | Domaines Divers | 95 | 1231 | 116945 | 539649 | 1 |
| 10 | IF001 | Danse De Tous Les Sens | Danse | 86 | 1339 | 115154 | 1603647 | 1 |
| 11 | AC002 | Les Voix Du Prieure | Pluridisciplinaire Musique | 87 | 1322 | 115014 | 2055799 | 1 |
| 12 | HI001 | Festival Circulations | Arts Plastiques Et Visuels | 81 | 1347 | 109107 | 1773331 | 1 |
Afficher le premier festival organisé dans chaque région ansi que le nombre de participants, le coût, le revenue et date du début
query="""
WITH PREMIER_FESTIVAL AS
(
SELECT F.NO_ID,REGION,NOM_MANIF,PRIX,TOTAL_PARTICIPANT,PRIX*TOTAL_PARTICIPANT REVENUE, DATE_DEBUT,
ROW_NUMBER() OVER (PARTITION BY REGION ORDER BY DATE_DEBUT) NUMERO
FROM FESTIVALS F JOIN PARTICIPANTS P
ON F.NO_ID=P.NO_ID
)
SELECT REGION, NOM_MANIF ,PRIX,TOTAL_PARTICIPANT, REVENUE,DATE_DEBUT,NUMERO, FROM PREMIER_FESTIVAL
WHERE NUMERO=1 ORDER BY REGION;
"""
cur=conn.cursor(DictCursor)
cur.execute(query)
data_fetch=cur.fetchall()
reponse=pd.DataFrame(data_fetch)
reponse
| REGION | NOM_MANIF | PRIX | TOTAL_PARTICIPANT | REVENUE | DATE_DEBUT | NUMERO | |
|---|---|---|---|---|---|---|---|
| 0 | Auvergne-Rhône-Alpes | Festival De La Chabriole | 45 | 474 | 21330 | 2017-09-21 | 1 |
| 1 | Bourgogne-Franche-Comté | Keep The Faith Weekender | 35 | 639 | 22365 | 2017-09-21 | 1 |
| 2 | Bretagne | Sea Fest N Sound | 17 | 550 | 9350 | 2017-09-21 | 1 |
| 3 | Centre-Val De Loire | Allotropiques | 18 | 500 | 9000 | 2017-09-21 | 1 |
| 4 | Corse | Calvi Jazz | 53 | 891 | 47223 | 2017-09-21 | 1 |
| 5 | Grand Est | Biennale Selest'Art | 27 | 451 | 12177 | 2017-09-21 | 1 |
| 6 | Guadeloupe | Festival Prix De Court | 41 | 864 | 35424 | 2017-09-21 | 1 |
| 7 | Guyane | Les Rencontres Photographiques De Guyane | 100 | 750 | 75000 | 2017-09-21 | 1 |
| 8 | Hauts-De-France | Cassel Cornemuses | 61 | 555 | 33855 | 2017-09-21 | 1 |
| 9 | La Réunion | Festival Même Pas Peur | 100 | 1057 | 105700 | 2017-09-21 | 1 |
| 10 | Martinique | Fort-De-France | 72 | 893 | 64296 | 2018-07-01 | 1 |
| 11 | Mayotte | Festival Milatsika | 63 | 1175 | 74025 | 2018-10-12 | 1 |
| 12 | Normandie | Chants D’Elles | 67 | 636 | 42612 | 2017-09-21 | 1 |
| 13 | Nouvelle Calédonie | Blues Up Orchestra | 47 | 483 | 22701 | 2017-09-21 | 1 |
| 14 | Nouvelle-Aquitaine | Jazz Nuts Festival | 14 | 741 | 10374 | 2017-09-21 | 1 |
| 15 | Occitanie | Bob Marley One Love Celebration | 34 | 470 | 15980 | 2017-09-21 | 1 |
| 16 | Pays De La Loire | La Mer Est Loin | 100 | 1358 | 135800 | 2017-09-21 | 1 |
| 17 | Polynésie Française | Salon International Du Livre Océanien | 81 | 1128 | 91368 | 2018-09-07 | 1 |
| 18 | Provence-Alpes-Côte D'Azur | Fatche De - Festival Du Rire De Marseille | 33 | 415 | 13695 | 2017-09-21 | 1 |
| 19 | Île-De-France | Festiva'Son | 95 | 723 | 68685 | 2017-09-21 | 1 |
Afficher le chiffre d'affaire par mois , celui du mois précédent, la difference entre les deux et une colonne conditionnelle indiquant la croissance ou la décroissance
query="""
SELECT
MONTH(DATEDEBUT) NUM_MOIS,
MONTHNAME(DATEDEBUT) NOM_MOIS,
SUM(PRIX*TOTAL_PARTICIPANT) REVENU_MOIS,
LAG(SUM(PRIX*TOTAL_PARTICIPANT)) OVER (ORDER BY MONTH(DATEDEBUT)) AS REVENU_MOIS_AVANT,
SUM(PRIX*TOTAL_PARTICIPANT)-LAG(SUM(PRIX*TOTAL_PARTICIPANT)) OVER (ORDER BY MONTH(DATEDEBUT)) AS DIFFERENCE,
CASE
WHEN SUM(PRIX*TOTAL_PARTICIPANT)-LAG(SUM(PRIX*TOTAL_PARTICIPANT)) OVER (ORDER BY MONTH(DATEDEBUT))>0 THEN 'CROISSANCE'
WHEN SUM(PRIX*TOTAL_PARTICIPANT)-LAG(SUM(PRIX*TOTAL_PARTICIPANT)) OVER (ORDER BY MONTH(DATEDEBUT))<0 THEN 'DECROISSANCE'
ELSE 'INDETERMINE'
END REMARQUE
FROM FESTIVALS JOIN PARTICIPANTS
ON PARTICIPANTS.NO_ID=FESTIVALS.NO_ID
GROUP BY MONTH(DATEDEBUT),MONTHNAME(DATEDEBUT)
ORDER BY MONTH(DATEDEBUT);
"""
cur=conn.cursor(DictCursor)
cur.execute(query)
data=cur.fetchall()
reponse=pd.DataFrame(data)
reponse
| NUM_MOIS | NOM_MOIS | REVENU_MOIS | REVENU_MOIS_AVANT | DIFFERENCE | REMARQUE | |
|---|---|---|---|---|---|---|
| 0 | 1 | Jan | 2065372 | NaN | NaN | INDETERMINE |
| 1 | 2 | Feb | 2700679 | 2065372.0 | 635307.0 | CROISSANCE |
| 2 | 3 | Mar | 8720062 | 2700679.0 | 6019383.0 | CROISSANCE |
| 3 | 4 | Apr | 6787649 | 8720062.0 | -1932413.0 | DECROISSANCE |
| 4 | 5 | May | 11537937 | 6787649.0 | 4750288.0 | CROISSANCE |
| 5 | 6 | Jun | 13965442 | 11537937.0 | 2427505.0 | CROISSANCE |
| 6 | 7 | Jul | 18717790 | 13965442.0 | 4752348.0 | CROISSANCE |
| 7 | 8 | Aug | 13169085 | 18717790.0 | -5548705.0 | DECROISSANCE |
| 8 | 9 | Sep | 25130479 | 13169085.0 | 11961394.0 | CROISSANCE |
| 9 | 10 | Oct | 12035563 | 25130479.0 | -13094916.0 | DECROISSANCE |
| 10 | 11 | Nov | 8866698 | 12035563.0 | -3168865.0 | DECROISSANCE |
| 11 | 12 | Dec | 2078149 | 8866698.0 | -6788549.0 | DECROISSANCE |
Afficher le chiffre d'affaire par mois , celui du mois suivant, la difference entre les deux et une colonne conditionnelle indiquant la croissance ou la décroissance
query="""
SELECT
MONTH(DATEDEBUT) NUM_MOIS,
MONTHNAME(DATEDEBUT) NOM_MOIS,
SUM(PRIX*TOTAL_PARTICIPANT) REVENU_MOIS,
LEAD(SUM(PRIX*TOTAL_PARTICIPANT)) OVER (ORDER BY MONTH(DATEDEBUT)) AS REVENU_MOIS_APRES,
SUM(PRIX*TOTAL_PARTICIPANT)-LEAD(SUM(PRIX*TOTAL_PARTICIPANT)) OVER (ORDER BY MONTH(DATEDEBUT)) AS DIFFERENCE,
CASE
WHEN SUM(PRIX*TOTAL_PARTICIPANT)-LEAD(SUM(PRIX*TOTAL_PARTICIPANT)) OVER (ORDER BY MONTH(DATEDEBUT))>0 THEN 'DECROISSANCE'
WHEN SUM(PRIX*TOTAL_PARTICIPANT)-LEAD(SUM(PRIX*TOTAL_PARTICIPANT)) OVER (ORDER BY MONTH(DATEDEBUT))<0 THEN 'CROISSANCE'
ELSE 'INDETERMINE'
END REMARQUE
FROM FESTIVALS JOIN PARTICIPANTS
ON PARTICIPANTS.NO_ID=FESTIVALS.NO_ID
GROUP BY MONTH(DATEDEBUT),MONTHNAME(DATEDEBUT)
ORDER BY MONTH(DATEDEBUT);
"""
cur=conn.cursor(DictCursor)
cur.execute(query)
data=cur.fetchall()
reponse=pd.DataFrame(data)
reponse
| NUM_MOIS | NOM_MOIS | REVENU_MOIS | REVENU_MOIS_APRES | DIFFERENCE | REMARQUE | |
|---|---|---|---|---|---|---|
| 0 | 1 | Jan | 2065372 | 2700679.0 | -635307.0 | CROISSANCE |
| 1 | 2 | Feb | 2700679 | 8720062.0 | -6019383.0 | CROISSANCE |
| 2 | 3 | Mar | 8720062 | 6787649.0 | 1932413.0 | DECROISSANCE |
| 3 | 4 | Apr | 6787649 | 11537937.0 | -4750288.0 | CROISSANCE |
| 4 | 5 | May | 11537937 | 13965442.0 | -2427505.0 | CROISSANCE |
| 5 | 6 | Jun | 13965442 | 18717790.0 | -4752348.0 | CROISSANCE |
| 6 | 7 | Jul | 18717790 | 13169085.0 | 5548705.0 | DECROISSANCE |
| 7 | 8 | Aug | 13169085 | 25130479.0 | -11961394.0 | CROISSANCE |
| 8 | 9 | Sep | 25130479 | 12035563.0 | 13094916.0 | DECROISSANCE |
| 9 | 10 | Oct | 12035563 | 8866698.0 | 3168865.0 | DECROISSANCE |
| 10 | 11 | Nov | 8866698 | 2078149.0 | 6788549.0 | DECROISSANCE |
| 11 | 12 | Dec | 2078149 | NaN | NaN | INDETERMINE |
Commandes de contrôle de données
Créer un utilisateur pour la connexion Power BI à Snowflake
cur=conn.cursor()
query="""
CREATE OR REPLACE USER HV LOGIN_NAME='VALCOURTH' PASSWORD='HARALDVALCOURT'
DEFAULT_ROLE='ACCOUNTADMIN'
DEFAULT_WAREHOUSE='COMPUTE_WH'
MUST_CHANGE_PASSWORD=FALSE;
"""
cur.execute(query)
print('Utilisateur créer')
Utilisateur créer
Accorder le rôle "ACCOUNTADMIN" au nouvel utitlisateur
cur.execute('GRANT ROLE ACCOUNTADMIN TO USER HV;')
print('Rôle accordé')
Rôle accordé
Troisième partie : Le langage DAX avec Power BI¶
Le langage DAX nous permettra de:
- Créer des mesures
- Créer de nouvelles colonnes
- Effectuer certain calcul entre les tables
- Créer des fonctions personnalisées
Cette partie du projet comprend les étapes suivantes:
- La connexion de Power BI à Sowflake
- Le chargement des tables FESTIVALS et PARTICIPANTS dans Power BI
- La définition les indicateurs clés requis(KPI)
- La définition les rapports requis
- La création des nouvelles tables
- La création de nouvelles colonnes;
- La création de nouvelles mesures.
Connexion de Power BI à Snowflake

Récupération des tables FESTIVALS et PARTICIPANTS depuis la plateforme Snowflake

Définir les indicateurs clés requis
Les indicateurs clés sont les suivants:
- Le chiffre d'affaire de 2017
- le chiffre d'affaire de 2018
- Le chiffre d'affaire total
- Le nombre de participants total
- Le nombre de domaines
- Le nombre de festivals
- Le nombre de communes
Définir les rapports requis
Les rapports requis sont les suivants:
- La répartition des festivals par région
- La répartition des festivals par domaine
- La répartition de participants par domaine
- La répartition de participants par région
- La répartition du chiffre d'affaire par domaines
- La répartition du chiffre d'affaire par région
- La répartition du chiffre d'affaire par année
- L'évolution du chiffre d'affaire par région
- L'évolution du chiffre d'affaire par domaine
- L'évolution du chiffre d'affaire par année
- La géolocalisation des festivals
- Les participants par domaine,departement, région et commune
Ajouter une nouvelle table personnalisée 'DATE'

Ajouter de nouvelles colonnes

Ajouter de nouvelles mesures

Relation entre les tables

Quatrième partie : La visaulisation avec Power BI¶
Création des rapports










Publication des rapports sur Power BI Service
Création du tableau de bord avec Power BI Service

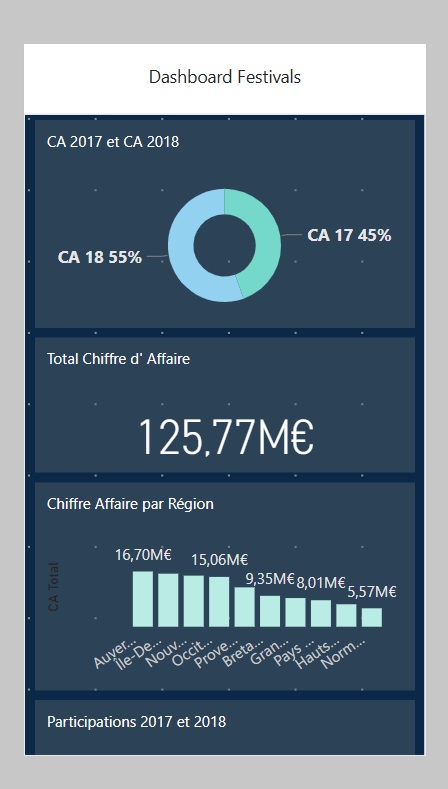
Création du tableau de bord pour appariels mobiles avec Power BI Service
Création de l'application avec Power BI Service
