Projet BI : Modélisation & Exploitation d’un Data WareHouse Bancaire
Réalisation:Haral Valcourt
Objectif
Ce projet a pour objectif la construction d’un Data Warehouse bancaire permettant une analyse structurée et efficace des comptes clients à des fins de reporting, visualisation et prise de décision. Il intègre l’automatisation des processus ETL, la génération de rapports dynamiques (Excel/PDF), ainsi qu’une analyse exploratoire des données.
Technologies utilisées

Étapes clés
- Présentation de la table source
- Modélisation du Data Warehouse
- Connexion à SQL Server et création du Data Warehouse
- Création des tables Fact et Dim
- Extraction des données depuis une base de données Oracle
- Préparation des données
- Implémentation de l’ETL (Python)
- Chargement des données via pandas
- Insertion des données dans les tables de dimension
- Vérification avant insertion dans FactCompte
- Insertion des données dans FactCompte
- Exploration SQL et Seaborn
- Création du tableau de bord (Tkinter + Seaborn)
- Interface utilisateur avec boutons d’action et filters
- Création de rapports automatisés de reporting (Tkinter + Excel + VBA + )
- Filtres dynamiques par succursale, type de compte, etc.
- Automatisation de l’export PDF depuis Excel
- Automatisation de l'envoi des rapports en pièce par email jointe via SMTP
Présentation de la table source

Modélisation du Data WareHouse
Dans le cadre de la mise en place de cet entrepôt de données analytique pour les comptes bancaires, nous avons adopté une modélisation en étoile , couramment utilisée dans les systèmes décisionnels pour sa simplicité, sa performance et sa lisibilité. Le modèle repose sur la table de faits centrale FactCompte, qui enregistre les mesures quantitatives (nombre de comptes, solde) associées à chaque compte, et sur plusieurs tables de dimensions qui décrivent les axes d’analyse permettant d’interpréter ces faits. Cette décomposition permet de :
- normaliser les données descriptives (types de comptes, statut, succursale),
- réduire la redondance des informations,
- optimiser les performances des requêtes analytiques,
- faciliter l’évolution du modèle en intégrant de nouveaux axes d’analyse sans impacter la structure des faits.
Les dimensions sont les suivantes :
- DimTypeCompte : typologie du compte (Épargne, Prêt, Courant,Dépôts à terme),
- DimStatutCompte : statut du compte (Ouvert, Fermé, etc.),
- DimSuccursale : Succursale du compte,
- DimZone : zone géographique d’appartenance,
- DimClient : profil du titulaire du compte (âge, sexe, nature),
- DimDate : date d’ouverture du compte, pour les analyses temporelles,
- DimCompte : Numéro du compte, sa date d'ouverture.
Chaque enregistrement de la table FactCompte fait référence à ces dimensions via des clés étrangères, formant ainsi une structure cohérente, performante et adaptée aux usages décisionnels dans Power BI ou tout autre outil de reporting.
Connexion à SQL Server et création du Data Warehouse
import pyodbc
import pandas as pd
import pandasql as ps
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import os
sns.set_context("paper", font_scale=0.9)
from warnings import filterwarnings
filterwarnings('ignore')
# Connexion initiale à master pour gérer les bases
conn_master= pyodbc.connect(
'DRIVER={SQL Server};SERVER=DESKTOP-RUJ1AK0;DATABASE=master',
autocommit=True
)
conn_master.autocommit = True
cur_master = conn_master.cursor()
# Suppression + création de la base BanqueDW
db_name = 'BanqueDW'
cur_master.execute(f"""
IF EXISTS (SELECT name FROM sys.databases WHERE name = '{db_name}')
BEGIN
ALTER DATABASE {db_name} SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE {db_name};
END;
CREATE DATABASE {db_name};
""")
print(f"Base de données '{db_name}' créée avec succès.")
cur_master.close()
conn_master.close()
# Connexion à la nouvelle base BanqueDW
conn= pyodbc.connect(
'DRIVER={SQL Server};SERVER=DESKTOP-RUJ1AK0;DATABASE=BanqueDW',
autocommit=True
)
cur = conn.cursor()
print(f"Connexion établie à la base '{db_name}'.")
Base de données 'BanqueDW' créée avec succès. Connexion établie à la base 'BanqueDW'.
cur.execute("SELECT name FROM sys.databases WHERE name = 'BanqueDW'")
row = cur.fetchone()
if row:
print(f"Base trouvée : {row.name}")
else:
print("La base BanqueDW n'existe pas.")
Base trouvée : BanqueDW
Création de la table de Faits et des Dimensions
Création de la table DimTypeCompte
cur.execute("""
CREATE TABLE DimTypeCompte (
ID_TypeCompte INT IDENTITY(1,1) PRIMARY KEY,
TypeCompte VARCHAR(50) NOT NULL UNIQUE
);
""")
print("DimTypeCompte créée.")
DimTypeCompte créée.
Création de la table DimStatutCompte
cur.execute("""
CREATE TABLE DimStatutCompte (
ID_Statut INT IDENTITY(1,1) PRIMARY KEY,
StatutCompte VARCHAR(50) NOT NULL UNIQUE
);
""")
print("DimStatutCompte créée.")
DimStatutCompte créée.
Création de la table DimSuccursale
cur.execute("""
CREATE TABLE DimSuccursale (
ID_Succ INT IDENTITY(1,1) PRIMARY KEY,
CodeSucc VARCHAR(10) NOT NULL UNIQUE,
NomSuccursale VARCHAR(100)
);
""")
print("DimSuccursale créée.")
DimSuccursale créée.
Création de la table DimZone
cur.execute("""
CREATE TABLE DimZone (
ID_Zone INT IDENTITY(1,1) PRIMARY KEY,
CodeZone VARCHAR(10) NOT NULL UNIQUE,
NomZone VARCHAR(100)
);
""")
print("DimZone créée.")
DimZone créée.
Création de la table DimClient
cur.execute("""
CREATE TABLE DimClient (
ID_Client INT IDENTITY(1,1) PRIMARY KEY,
Numero VARCHAR(26) UNIQUE, -- identifiant métier
Sexe VARCHAR(10),
DateNaissance DATE,
Nature VARCHAR(20)
);
""")
print("DimClient créée.")
DimClient créée.
Création de la table DimDate
cur.execute("""
CREATE TABLE DimDate (
ID_Date INT IDENTITY(1,1) PRIMARY KEY,
DateComplete DATE NOT NULL UNIQUE,
Annee INT,
Mois INT,
Jour INT,
Trimestre INT,
MoisNom VARCHAR(20)
);
""")
print("DimDate créée.")
DimDate créée.
Création de la table DimCompte
cur.execute("""
IF OBJECT_ID('DimCompte', 'U') IS NOT NULL
DROP TABLE DimCompte;
CREATE TABLE DimCompte (
ID_Compte INT IDENTITY(1,1) PRIMARY KEY,
NumeroCompte VARCHAR(26) UNIQUE NOT NULL,
DateOpen DATE NOT NULL,
AncienneteJours INT NOT NULL
);
""")
conn.commit()
print("DimCompte créée.")
DimCompte créée.
Création de la table FactCompte
cur.execute("""
IF OBJECT_ID('FactCompte', 'U') IS NOT NULL
DROP TABLE FactCompte;
CREATE TABLE FactCompte (
ID_CompteFact INT IDENTITY(1,1) PRIMARY KEY,
ID_Compte INT NOT NULL, -- FK vers DimCompte
ID_TypeCompte INT NOT NULL, -- FK vers DimTypeCompte
ID_Statut INT NOT NULL, -- FK vers DimStatutCompte
ID_Succ INT NOT NULL, -- FK vers DimSuccursale
ID_Zone INT NOT NULL, -- FK vers DimZone
ID_Client INT NOT NULL, -- FK vers DimClient
ID_DateOpen INT NOT NULL, -- FK vers DimDate
NombreComptes INT NOT NULL DEFAULT 1,
Balance DECIMAL(18,2) NOT NULL,
FOREIGN KEY (ID_Compte) REFERENCES DimCompte(ID_Compte),
FOREIGN KEY (ID_TypeCompte) REFERENCES DimTypeCompte(ID_TypeCompte),
FOREIGN KEY (ID_Statut) REFERENCES DimStatutCompte(ID_Statut),
FOREIGN KEY (ID_Succ) REFERENCES DimSuccursale(ID_Succ),
FOREIGN KEY (ID_Zone) REFERENCES DimZone(ID_Zone),
FOREIGN KEY (ID_Client) REFERENCES DimClient(ID_Client),
FOREIGN KEY (ID_DateOpen) REFERENCES DimDate(ID_Date)
);
""")
conn.commit()
print("Table FactCompte créée avec succès")
Table FactCompte créée avec succès
Affichage des differentes tables
import pyodbc
# --- Liste des tables ---
tables = [
"DimTypeCompte",
"DimStatutCompte",
"DimSuccursale",
"DimZone",
"DimClient",
"DimDate",
"FactCompte",
"DimCompte"
]
# --- Affichage des colonnes ---
for table in tables:
print(f"\n Colonnes de la table {table} :")
query = f"""
SELECT COLUMN_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME = '{table}'
ORDER BY ORDINAL_POSITION
"""
cur.execute(query)
columns = [row[0] for row in cur.fetchall()]
for col in columns:
print(f" - {col}")
Colonnes de la table DimTypeCompte : - ID_TypeCompte - TypeCompte Colonnes de la table DimStatutCompte : - ID_Statut - StatutCompte Colonnes de la table DimSuccursale : - ID_Succ - CodeSucc - NomSuccursale Colonnes de la table DimZone : - ID_Zone - CodeZone - NomZone Colonnes de la table DimClient : - ID_Client - Numero - Sexe - DateNaissance - Nature Colonnes de la table DimDate : - ID_Date - DateComplete - Annee - Mois - Jour - Trimestre - MoisNom Colonnes de la table FactCompte : - ID_CompteFact - ID_Compte - ID_TypeCompte - ID_Statut - ID_Succ - ID_Zone - ID_Client - ID_DateOpen - NombreComptes - Balance Colonnes de la table DimCompte : - ID_Compte - NumeroCompte - DateOpen - AncienneteJours
Représentation du modèle en étoile

Extraction des données depuis une base de données Oracle et stockage dans un fichier CSV
import oracledb
import pandas as pd
# 1. Connexion Oracle
connection = oracledb.connect(
user="system",
password="halrald",
dsn="localhost:1521/orcl"
)
# 2. Requête SQL pour extraire les données
query = """
SELECT
NOCOMPTE,
TYPE,
BRANCH,
SUCC,
ZONE,
SEXE,
DATENAIS,
BALANCE,
STATUT,
NUMERO,
TYPE_COMPTE,
STATUT_COMPTE,
SEXE_CLIENT,
DATEOPEN,
NATURE
FROM compte
"""
# 3. Charger les données dans un DataFrame pandas
df = pd.read_sql(query, connection)
# 4. Forcer les colonnes texte en string
cols_str = ['NOCOMPTE', 'SUCC', 'ZONE', 'SEXE', 'TYPE_COMPTE', 'STATUT_COMPTE', 'SEXE_CLIENT', 'NATURE']
df[cols_str] = df[cols_str].astype(str)
# 5. Nettoyer les apostrophes réelles si elles existent dans NOCOMPTE (pour éviter doublons)
df['NOCOMPTE'] = df['NOCOMPTE'].str.replace("'", "", regex=False).str.strip()
# 6. Conversion des colonnes dates au format datetime
df['DATENAIS'] = pd.to_datetime(df['DATENAIS'], errors='coerce')
df['DATEOPEN'] = pd.to_datetime(df['DATEOPEN'], errors='coerce')
# 7. Export du DataFrame dans un CSV UTF-8 sans BOM (compatible Excel via import)
df.to_csv("Banque_clean.csv", index=False, encoding='utf-8')
# 8. Fermer la connexion Oracle
connection.close()
print("Extraction et export en CSV ")
Extraction et export en CSV
Chargement et affichage du fichier CSV
# 1. Charger le CSV
df = pd.read_csv("Banque_clean.csv", dtype={"NOCOMPTE": str})
# 2. Affichage sans format scientifique
pd.set_option('display.float_format', '{:.2f}'.format)
pd.set_option('display.max_columns', None)
# 3. Vérifier un aperçu
df.head()
| NOCOMPTE | TYPE | BRANCH | SUCC | ZONE | SEXE | DATENAIS | BALANCE | STATUT | NUMERO | TYPE_COMPTE | STATUT_COMPTE | SEXE_CLIENT | DATEOPEN | NATURE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4141000226 | 6 | 1 | LGN | OUEST | M | 1954-01-03 | 0.02 | 1 | 1028649 | Compte Courant | Ouvert | Homme | 2025-05-13 | Entreprise |
| 1 | 410044628 | 3 | 4 | CAY | SUD | M | 1954-01-03 | 0.13 | 5 | 42087 | Dépôt à terme | Dormant | Homme | 2022-07-11 | Particulier |
| 2 | 2410015269 | 1 | 1 | LGN | OUEST | F | 1954-01-03 | 0.16 | 5 | 344174 | Compte Epargne | Dormant | Femme | 2024-08-16 | Entreprise |
| 3 | 1641000545 | 6 | 5 | FDN | EST | M | 1954-01-03 | 0.20 | 1 | 582026 | Compte Courant | Ouvert | Homme | 2025-07-07 | Entreprise |
| 4 | 4440000343 | 6 | 1 | LGN | OUEST | M | 1954-01-03 | 0.25 | 1 | 282682 | Compte Courant | Ouvert | Homme | 2024-07-23 | Entreprise |
Insertion des données dans les dimensions
Insertion dans DimTypeCompte
type_comptes = df['TYPE_COMPTE'].dropna().unique()
for val in type_comptes:
cur.execute("""
IF NOT EXISTS (SELECT 1 FROM DimTypeCompte WHERE TypeCompte = ?)
INSERT INTO DimTypeCompte (TypeCompte) VALUES (?)
""", (val, val))
conn.commit()
print("DimTypeCompte : insertion effectuée")
DimTypeCompte : insertion effectuée
Insertion dans DimStatutCompte
statut_comptes = df['STATUT_COMPTE'].dropna().unique()
for val in statut_comptes:
cur.execute("""
IF NOT EXISTS (SELECT 1 FROM DimStatutCompte WHERE StatutCompte = ?)
INSERT INTO DimStatutCompte (StatutCompte) VALUES (?)
""", (val, val))
conn.commit()
print("DimStatutCompte : insertion effectuée")
DimStatutCompte : insertion effectuée
Insertion dans DimSuccursale
# Extraire les paires uniques CodeSucc - NomSuccursale
succ_df = df[['BRANCH', 'SUCC']].dropna().drop_duplicates()
for _, row in succ_df.iterrows():
code = str(row['BRANCH']).strip()
nom = str(row['SUCC']).strip()
cur.execute("""
IF NOT EXISTS (
SELECT 1 FROM DimSuccursale WHERE CodeSucc = ?
)
INSERT INTO DimSuccursale (CodeSucc, NomSuccursale)
VALUES (?, ?)
""", (code, code, nom))
conn.commit()
print("DimSuccursale : insertion terminée à partir des colonnes BRANCH + SUCC")
DimSuccursale : insertion terminée à partir des colonnes BRANCH + SUCC
Insertion dans DimZone
zones = df['ZONE'].dropna().unique()
for val in zones:
cur.execute("""
IF NOT EXISTS (SELECT 1 FROM DimZone WHERE CodeZone = ?)
INSERT INTO DimZone (CodeZone, NomZone) VALUES (?, ?)
""", (val, val, val))
conn.commit()
print("DimZone : insertion effectuée")
DimZone : insertion effectuée
Insertion dans DimClient
# Étape 1 : extraire les colonnes nécessaires sans doublon sur Numero
df_clients = df[['NUMERO', 'SEXE_CLIENT', 'DATENAIS', 'NATURE']].drop_duplicates(subset='NUMERO')
# Étape 2 : requête SQL d'insertion
insert_query = """
INSERT INTO DimClient (Numero, Sexe, DateNaissance, Nature)
VALUES (?, ?, ?, ?)
"""
# Étape 3 : insertion ligne par ligne
for _, row in df_clients.iterrows():
try:
cur.execute(insert_query, (
row['NUMERO'],
row['SEXE_CLIENT'],
row['DATENAIS'],
row['NATURE']
))
except Exception as e:
print(f" Erreur insertion client NUMERO={row['NUMERO']}: {e}")
# Étape 4 : commit
conn.commit()
print("Insertion terminée dans DimClient")
Insertion terminée dans DimClient
Insertion dans DimCompte
def nettoyer_numero_brut(numero):
if pd.isna(numero):
return None
s = str(numero)
# Suppression suffixe '.0' fréquent sur les floats importés
if s.endswith('.0'):
s = s[:-2]
# Supprimer espaces, tabulations, tirets
s = s.strip().replace(' ', '').replace('\t', '').replace('-', '')
return s
# Nettoyer la colonne NOCOMPTE en gardant format original (pas de zfill)
df['NOCOMPTE_brut'] = df['NOCOMPTE'].apply(nettoyer_numero_brut)
# Supprimer doublons et valeurs manquantes
comptes = df[['NOCOMPTE_brut', 'DATEOPEN']].dropna(subset=['NOCOMPTE_brut', 'DATEOPEN']).drop_duplicates(subset=['NOCOMPTE_brut'])
# Vider DimCompte avant insertion
cur.execute("DELETE FROM DimCompte")
conn.commit()
# Insertion dans DimCompte
today = pd.Timestamp.today()
inserts_deja_faits = set()
for _, row in comptes.iterrows():
numero = row['NOCOMPTE_brut']
if numero in inserts_deja_faits:
continue
date_open = pd.to_datetime(row['DATEOPEN'])
anciennete = (today - date_open).days
date_str = date_open.strftime('%Y-%m-%d')
cur.execute("""
INSERT INTO DimCompte (NumeroCompte, DateOpen, AncienneteJours)
VALUES (?, ?, ?)
""", (numero, date_str, anciennete))
inserts_deja_faits.add(numero)
print(f"Insertion DimCompte terminée. {len(inserts_deja_faits)} lignes insérées.")
Insertion DimCompte terminée. 36059 lignes insérées.
Insertion dans DimDate (à partir de DATEOPEN)
import pandas as pd
import pyodbc
from datetime import datetime, date
df = pd.read_csv('Banque_clean.csv')
# Connexion à la nouvelle base BanqueDW
conn= pyodbc.connect(
'DRIVER={SQL Server};SERVER=DESKTOP-RUJ1AK0;DATABASE=BanqueDW',
autocommit=True
)
cur = conn.cursor()
# 1. S'assurer que la colonne DATEOPEN est au bon format
df['DATEOPEN'] = pd.to_datetime(df['DATEOPEN'], errors='coerce')
# 2. Extraire les dates uniques
unique_dates = df['DATEOPEN'].dropna().dt.date.unique()
unique_dates = sorted(unique_dates)
# 3. Lire les dates déjà présentes dans DimDate
cur.execute("SELECT DateComplete FROM DimDate")
existing_dates = set(row[0] for row in cur.fetchall())
# 4. Identifier les nouvelles dates à insérer
new_dates = [d for d in unique_dates if d not in existing_dates]
# 5. Préparer les lignes à insérer
inserts = []
for d in new_dates:
annee = d.year
mois = d.month
jour = d.day
trimestre = (mois - 1) // 3 + 1
mois_nom = d.strftime("%B")
inserts.append((d, annee, mois, jour, trimestre, mois_nom))
# 6. Insertion en base
if inserts:
insert_query = '''
INSERT INTO DimDate (DateComplete, Annee, Mois, Jour, Trimestre, MoisNom)
VALUES (?, ?, ?, ?, ?, ?)
'''
from datetime import date
for row in inserts:
row = list(row)
if isinstance(row[0], (date, datetime)):
row[0] = row[0].strftime("%Y-%m-%d")
cur.execute(insert_query, row)
conn.commit()
else:
print("Aucune nouvelle date à insérer.")
print(f"Insertion terminée")
Aucune nouvelle date à insérer. Insertion terminée
Affichage du nombre de lignes inserées dans chaque table
tables = [
"dimtypecompte",
"dimstatutcompte",
"dimsuccursale",
"dimzone",
"dimclient",
"dimdate",
"dimCompte",
"factcompte"
]
for table in tables:
cur.execute(f"SELECT COUNT(*) FROM {table}")
count = cur.fetchone()[0]
print(f"Nombre de lignes dans {table}: {count}")
Nombre de lignes dans dimtypecompte: 4 Nombre de lignes dans dimstatutcompte: 4 Nombre de lignes dans dimsuccursale: 5 Nombre de lignes dans dimzone: 4 Nombre de lignes dans dimclient: 34003 Nombre de lignes dans dimdate: 420 Nombre de lignes dans dimCompte: 36059 Nombre de lignes dans factcompte: 0
Affichage des 5 premieres lignes de chaque table
tables = [
"dimtypecompte",
"dimstatutcompte",
"dimsuccursale",
"dimzone",
"dimclient",
"dimdate",
"dimCompte",
"factcompte"
]
for table in tables:
print(f"\nContenu de {table}:")
cur.execute(f"SELECT TOP 5 * FROM {table}")
rows = cur.fetchall()
for row in rows:
print(row)
Contenu de dimtypecompte: (1, 'Compte Courant') (4, 'Compte de Prêt') (3, 'Compte Epargne') (2, 'Dépôt à terme') Contenu de dimstatutcompte: (2, 'Dormant') (3, 'Fermé') (4, 'No Débit') (1, 'Ouvert') Contenu de dimsuccursale: (1, '1', 'LGN') (2, '4', 'CAY') (3, '5', 'FDN') (4, '2', 'GNV') (5, '3', 'FTL') Contenu de dimzone: (1, 'OUEST', 'OUEST') (2, 'SUD', 'SUD') (3, 'EST', 'EST') (4, 'NORD', 'NORD') Contenu de dimclient: (1, '1028649', 'Homme', '1954-01-03', 'Entreprise') (2, '42087', 'Homme', '1954-01-03', 'Particulier') (3, '344174', 'Femme', '1954-01-03', 'Entreprise') (4, '582026', 'Homme', '1954-01-03', 'Entreprise') (5, '282682', 'Homme', '1954-01-03', 'Entreprise') Contenu de dimdate: (1, '2021-01-01', 2021, 1, 1, 1, 'January') (2, '2021-01-05', 2021, 1, 5, 1, 'January') (3, '2021-01-09', 2021, 1, 9, 1, 'January') (4, '2021-01-13', 2021, 1, 13, 1, 'January') (5, '2021-01-17', 2021, 1, 17, 1, 'January') Contenu de dimCompte: (1, '4141000226', '2025-05-13', 92) (2, '410044628', '2022-07-11', 1129) (3, '2410015269', '2024-08-16', 362) (4, '1641000545', '2025-07-07', 37) (5, '4440000343', '2024-07-23', 386) Contenu de factcompte:
Vérification avant insertion dans FactCompte
- Vérifier la présence de toutes les colonnes nécessaires dans le DataFrame source
- Vérifier la correspondance avec les dimensions (mapping complet)
- Vérifier les formats et la cohérence des types de données
- Vérifier que les dates sont bien mappées dans DimDate
Vérifiecation de la présence de toutes les colonnes nécessaires dans le DataFrame source
# Chargement du fichier source
df = pd.read_csv('Banque_clean.csv')
df.columns = df.columns.str.strip().str.upper()
# Dictionnaire des correspondances
dimensions = {
'TYPE_COMPTE': ('DimTypeCompte', 'TypeCompte'),
'STATUT_COMPTE': ('DimStatutCompte', 'StatutCompte'),
'SUCC': ('DimSuccursale', 'NomSuccursale'),
'ZONE': ('DimZone', 'NomZone'),
'SEXE_CLIENT': ('DimClient', 'Sexe'),
'NATURE': ('DimClient', 'Nature')
}
print("Vérification de la correspondance avec les dimensions SQL Server\n")
for col_source, (table_dim, col_dim) in dimensions.items():
print(f"Vérification de la dimension `{table_dim}` (colonne `{col_dim}`)")
# Valeurs distinctes du fichier source
valeurs_source = set(df[col_source].dropna().astype(str).str.strip().str.upper().unique())
# Valeurs dans la dimension SQL
query = f"SELECT DISTINCT {col_dim} FROM {table_dim}"
try:
df_dim = pd.read_sql(query, conn)
except Exception as e:
print(f"Erreur lors de la requête SQL : {e}")
continue
valeurs_dim = set(df_dim[col_dim].dropna().astype(str).str.strip().str.upper().unique())
# Écart
valeurs_non_trouvees = valeurs_source - valeurs_dim
if valeurs_non_trouvees:
print(f"{len(valeurs_non_trouvees)} valeur(s) non trouvée(s) dans `{table_dim}` :")
for val in sorted(valeurs_non_trouvees):
print(f" - {val}")
else:
print("Toutes les valeurs sont présentes dans la dimension.\n")
Vérification de la correspondance avec les dimensions SQL Server Vérification de la dimension `DimTypeCompte` (colonne `TypeCompte`) Toutes les valeurs sont présentes dans la dimension. Vérification de la dimension `DimStatutCompte` (colonne `StatutCompte`) Toutes les valeurs sont présentes dans la dimension. Vérification de la dimension `DimSuccursale` (colonne `NomSuccursale`) Toutes les valeurs sont présentes dans la dimension. Vérification de la dimension `DimZone` (colonne `NomZone`) Toutes les valeurs sont présentes dans la dimension. Vérification de la dimension `DimClient` (colonne `Sexe`) Toutes les valeurs sont présentes dans la dimension. Vérification de la dimension `DimClient` (colonne `Nature`) Toutes les valeurs sont présentes dans la dimension.
Vérification de l’intégrité référentielle (ou de la correspondance avec les dimensions)
def nettoyer_numero_compte(numero):
if pd.isna(numero):
return None
s = str(numero)
if s.endswith('.0'):
s = s[:-2]
s = s.strip().replace(' ', '').replace('\t', '').replace('-', '')
s = s.zfill(10)
return s
def verifier_correspondance(df_colonne, table, colonne_dim, libelle_dim):
# Extraire valeurs uniques du CSV
if libelle_dim == 'Numéro de compte':
# Nettoyage + formatage des numéros avant comparaison
valeurs_csv = set(
df[df_colonne]
.dropna()
.apply(nettoyer_numero_compte)
.dropna()
.unique()
)
else:
valeurs_csv = set(df[df_colonne].dropna().unique())
# Charger les valeurs de la dimension depuis la base
cur.execute(f"SELECT DISTINCT {colonne_dim} FROM {table}")
valeurs_dim = set(row[0] for row in cur.fetchall())
# Identifier les non-mappés
non_trouves = valeurs_csv - valeurs_dim
# Résumé
print(f"\n Vérification pour {libelle_dim}")
print(f" - Valeurs uniques dans CSV : {len(valeurs_csv)}")
print(f" - Valeurs trouvées dans {table} : {len(valeurs_csv & valeurs_dim)}")
print(f" - Valeurs non trouvées : {len(non_trouves)}")
if non_trouves:
print(" - Exemples de valeurs non trouvées :")
for val in list(non_trouves)[:5]:
print(f" {val}")
else:
print("Toutes les valeurs sont présentes.")
# Lancer les vérifications, avec libellé exact pour activer le nettoyage des comptes
verifier_correspondance('TYPE_COMPTE', 'DimTypeCompte', 'TypeCompte', 'Type de Compte')
verifier_correspondance('STATUT_COMPTE', 'DimStatutCompte', 'StatutCompte', 'Statut de Compte')
verifier_correspondance('SUCC', 'DimSuccursale', 'NomSuccursale', 'Succursale')
verifier_correspondance('ZONE', 'DimZone', 'CodeZone', 'Zone géographique')
verifier_correspondance('SEXE_CLIENT', 'DimClient', 'Sexe', 'Sexe du client')
verifier_correspondance('NATURE', 'DimClient', 'Nature', 'Nature du client')
verifier_correspondance('DATENAIS', 'DimClient', 'DateNaissance', 'Date de naissance')
verifier_correspondance('DATEOPEN', 'DimDate', 'DateComplete', 'Date d’ouverture')
verifier_correspondance('NUMERO', 'DimCompte', 'NumeroCompte', 'Numéro de compte')
Vérification pour Type de Compte - Valeurs uniques dans CSV : 4 - Valeurs trouvées dans DimTypeCompte : 4 - Valeurs non trouvées : 0 Toutes les valeurs sont présentes. Vérification pour Statut de Compte - Valeurs uniques dans CSV : 4 - Valeurs trouvées dans DimStatutCompte : 4 - Valeurs non trouvées : 0 Toutes les valeurs sont présentes. Vérification pour Succursale - Valeurs uniques dans CSV : 5 - Valeurs trouvées dans DimSuccursale : 5 - Valeurs non trouvées : 0 Toutes les valeurs sont présentes. Vérification pour Zone géographique - Valeurs uniques dans CSV : 4 - Valeurs trouvées dans DimZone : 4 - Valeurs non trouvées : 0 Toutes les valeurs sont présentes. Vérification pour Sexe du client - Valeurs uniques dans CSV : 2 - Valeurs trouvées dans DimClient : 2 - Valeurs non trouvées : 0 Toutes les valeurs sont présentes. Vérification pour Nature du client - Valeurs uniques dans CSV : 2 - Valeurs trouvées dans DimClient : 2 - Valeurs non trouvées : 0 Toutes les valeurs sont présentes. Vérification pour Date de naissance - Valeurs uniques dans CSV : 4116 - Valeurs trouvées dans DimClient : 4101 - Valeurs non trouvées : 15 - Exemples de valeurs non trouvées : 1947-06-13 1942-02-23 1946-02-12 1942-08-12 1947-03-10 Vérification pour Date d’ouverture - Valeurs uniques dans CSV : 420 - Valeurs trouvées dans DimDate : 420 - Valeurs non trouvées : 0 Toutes les valeurs sont présentes. Vérification pour Numéro de compte - Valeurs uniques dans CSV : 34003 - Valeurs trouvées dans DimCompte : 0 - Valeurs non trouvées : 34003 - Exemples de valeurs non trouvées : 0000510361 0000078901 0000720944 0000079003 0000045984
Vérification des formats et la cohérence des types de données
import pandas as pd
import numpy as np
def verifier_formats(df):
erreurs = []
# 1. Dates valides et cohérentes
for col in ['DATENAIS', 'DATEOPEN']:
# Convertir en datetime, coerce les erreurs en NaT
df[col + '_parsed'] = pd.to_datetime(df[col], errors='coerce')
nuls = df[col + '_parsed'].isna().sum()
if nuls > 0:
erreurs.append(f"{col} : {nuls} valeurs invalides ou manquantes")
# Par exemple on peut vérifier pas de dates futures
futur = (df[col + '_parsed'] > pd.Timestamp.today()).sum()
if futur > 0:
erreurs.append(f"{col} : {futur} dates dans le futur détectées")
# 2. Numériques
if not pd.api.types.is_numeric_dtype(df['BALANCE']):
erreurs.append("BALANCE n'est pas numérique")
# 3. Valeurs non nulles
for col in ['NOCOMPTE', 'TYPE_COMPTE', 'STATUT_COMPTE']:
nuls = df[col].isna().sum()
if nuls > 0:
erreurs.append(f"{col} : {nuls} valeurs manquantes")
# 4. Valeurs dans un set autorisé
sexe_autorise = {'HOMME', 'FEMME'}
invalides = df.loc[~df['SEXE_CLIENT'].str.upper().isin(sexe_autorise), 'SEXE_CLIENT']
if not invalides.empty:
erreurs.append(f"SEXE_CLIENT : valeurs non autorisées détectées : {invalides.unique()}")
# 5. Exemple de nettoyage du numéro de compte
def nettoyer_numero_compte(n):
if pd.isna(n): return np.nan
s = str(n).strip().replace(' ', '').replace('-', '')
return s.zfill(10)
df['NOCOMPTE_clean'] = df['NOCOMPTE'].apply(nettoyer_numero_compte)
if df['NOCOMPTE_clean'].isna().sum() > 0:
erreurs.append("NOCOMPTE : valeurs invalides après nettoyage")
return erreurs, df
# Utilisation :
erreurs, df_verifie = verifier_formats(df)
if erreurs:
print("Erreurs détectées dans les formats et types :")
for e in erreurs:
print(" -", e)
else:
print("Tous les formats et types semblent corrects.")
Erreurs détectées dans les formats et types : - DATEOPEN : 2923 dates dans le futur détectées
Détection des anomalies
def detecter_anomalies_etendues(df):
anomalies = []
# 1. Validation des dates
for col in ['DATENAIS', 'DATEOPEN']:
df[col + '_parsed'] = pd.to_datetime(df[col], errors='coerce')
nb_invalides = df[col + '_parsed'].isna().sum()
if nb_invalides > 0:
anomalies.append(f"{col} : {nb_invalides} valeurs invalides ou manquantes")
nb_futures = (df[col + '_parsed'] > pd.Timestamp.today()).sum()
if nb_futures > 0:
anomalies.append(f"{col} : {nb_futures} dates dans le futur détectées")
# 2. Vérification des colonnes numériques
for col in ['BALANCE', 'TYPE', 'STATUT', 'NUMERO', 'BRANCH']:
if not pd.api.types.is_numeric_dtype(df[col]):
anomalies.append(f"{col} : colonne non numérique")
else:
nb_nulls = df[col].isna().sum()
if nb_nulls > 0:
anomalies.append(f"{col} : {nb_nulls} valeurs manquantes")
# 3. Vérification valeurs obligatoires non nulles (str)
for col in ['NOCOMPTE', 'TYPE_COMPTE', 'STATUT_COMPTE', 'SUCC', 'ZONE', 'SEXE_CLIENT', 'NATURE']:
nb_nuls = df[col].isna().sum()
if nb_nuls > 0:
anomalies.append(f"{col} : {nb_nuls} valeurs manquantes")
# 4. Valeurs dans ensemble autorisé pour SEXE_CLIENT
sexe_autorise = {'HOMME', 'FEMME'}
invalid_sexe = df.loc[~df['SEXE_CLIENT'].str.upper().isin(sexe_autorise), 'SEXE_CLIENT']
if not invalid_sexe.empty:
anomalies.append(f"SEXE_CLIENT : valeurs non autorisées détectées : {invalid_sexe.unique()}")
# 5. Contrôle du format NOCOMPTE : longueur 10 chiffres (après nettoyage)
def nettoyer_numero_compte(n):
if pd.isna(n): return None
s = str(n).strip().replace(' ', '').replace('-', '')
return s.zfill(10)
df['NOCOMPTE_clean'] = df['NOCOMPTE'].apply(nettoyer_numero_compte)
invalid_nocompte = df.loc[df['NOCOMPTE_clean'].str.len() != 10, 'NOCOMPTE_clean']
if not invalid_nocompte.empty:
anomalies.append(f"NOCOMPTE : {len(invalid_nocompte)} numéros invalides (longueur != 10)")
# 6. Contrôle des codes SUCC et ZONE : chaînes non vides, alphanumériques
for col in ['SUCC', 'ZONE']:
invalid_codes = df.loc[~df[col].astype(str).str.match(r'^[A-Za-z0-9]+$'), col]
if not invalid_codes.empty:
anomalies.append(f"{col} : {len(invalid_codes)} valeurs avec caractères invalides")
return anomalies
# Chargement des données (ajuste le chemin si nécessaire)
df = pd.read_csv('Banque_clean.csv')
df.columns = df.columns.str.strip().str.upper()
# Détection des anomalies étendues
rapport_anomalies = detecter_anomalies_etendues(df)
# Affichage du rapport
if rapport_anomalies:
print("Anomalies détectées :")
for item in rapport_anomalies:
print(" -", item)
else:
print("Pas d’anomalies détectées.")
Anomalies détectées : - DATEOPEN : 2923 dates dans le futur détectées - NOCOMPTE : 36923 numéros invalides (longueur != 10)
Analyser des dates futures
import pandas as pd
# Relecture des données
df = pd.read_csv("Banque_clean.csv", dtype={'NOCOMPTE': str})
df.columns = df.columns.str.strip().str.upper()
# Conversion DATEOPEN
df['DATEOPEN_parsed'] = pd.to_datetime(df['DATEOPEN'], errors='coerce')
# Filtrer les lignes avec dates dans le futur
futur_df = df[df['DATEOPEN_parsed'] > pd.Timestamp.today()]
print(f"Il y a {len(futur_df)} dates dans le futur dans DATEOPEN")
print("\n Aperçu de 10 lignes concernées :")
print(futur_df[['NOCOMPTE', 'DATEOPEN', 'DATEOPEN_parsed']].head(10))
Il y a 2923 dates dans le futur dans DATEOPEN
Aperçu de 10 lignes concernées :
NOCOMPTE DATEOPEN DATEOPEN_parsed
6 1641000581 2025-12-12 2025-12-12
13 4441000191 2025-12-12 2025-12-12
15 110019040 2025-10-06 2025-10-06
19 4441000149 2025-08-16 2025-08-16
25 410035205 2025-12-08 2025-12-08
29 2741000675 2025-10-06 2025-10-06
35 2741000435 2025-12-24 2025-12-24
39 1141000140 2025-09-09 2025-09-09
42 2641000281 2025-10-06 2025-10-06
51 2741000230 2025-10-18 2025-10-18
Correction des dates futures et de AnciennetéJour
import pandas as pd
# Chargement du fichier
df = pd.read_csv('Banque_clean.csv')
df.columns = df.columns.str.strip().str.upper()
# Conversion de la colonne DATEOPEN en datetime
df['DATEOPEN_parsed'] = pd.to_datetime(df['DATEOPEN'], errors='coerce')
# Récupérer la date du jour normalisée
today = pd.Timestamp.today().normalize()
# Correction : remplacer les dates futures par aujourd’hui
nb_futures = (df['DATEOPEN_parsed'] > today).sum()
df.loc[df['DATEOPEN_parsed'] > today, 'DATEOPEN_parsed'] = today
print(f"{nb_futures} dates dans le futur ont été remplacées par la date du jour ({today.date()})")
# Calcul de l'ancienneté en jours
df['ANCIENNETEJOURS'] = (today - df['DATEOPEN_parsed']).dt.days
# Remise à 0 des anciennetés négatives
nb_neg_anciennete = (df['ANCIENNETEJOURS'] < 0).sum()
df.loc[df['ANCIENNETEJOURS'] < 0, 'ANCIENNETEJOURS'] = 0
print(f"{nb_neg_anciennete} anciennetés négatives ont été corrigées à 0")
# Réécrire la date corrigée au format YYYY-MM-DD dans la colonne d'origine
df['DATEOPEN'] = df['DATEOPEN_parsed'].dt.strftime('%Y-%m-%d')
# Suppression de la colonne temporaire
df.drop(columns=['DATEOPEN_parsed'], inplace=True)
2923 dates dans le futur ont été remplacées par la date du jour (2025-08-13) 0 anciennetés négatives ont été corrigées à 0
Correction des dates dans le futur au niveau du Data Warehouse
from datetime import datetime
# Connexion à la nouvelle base BanqueDW
conn= pyodbc.connect(
'DRIVER={SQL Server};SERVER=DESKTOP-RUJ1AK0;DATABASE=BanqueDW',
autocommit=True
)
cursor = conn.cursor()
# Date du jour au format string
today = datetime.today().strftime('%Y-%m-%d')
# 1. Mettre à jour les dates futures
cursor.execute("""
UPDATE DimCompte
SET DateOpen = ?
WHERE DateOpen > ?
""", (today, today))
# 2. Mettre à zéro les anciennetés négatives ou incohérentes
cursor.execute("""
UPDATE DimCompte
SET AncienneteJours = 0
WHERE AncienneteJours < 0 OR DateOpen > ?
""", (today,))
conn.commit()
print("Mises à jour effectuées.")
# Enregistrer les modifications
conn.commit()
print("Mise à jour terminée dans DimCompte.")
Mises à jour effectuées. Mise à jour terminée dans DimCompte.
Analyse des numéros de compte
- Identification des comptes vides ou null
- Identification des comptes trop courts (ex. < 3 caractères)
- Identification des comptes très longs (> 26)
- Identification des comptes avec caractères non alphanumériques
- Idebtification de doublons
- Identification des compte avec signe -
- Affichage des 5 premières lignes de chaque cas anormal
import pandas as pd
import os
# Création du dossier de sortie
output_dir = "anomalies_nocompte"
os.makedirs(output_dir, exist_ok=True)
anomalies = {}
# 1. NOCOMPTE manquants
mask_missing = df['NOCOMPTE'].isna()
df_missing = df[mask_missing]
if not df_missing.empty:
anomalies['NOCOMPTE manquants'] = df_missing
df_missing.to_csv(f"{output_dir}/nocompte_manquants.csv", index=False)
print("NOCOMPTE manquants (5 premiers) :")
display(df_missing.head())
# 2. NOCOMPTE trop courts (<3 caractères)
mask_short = df['NOCOMPTE'].astype(str).str.len() < 3
df_short = df[mask_short]
if not df_short.empty:
anomalies['NOCOMPTE trop courts (<3 caractères)'] = df_short
df_short.to_csv(f"{output_dir}/nocompte_trop_courts.csv", index=False)
print("\n NOCOMPTE trop courts (5 premiers) :")
display(df_short.head())
# 3. NOCOMPTE trop longs (>26 caractères)
mask_long = df['NOCOMPTE'].astype(str).str.len() > 26
df_long = df[mask_long]
if not df_long.empty:
anomalies['NOCOMPTE trop longs (>26 caractères)'] = df_long
df_long.to_csv(f"{output_dir}/nocompte_trop_longs.csv", index=False)
print("\n NOCOMPTE trop longs (5 premiers) :")
display(df_long.head())
# 4. NOCOMPTE avec caractères non alphanumériques
mask_invalid = ~df['NOCOMPTE'].astype(str).str.match(r'^[A-Za-z0-9]+$', na=False)
df_invalid = df[mask_invalid]
if not df_invalid.empty:
anomalies['NOCOMPTE avec caractères non alphanumériques'] = df_invalid
df_invalid.to_csv(f"{output_dir}/nocompte_caracteres_invalides.csv", index=False)
print("\n NOCOMPTE avec caractères non alphanumériques (5 premiers) :")
display(df_invalid.head())
# 5. NOCOMPTE dupliqués
cols_to_sort = ['NOCOMPTE']
if 'DATEOPEN' in df.columns:
cols_to_sort.append('DATEOPEN')
mask_dups = df.duplicated('NOCOMPTE', keep=False)
df_dups = df[mask_dups].sort_values(by=cols_to_sort)
if not df_dups.empty:
anomalies['NOCOMPTE dupliqués'] = df_dups
df_dups.to_csv(f"{output_dir}/nocompte_dupliques.csv", index=False)
print("\n NOCOMPTE dupliqués (5 premiers) :")
display(df_dups.head())
# 6. NOCOMPTE avec un signe -
mask_negative = df['NOCOMPTE'].astype(str).str.contains(r'^-')
df_negative = df[mask_negative]
if not df_negative.empty:
anomalies['NOCOMPTE négatifs (avec -)'] = df_negative
df_negative.to_csv(f"{output_dir}/nocompte_negatifs.csv", index=False)
print("\n NOCOMPTE avec signe '-' (5 premiers) :")
display(df_negative.head())
# 🧾 Résumé final
if anomalies:
print("\n Résumé des anomalies de NOCOMPTE :")
for k, v in anomalies.items():
print(f" - {k} : {len(v)} lignes (exporté dans {output_dir})")
else:
print(" Aucun problème détecté dans la colonne NOCOMPTE.")
NOCOMPTE avec caractères non alphanumériques (5 premiers) :
| NOCOMPTE | TYPE | BRANCH | SUCC | ZONE | SEXE | DATENAIS | BALANCE | STATUT | NUMERO | TYPE_COMPTE | STATUT_COMPTE | SEXE_CLIENT | DATEOPEN | NATURE | ANCIENNETEJOURS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4141000226.00 | 6 | 1 | LGN | OUEST | M | 1954-01-03 | 0.02 | 1 | 1028649 | Compte Courant | Ouvert | Homme | 2025-05-13 | Entreprise | 92 |
| 1 | 410044628.00 | 3 | 4 | CAY | SUD | M | 1954-01-03 | 0.13 | 5 | 42087 | Dépôt à terme | Dormant | Homme | 2022-07-11 | Particulier | 1129 |
| 2 | 2410015269.00 | 1 | 1 | LGN | OUEST | F | 1954-01-03 | 0.16 | 5 | 344174 | Compte Epargne | Dormant | Femme | 2024-08-16 | Entreprise | 362 |
| 3 | 1641000545.00 | 6 | 5 | FDN | EST | M | 1954-01-03 | 0.20 | 1 | 582026 | Compte Courant | Ouvert | Homme | 2025-07-07 | Entreprise | 37 |
| 4 | 4440000343.00 | 6 | 1 | LGN | OUEST | M | 1954-01-03 | 0.25 | 1 | 282682 | Compte Courant | Ouvert | Homme | 2024-07-23 | Entreprise | 386 |
NOCOMPTE dupliqués (5 premiers) :
| NOCOMPTE | TYPE | BRANCH | SUCC | ZONE | SEXE | DATENAIS | BALANCE | STATUT | NUMERO | TYPE_COMPTE | STATUT_COMPTE | SEXE_CLIENT | DATEOPEN | NATURE | ANCIENNETEJOURS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 26252 | 103000000000.00 | 3 | 3 | FTL | NORD | M | 1982-02-15 | 549093.63 | 1 | 91658 | Dépôt à terme | Ouvert | Homme | 2023-01-01 | Particulier | 955 |
| 30705 | 103000000000.00 | 3 | 1 | LGN | OUEST | M | 1970-10-19 | 83371.89 | 1 | 89675 | Dépôt à terme | Ouvert | Homme | 2023-01-05 | Particulier | 951 |
| 984 | 103000000000.00 | 3 | 1 | LGN | OUEST | M | 1973-10-22 | 125256.28 | 1 | 92985 | Dépôt à terme | Ouvert | Homme | 2023-01-13 | Particulier | 943 |
| 11024 | 103000000000.00 | 3 | 1 | LGN | OUEST | M | 1962-06-30 | 12291.32 | 1 | 92105 | Dépôt à terme | Ouvert | Homme | 2023-01-13 | Particulier | 943 |
| 13601 | 103000000000.00 | 3 | 1 | LGN | OUEST | M | 1979-08-16 | 261000.00 | 1 | 92982 | Dépôt à terme | Ouvert | Homme | 2023-01-13 | Particulier | 943 |
Résumé des anomalies de NOCOMPTE : - NOCOMPTE avec caractères non alphanumériques : 36927 lignes (exporté dans anomalies_nocompte) - NOCOMPTE dupliqués : 901 lignes (exporté dans anomalies_nocompte)
Fusion des numéros de comptes dupliqués
On va appliquer les règles suivantes pour fusionner les doublons de comptes :
- STATUT_COMPTE = "Ouvert"
- SUCC = la plus fréquente
- ZONE = la plus fréquente
- NATURE = "Particulier"
- ID_CLIENT = le plus grand
- BALANCE = la plus élevée
- TYPE_COMPTE = le plus fréquent
- DATEOPEN = la plus ancienne
- DATENAIS = la plus ancienne
- NUMERO = le plus élevé
# 1. Chargement du fichier en forçant NOCOMPTE en texte
df = pd.read_csv('Banque_clean.csv', dtype={'NOCOMPTE': str})
df.columns = df.columns.str.upper()
# 2. Nettoyage des NOCOMPTE : suppression éventuelle des décimaux ".00"
def clean_nocompte(x):
if pd.isna(x):
return None
try:
s = str(x).strip()
if 'e+' in s.lower():
s = f"{int(float(s))}"
elif '.' in s:
s = s.split('.')[0] # on enlève la partie décimale
return s
except:
return str(x)
df['NOCOMPTE'] = df['NOCOMPTE'].apply(clean_nocompte)
# 3. Fusion intelligente pour éliminer les doublons sur NOCOMPTE
def fusion_intelligente(g):
return pd.Series({
'NOCOMPTE': g['NOCOMPTE'].iloc[0],
'SUCC': g['SUCC'].mode(dropna=True)[0] if not g['SUCC'].mode().empty else g['SUCC'].iloc[0],
'ZONE': g['ZONE'].mode(dropna=True)[0] if not g['ZONE'].mode().empty else g['ZONE'].iloc[0],
'DATENAIS': g['DATENAIS'].min(),
'DATEOPEN': g['DATEOPEN'].min(),
'BALANCE': g['BALANCE'].max(),
'NUMERO': g['NUMERO'].min(),
'TYPE_COMPTE': g['TYPE_COMPTE'].mode(dropna=True)[0] if not g['TYPE_COMPTE'].mode().empty else g['TYPE_COMPTE'].iloc[0],
'STATUT_COMPTE': g['STATUT_COMPTE'].mode(dropna=True)[0] if not g['STATUT_COMPTE'].mode().empty else g['STATUT_COMPTE'].iloc[0],
'SEXE_CLIENT': g['SEXE_CLIENT'].mode(dropna=True)[0] if not g['SEXE_CLIENT'].mode().empty else g['SEXE_CLIENT'].iloc[0],
'NATURE': g['NATURE'].mode(dropna=True)[0] if not g['NATURE'].mode().empty else g['NATURE'].iloc[0],
})
df_corrige = df.groupby('NOCOMPTE', group_keys=False).apply(fusion_intelligente).reset_index(drop=True)
print(f" Nombre de comptes après fusion : {len(df_corrige):,}")
# 4. Vérification des doublons restants
doublons_restants = df_corrige[df_corrige.duplicated(subset='NOCOMPTE', keep=False)]
if doublons_restants.empty:
print(" Aucun doublon restant sur NOCOMPTE après fusion.")
else:
print(f" Doublons restants sur NOCOMPTE : {len(doublons_restants)} lignes")
display(doublons_restants.head())
Nombre de comptes après fusion : 36,059 Aucun doublon restant sur NOCOMPTE après fusion.
Analyse des numéros de client
Chaque client (NUMERO) doit avoir :
- un seul sexe (SEXE_CLIENT)
- une seule date de naissance (DATENAIS)
- une seule nature (NATURE)
colonnes_a_afficher = [
'NOCOMPTE', 'SUCC', 'ZONE', 'DATENAIS', 'DATEOPEN', 'BALANCE', 'NUMERO',
'TYPE_COMPTE', 'STATUT_COMPTE', 'SEXE_CLIENT', 'NATURE'
]
# 1. Clients avec plusieurs SEXE_CLIENT
sexe_client_check = df_corrige.groupby('NUMERO')['SEXE_CLIENT'].nunique()
multi_sexe = sexe_client_check[sexe_client_check > 1]
if not multi_sexe.empty:
print("Clients avec plusieurs SEXE_CLIENT :")
display(
df_corrige[df_corrige['NUMERO'].isin(multi_sexe.index)]
.sort_values(['NUMERO', 'SEXE_CLIENT'])[colonnes_a_afficher]
.groupby('NUMERO')
.apply(lambda x: x.drop_duplicates())
.reset_index(drop=True)
)
else:
print("Chaque client a un sexe unique.")
# 2. Clients avec plusieurs DATENAIS
date_naiss_check = df_corrige.groupby('NUMERO')['DATENAIS'].nunique()
multi_date = date_naiss_check[date_naiss_check > 1]
if not multi_date.empty:
print(" Clients avec plusieurs dates de naissance :")
display(
df_corrige[df_corrige['NUMERO'].isin(multi_date.index)]
.sort_values(['NUMERO', 'DATENAIS'])[colonnes_a_afficher]
.groupby('NUMERO')
.apply(lambda x: x.drop_duplicates())
.reset_index(drop=True)
)
else:
print(" Chaque client a une date de naissance unique.")
# 3. Clients avec plusieurs NATURE
nature_check = df_corrige.groupby('NUMERO')['NATURE'].nunique()
multi_nature = nature_check[nature_check > 1]
if not multi_nature.empty:
print(" Clients avec plusieurs NATURE :")
display(
df_corrige[df_corrige['NUMERO'].isin(multi_nature.index)]
.sort_values(['NUMERO', 'NATURE'])[colonnes_a_afficher]
.groupby('NUMERO')
.apply(lambda x: x.drop_duplicates())
.reset_index(drop=True)
)
else:
print(" Chaque client a une nature unique.")
Clients avec plusieurs SEXE_CLIENT :
| NOCOMPTE | SUCC | ZONE | DATENAIS | DATEOPEN | BALANCE | NUMERO | TYPE_COMPTE | STATUT_COMPTE | SEXE_CLIENT | NATURE | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1341000194 | LGN | OUEST | 1958-08-16 | 2021-12-28 | 3453.87 | 882 | Compte Courant | Ouvert | Femme | Particulier |
| 1 | 2741000833 | LGN | OUEST | 1949-07-20 | 2021-01-21 | 92.48 | 882 | Compte Courant | Ouvert | Homme | Particulier |
| 2 | 1610094564 | FDN | EST | 1980-03-25 | 2021-08-16 | 299601.34 | 1488 | Dépôt à terme | Ouvert | Femme | Particulier |
| 3 | 1610122547 | FDN | EST | 1979-05-04 | 2021-01-25 | 247386.25 | 1488 | Dépôt à terme | Ouvert | Femme | Particulier |
| 4 | 1660016502 | FDN | EST | 1982-01-13 | 2021-07-27 | 519396.74 | 1488 | Compte Courant | Ouvert | Homme | Particulier |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1559 | 1640001869 | FDN | EST | 1982-05-20 | 2025-03-19 | 587348.39 | 863304 | Compte Courant | No Débit | Homme | Entreprise |
| 1560 | 2940001120 | LGN | OUEST | 1950-08-29 | 2025-02-06 | 350.00 | 929240 | Compte Courant | Ouvert | Femme | Entreprise |
| 1561 | 2941000544 | LGN | OUEST | 1949-03-17 | 2025-10-06 | 37.50 | 929240 | Compte Courant | Ouvert | Homme | Entreprise |
| 1562 | 3341001071 | LGN | OUEST | 1949-08-29 | 2025-05-25 | 106.50 | 1073113 | Compte Courant | Dormant | Femme | Entreprise |
| 1563 | 3340001758 | LGN | OUEST | 1957-11-03 | 2025-12-28 | 2525.00 | 1073113 | Compte Courant | Dormant | Homme | Entreprise |
1564 rows × 11 columns
Clients avec plusieurs dates de naissance :
| NOCOMPTE | SUCC | ZONE | DATENAIS | DATEOPEN | BALANCE | NUMERO | TYPE_COMPTE | STATUT_COMPTE | SEXE_CLIENT | NATURE | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1360000513 | LGN | OUEST | 1950-08-10 | 2021-03-23 | 334.92 | 425 | Compte Courant | Ouvert | Homme | Particulier |
| 1 | 1341000221 | LGN | OUEST | 1957-01-19 | 2021-04-24 | 2009.66 | 425 | Compte Courant | Ouvert | Homme | Particulier |
| 2 | 2741000833 | LGN | OUEST | 1949-07-20 | 2021-01-21 | 92.48 | 882 | Compte Courant | Ouvert | Homme | Particulier |
| 3 | 1341000194 | LGN | OUEST | 1958-08-16 | 2021-12-28 | 3453.87 | 882 | Compte Courant | Ouvert | Femme | Particulier |
| 4 | 1610122547 | FDN | EST | 1979-05-04 | 2021-01-25 | 247386.25 | 1488 | Dépôt à terme | Ouvert | Femme | Particulier |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 5580 | 3340001758 | LGN | OUEST | 1957-11-03 | 2025-12-28 | 2525.00 | 1073113 | Compte Courant | Dormant | Homme | Entreprise |
| 5581 | 141000031 | LGN | OUEST | 1956-01-22 | 2025-04-16 | 1490.50 | 1084747 | Compte Courant | Ouvert | Femme | Entreprise |
| 5582 | 140000186 | LGN | OUEST | 1972-05-06 | 2025-07-23 | 103003.48 | 1084747 | Compte Courant | Ouvert | Femme | Entreprise |
| 5583 | 3341001086 | LGN | OUEST | 1950-03-08 | 2025-07-15 | 233.50 | 1088277 | Compte Courant | Ouvert | Homme | Entreprise |
| 5584 | 3340001786 | LGN | OUEST | 1958-11-16 | 2025-03-19 | 3900.00 | 1088277 | Compte Courant | Ouvert | Homme | Entreprise |
5585 rows × 11 columns
Chaque client a une nature unique.
Traitement des numéros de client
def choisir_sexe(series):
if "Homme" in series.values:
return "Homme"
else:
return series.iloc[0]
def fusion_clients(df):
def fusion_client(g):
return pd.Series({
'NUMERO': g['NUMERO'].iloc[0],
'SEXE_CLIENT': choisir_sexe(g['SEXE_CLIENT']),
'DATENAIS': g['DATENAIS'].min(),
'NOCOMPTE': g['NOCOMPTE'].iloc[0],
'SUCC': g['SUCC'].iloc[0],
'ZONE': g['ZONE'].iloc[0],
'DATEOPEN': g['DATEOPEN'].iloc[0],
'BALANCE': g['BALANCE'].iloc[0],
'TYPE_COMPTE': g['TYPE_COMPTE'].iloc[0],
'STATUT_COMPTE': g['STATUT_COMPTE'].iloc[0],
'NATURE': g['NATURE'].iloc[0],
})
df_clients_corrige = df.groupby('NUMERO').apply(fusion_client).reset_index(drop=True)
return df_clients_corrige
df_corrige_clients = fusion_clients(df_corrige)
print(f"Nombre clients avant correction : {df_corrige['NUMERO'].nunique()}")
print(f"Nombre clients après correction : {df_corrige_clients['NUMERO'].nunique()}")
display(df_corrige_clients.head())
Nombre clients avant correction : 33145 Nombre clients après correction : 33145
| NUMERO | SEXE_CLIENT | DATENAIS | NOCOMPTE | SUCC | ZONE | DATEOPEN | BALANCE | TYPE_COMPTE | STATUT_COMPTE | NATURE | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 131 | Femme | 1969-12-03 | 1360000676 | LGN | OUEST | 2021-03-03 | 72367.70 | Compte Courant | Ouvert | Particulier |
| 1 | 176 | Homme | 1958-05-21 | 1510055419 | FTL | NORD | 2021-07-19 | 3146.73 | Dépôt à terme | Ouvert | Particulier |
| 2 | 254 | Homme | 1957-11-23 | 210065754 | GNV | NORD | 2021-12-28 | 2581.43 | Dépôt à terme | Dormant | Particulier |
| 3 | 256 | Femme | 1971-01-18 | 2040000191 | LGN | OUEST | 2021-01-09 | 86076.40 | Compte Courant | Ouvert | Particulier |
| 4 | 298 | Homme | 1984-12-29 | 1610070272 | FDN | EST | 2021-01-01 | 2664348.59 | Dépôt à terme | Ouvert | Particulier |
Vérification post-correction
# Chaque client doit avoir un seul SEXE_CLIENT et une seule DATENAIS
# 1. Sexe unique par client
sexe_unique = df_corrige_clients.groupby('NUMERO')['SEXE_CLIENT'].nunique()
clients_plusieurs_sexe = sexe_unique[sexe_unique > 1]
if clients_plusieurs_sexe.empty:
print(" Tous les clients ont un SEXE_CLIENT unique après correction.")
else:
print(f" Clients avec plusieurs SEXE_CLIENT après correction : {len(clients_plusieurs_sexe)}")
display(df_corrige_clients[df_corrige_clients['NUMERO'].isin(clients_plusieurs_sexe.index)]
.sort_values('NUMERO'))
# 2. Date de naissance unique par client
date_unique = df_corrige_clients.groupby('NUMERO')['DATENAIS'].nunique()
clients_plusieurs_dates = date_unique[date_unique > 1]
if clients_plusieurs_dates.empty:
print(" Tous les clients ont une DATENAIS unique après correction.")
else:
print(f" Clients avec plusieurs DATENAIS après correction : {len(clients_plusieurs_dates)}")
display(df_corrige_clients[df_corrige_clients['NUMERO'].isin(clients_plusieurs_dates.index)]
.sort_values('NUMERO'))
Tous les clients ont un SEXE_CLIENT unique après correction. Tous les clients ont une DATENAIS unique après correction.
Insertion dans FactCompte
import pandas as pd
import pyodbc
dimClient_df = pd.read_sql("SELECT * FROM DimClient", conn)
dimTypeCompte_df = pd.read_sql("SELECT * FROM DimTypeCompte", conn)
dimStatutCompte_df = pd.read_sql("SELECT * FROM DimStatutCompte", conn)
dimSucc_df = pd.read_sql("SELECT * FROM DimSuccursale", conn)
dimZone_df = pd.read_sql("SELECT * FROM DimZone", conn)
dimDate_df = pd.read_sql("SELECT * FROM DimDate", conn)
dimCompte_df = pd.read_sql("SELECT * FROM DimCompte", conn)
# 1. Vider la table FactCompte avant insertion
print("Vider la table FactCompte...")
cur.execute("DELETE FROM FactCompte;")
conn.commit()
print("Table FactCompte vidée.")
# 2. Assurer que les colonnes clés sont bien au format string pour éviter erreurs de merge
print("Conversion des types dans les DataFrames...")
df_corrige_clients['NUMERO'] = df_corrige_clients['NUMERO'].astype(str)
dimClient_df['Numero'] = dimClient_df['Numero'].astype(str)
df_corrige_clients['TYPE_COMPTE'] = df_corrige_clients['TYPE_COMPTE'].astype(str)
dimTypeCompte_df['TypeCompte'] = dimTypeCompte_df['TypeCompte'].astype(str)
df_corrige_clients['STATUT_COMPTE'] = df_corrige_clients['STATUT_COMPTE'].astype(str)
dimStatutCompte_df['StatutCompte'] = dimStatutCompte_df['StatutCompte'].astype(str)
df_corrige_clients['SUCC'] = df_corrige_clients['SUCC'].astype(str)
dimSucc_df['CodeSucc'] = dimSucc_df['CodeSucc'].astype(str)
df_corrige_clients['ZONE'] = df_corrige_clients['ZONE'].astype(str)
dimZone_df['CodeZone'] = dimZone_df['CodeZone'].astype(str)
df_corrige_clients['DATEOPEN'] = pd.to_datetime(df_corrige_clients['DATEOPEN'])
dimDate_df['DateComplete'] = pd.to_datetime(dimDate_df['DateComplete'])
dimCompte_df['NumeroCompte'] = dimCompte_df['NumeroCompte'].astype(str)
df_corrige_clients['NOCOMPTE'] = df_corrige_clients['NOCOMPTE'].astype(str)
print("Conversion terminée.")
# 3. Fusionner les DataFrames dimensionnels avec le DataFrame principal df_corrige_clients
print("Fusion des dimensions avec les données clients corrigées...")
df_fact = (
df_corrige_clients
.merge(dimClient_df, left_on='NUMERO', right_on='Numero', how='inner')
.merge(dimTypeCompte_df, left_on='TYPE_COMPTE', right_on='TypeCompte', how='inner')
.merge(dimStatutCompte_df, left_on='STATUT_COMPTE', right_on='StatutCompte', how='inner')
.merge(dimSucc_df, left_on='SUCC', right_on='NomSuccursale', how='inner')
.merge(dimZone_df, left_on='ZONE', right_on='CodeZone', how='inner')
.merge(dimDate_df, left_on='DATEOPEN', right_on='DateComplete', how='inner')
.merge(dimCompte_df[['ID_Compte', 'NumeroCompte']], left_on='NOCOMPTE', right_on='NumeroCompte', how='inner')
)
print(f"Taille finale après merge : {df_fact.shape}")
# 4. Préparer le DataFrame final à insérer dans FactCompte
print("Préparation du DataFrame final pour insertion...")
df_fact_final = pd.DataFrame({
'ID_Compte': df_fact['ID_Compte'],
'ID_TypeCompte': df_fact['ID_TypeCompte'],
'ID_Statut': df_fact['ID_Statut'],
'ID_Succ': df_fact['ID_Succ'],
'ID_Zone': df_fact['ID_Zone'],
'ID_Client': df_fact['ID_Client'],
'ID_DateOpen': df_fact['ID_Date'],
'BALANCE': df_fact['BALANCE'],
'NombreComptes': 1 # Chaque ligne représente un compte
})
print(f"Nombre de lignes à insérer : {len(df_fact_final)}")
# 5. Insertion dans la table FactCompte
print("Insertion des données dans FactCompte...")
# Préparer la requête d'insertion paramétrée
insert_query = """
INSERT INTO FactCompte
(ID_Compte, ID_TypeCompte, ID_Statut, ID_Succ, ID_Zone, ID_Client, ID_DateOpen, BALANCE, NombreComptes)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)
"""
# Itérer sur les lignes et insérer
for index, row in df_fact_final.iterrows():
cur.execute(insert_query,
row['ID_Compte'], row['ID_TypeCompte'], row['ID_Statut'], row['ID_Succ'],
row['ID_Zone'], row['ID_Client'], row['ID_DateOpen'], row['BALANCE'], row['NombreComptes'])
conn.commit()
print(f"Insertion terminée : {len(df_fact_final)} lignes insérées.")
Vider la table FactCompte... Table FactCompte vidée. Conversion des types dans les DataFrames... Conversion terminée. Fusion des dimensions avec les données clients corrigées... Taille finale après merge : (33111, 35) Préparation du DataFrame final pour insertion... Nombre de lignes à insérer : 33111 Insertion des données dans FactCompte... Insertion terminée : 33111 lignes insérées.
Diagnostique des lignes du csv qui n'ont pas été insérées dans FactCompte
# Étape 1 : Créer clé unique dans df_corrige_clients
df_corrige_clients['unique_key'] = (
df_corrige_clients['NOCOMPTE'].astype(str).str.strip() + '|' +
df_corrige_clients['NUMERO'].astype(str).str.strip() + '|' +
df_corrige_clients['DATEOPEN'].astype(str).str.strip()
)
# Étape 2 : Créer clé unique dans df_fact
df_fact['unique_key'] = (
df_fact['NOCOMPTE'].astype(str).str.strip() + '|' +
df_fact['NUMERO'].astype(str).str.strip() + '|' +
df_fact['DATEOPEN'].astype(str).str.strip()
)
# Étape 3 : Identifier les clés dans CSV mais absentes du DataFrame fusionné
missing_keys = set(df_corrige_clients['unique_key']) - set(df_fact['unique_key'])
if missing_keys:
print(f" {len(missing_keys)} lignes dans le CSV n'ont pas été insérées dans FactCompte.")
missing_rows = df_corrige_clients[df_corrige_clients['unique_key'].isin(missing_keys)]
missing_rows.to_csv("lignes_non_insertees_factcompte.csv", index=False)
else:
print(" Toutes les lignes du CSV sont bien présentes dans FactCompte.")
34 lignes dans le CSV n'ont pas été insérées dans FactCompte.
Exploration des données avec SQL et Seaborn
Dans cette partie, une répone sera donnée aux questions suivantes:
- Classement des comptes par solde dans chaque succursale
- Top 5 comptes par solde et par succursale
- Top 3 comptes par type de compte, avec le solde du compte et la moyenne des soldes pour ce type de compte
- La somme totale des soldes (Balance) de tous les comptes ouverts à cette date,ainsi que le cumul cumulé des soldes depuis le début de la période.
- Évolution annuelle par succursale : Solde, SoldeAvant, Variation
- Afficher pour chaque type de compte la somme totale du solde et le nombre total de comptes et le pourcentage du total
- Afficher pour chaque succursale les informations sur le premier et le dernier compte ouvert
- Pour chaque succursale, quel est le nombre de comptes et le solde total répartis par quartile
- Comparer le solde d’un compte avec le suivant (dans l’ordre d’ouverture)
- Quelle est, pour chaque succursale, la contribution des 10 % de comptes ayant les soldes les plus élevés par rapport au solde total de la succursale
- Nombre de clients par succursale et type de compte, limité aux 10 % de comptes aux soldes les plus élevés
- Quel est le montant total des soldes par succursale et type de compte, par succursale, par type de compte, ainsi qu’un total général
- Donner le nombre total de comptes et le solde total regroupés succursale, type de compte en affichant aussi les sous-totaux et le total général
- Calculer les totaux et sous-totaux pour toutes les combinaisons de succursales et de types de compte.
Classement des comptes par solde dans chaque succursale
query = """
SELECT
ds.NomSuccursale,
dc.NumeroCompte,
fc.Balance,
RANK() OVER (PARTITION BY ds.NomSuccursale ORDER BY fc.Balance DESC) AS RangSuccursale
FROM FactCompte fc
JOIN DimCompte dc ON fc.ID_Compte = dc.ID_Compte
JOIN DimSuccursale ds ON fc.ID_Succ = ds.ID_Succ;
"""
# Exécution de la requête via pandas
df = pd.read_sql(query, conn)
# Affichage des premières lignes
print(df.head(10))
NomSuccursale NumeroCompte Balance RangSuccursale 0 CAY 410038897 15708748.80 1 1 CAY 460000502 11184019.24 2 2 CAY 410027272 7940731.79 3 3 CAY 460000582 5016152.52 4 4 CAY 410020976 4056270.49 5 5 CAY 440000566 2937792.88 6 6 CAY 410017847 2880232.26 7 7 CAY 410018770 2735486.99 8 8 CAY 410016957 2488651.59 9 9 CAY 410024096 2325067.85 10
Top 5 comptes par solde et par succursale
query = """
SELECT *
FROM (
SELECT
ds.NomSuccursale,
dc.NumeroCompte,
fc.Balance,
RANK() OVER (
PARTITION BY ds.NomSuccursale
ORDER BY fc.Balance DESC
) AS RangSuccursale
FROM FactCompte fc
JOIN DimSuccursale ds ON fc.ID_Succ = ds.ID_Succ
LEFT JOIN DimCompte dc ON fc.ID_Compte = dc.ID_Compte
) AS Classement
WHERE RangSuccursale <= 5
ORDER BY NomSuccursale, RangSuccursale;
"""
# Exécution de la requête via pandas
df = pd.read_sql(query, conn)
# Affichage des premières lignes
df
| NomSuccursale | NumeroCompte | Balance | RangSuccursale | |
|---|---|---|---|---|
| 0 | CAY | 410038897 | 15708748.80 | 1 |
| 1 | CAY | 460000502 | 11184019.24 | 2 |
| 2 | CAY | 410027272 | 7940731.79 | 3 |
| 3 | CAY | 460000582 | 5016152.52 | 4 |
| 4 | CAY | 410020976 | 4056270.49 | 5 |
| 5 | FDN | 1640001727 | 27449360.00 | 1 |
| 6 | FDN | 1610067884 | 18682671.21 | 2 |
| 7 | FDN | 1640001730 | 16344527.91 | 3 |
| 8 | FDN | 1610117201 | 14509787.47 | 4 |
| 9 | FDN | 1610130828 | 14445164.48 | 5 |
| 10 | FTL | 1540000603 | 24763994.89 | 1 |
| 11 | FTL | 360000086 | 11581255.83 | 2 |
| 12 | FTL | 1510069853 | 9945688.69 | 3 |
| 13 | FTL | 310010538 | 9619282.22 | 4 |
| 14 | FTL | 2110006266 | 8807615.00 | 5 |
| 15 | GNV | 260001137 | 19418795.84 | 1 |
| 16 | GNV | 1650117234 | 13926898.67 | 2 |
| 17 | GNV | 260001160 | 5731949.79 | 3 |
| 18 | GNV | 210033271 | 5320459.48 | 4 |
| 19 | GNV | 93000000686 | 5034299.93 | 5 |
| 20 | LGN | 1650115205 | 25869420.32 | 1 |
| 21 | LGN | 1650116307 | 24077649.78 | 2 |
| 22 | LGN | 1260000709 | 23877495.82 | 3 |
| 23 | LGN | 4240000297 | 23011096.48 | 4 |
| 24 | LGN | 2440000648 | 22091207.35 | 5 |
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(16, 6))
ax = sns.barplot(
data=df,
x="Balance",
y="NumeroCompte",
hue="NomSuccursale",
dodge=False,
palette="Set2"
)
# Ajouter les valeurs numériques
offset = max(df["Balance"]) * 0.005
for p in ax.patches:
width = p.get_width()
y = p.get_y() + p.get_height() / 2
ax.text(width + offset, y, f"{width:,.0f}", va='center', fontsize=8)
# Rotation des étiquettes Y
plt.yticks(rotation=45, ha='right')
# Titre et étiquettes
plt.title("Top 5 comptes par succursale", fontsize=12)
plt.xlabel("Solde (Balance)", fontsize=11)
plt.ylabel("", fontsize=2)
# Légende en bas, centrée
plt.legend(
title="Succursale",
loc="upper center",
bbox_to_anchor=(0.5, -0.08),
ncol=len(df["NomSuccursale"].unique()), # une colonne par élément pour une seule ligne
frameon=False
)
plt.tight_layout(pad=1.5)
plt.show()

Top 3 comptes par type de compte, avec le solde du compte et la moyenne des soldes pour ce type de compte
query = """
SELECT *
FROM (
SELECT
dc.NumeroCompte,
dt.TypeCompte,
fc.Balance,
AVG(fc.Balance) OVER (PARTITION BY dt.TypeCompte) AS MoyenneParType,
ROW_NUMBER() OVER (PARTITION BY dt.TypeCompte ORDER BY fc.Balance DESC) AS RangSolde
FROM
FactCompte fc
JOIN
DimTypeCompte dt ON fc.ID_TypeCompte = dt.ID_TypeCompte
JOIN
DimCompte dc ON fc.ID_Compte = dc.ID_Compte
) AS comptes_rangés
WHERE RangSolde <= 3
ORDER BY TypeCompte, RangSolde;
"""
# Exécution de la requête via pandas
df = pd.read_sql(query, conn)
# Affichage des premières lignes
df
| NumeroCompte | TypeCompte | Balance | MoyenneParType | RangSolde | |
|---|---|---|---|---|---|
| 0 | 1640001727 | Compte Courant | 27449360.00 | 304832.28 | 1 |
| 1 | 1540000603 | Compte Courant | 24763994.89 | 304832.28 | 2 |
| 2 | 1260000709 | Compte Courant | 23877495.82 | 304832.28 | 3 |
| 3 | 1650115205 | Compte de Prêt | 25869420.32 | 184249.70 | 1 |
| 4 | 1650116307 | Compte de Prêt | 24077649.78 | 184249.70 | 2 |
| 5 | 1650114495 | Compte de Prêt | 21347842.67 | 184249.70 | 3 |
| 6 | 1610130828 | Compte Epargne | 14445164.48 | 107061.88 | 1 |
| 7 | 1610135627 | Compte Epargne | 13079278.21 | 107061.88 | 2 |
| 8 | 2010000185 | Compte Epargne | 12701102.49 | 107061.88 | 3 |
| 9 | 1610067884 | Dépôt à terme | 18682671.21 | 259807.46 | 1 |
| 10 | 1610117201 | Dépôt à terme | 14509787.47 | 259807.46 | 2 |
| 11 | 1610089955 | Dépôt à terme | 13394114.79 | 259807.46 | 3 |
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(16, 6))
# Barplot : x = NumeroCompte, y = Balance, couleur = TypeCompte
ax = sns.barplot(
data=df,
x='NumeroCompte',
y='Balance',
hue='TypeCompte',
dodge=False,
palette='Set2'
)
# Ajouter le texte (valeur solde) au-dessus de chaque barre
for p in ax.patches:
height = p.get_height()
ax.text(
x=p.get_x() + p.get_width() / 2,
y=height + height * 0.01,
s=f"{height:,.0f}",
ha='center',
va='bottom',
fontsize=9
)
plt.title("Top 3 comptes par type de compte - Solde")
plt.xlabel("Numéro de compte")
plt.ylabel("Solde")
plt.xticks(rotation=45)
plt.legend(title="Type de compte", bbox_to_anchor=(1.05, 1), loc='upper left')
plt.tight_layout()
plt.show()

Afficher, pour chaque mois (année + mois), la somme totale des soldes (Balance) de tous les comptes ouverts à cette date,ainsi que le cumul cumulé des soldes depuis le début de la période.
query = """
SELECT
dd.Annee,
dd.Mois,
SUM(fc.Balance) AS SommeSoldes,
SUM(SUM(fc.Balance)) OVER (ORDER BY dd.Annee, dd.Mois) AS CumulSoldes
FROM
FactCompte fc
JOIN
DimDate dd ON fc.ID_DateOpen = dd.ID_Date
GROUP BY
dd.Annee, dd.Mois
ORDER BY
dd.Annee, dd.Mois;
"""
# Exécution de la requête via pandas
df = pd.read_sql(query, conn)
# Affichage des premières lignes
print(df.head(10))
Annee Mois SommeSoldes CumulSoldes 0 2021 1 30387335.89 30387335.89 1 2021 2 19643178.58 50030514.47 2 2021 3 13716319.67 63746834.14 3 2021 4 17964584.85 81711418.99 4 2021 5 15927160.22 97638579.21 5 2021 6 12862700.97 110501280.18 6 2021 7 31596390.27 142097670.45 7 2021 8 17595311.40 159692981.85 8 2021 9 22564630.21 182257612.06 9 2021 10 8764215.10 191021827.16
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as mtick
# Préparer les dates
df['Date'] = pd.to_datetime(df['Annee'].astype(str) + '-' + df['Mois'].astype(str) + '-01')
# Vue trimestrielle (ou annuelle)
df['Trimestre'] = df['Date'].dt.to_period('Q').dt.to_timestamp()
df['Annee'] = df['Date'].dt.year
# Agrégation trimestrielle
df_trim = df.groupby('Trimestre').agg({
'SommeSoldes': 'sum'
}).reset_index()
df_trim['CumulSoldes'] = df_trim['SommeSoldes'].cumsum()
# \Création de la figure avec 2 sous-graphes côte à côte
fig, axes = plt.subplots(1, 2, figsize=(16, 6), sharey=True)
# -------- Graphique mensuel --------
axes[0].bar(df['Date'], df['SommeSoldes'] / 1e6, color='skyblue', width=20, label='Somme M$')
axes[0].plot(df['Date'], df['CumulSoldes'] / 1e6, color='orange', marker='o', label='Cumul M$')
for i, row in df.iterrows():
axes[0].text(row['Date'], row['SommeSoldes'] / 1e6, f'{row["SommeSoldes"] / 1e6:.1f}', ha='center', va='bottom', fontsize=7, rotation=90)
axes[0].text(row['Date'], row['CumulSoldes'] / 1e6, f'{row["CumulSoldes"] / 1e6:.1f}', ha='center', va='bottom', fontsize=7, color='darkorange')
axes[0].set_title("Évolution mensuelle")
axes[0].set_xlabel("Mois")
axes[0].set_ylabel("Montants (M$)")
axes[0].yaxis.set_major_formatter(mtick.FuncFormatter(lambda x, _: f'{x:,.0f} M$'))
axes[0].tick_params(axis='x', rotation=45)
axes[0].grid(True, linestyle='--', alpha=0.5)
axes[0].grid(False)
# -------- Graphique trimestriel --------
axes[1].bar(df_trim['Trimestre'], df_trim['SommeSoldes'] / 1e6, color='lightgreen', width=60, label='Somme M$')
axes[1].plot(df_trim['Trimestre'], df_trim['CumulSoldes'] / 1e6, color='purple', marker='o', label='Cumul M$')
for i, row in df_trim.iterrows():
axes[1].text(row['Trimestre'], row['SommeSoldes'] / 1e6, f'{row["SommeSoldes"] / 1e6:.1f}', ha='center', va='bottom', fontsize=7, rotation=90)
axes[1].text(row['Trimestre'], row['CumulSoldes'] / 1e6, f'{row["CumulSoldes"] / 1e6:.1f}', ha='center', va='bottom', fontsize=7, color='purple')
axes[1].set_title("Évolution trimestrielle")
axes[1].set_xlabel("Trimestre")
axes[1].tick_params(axis='x', rotation=45)
axes[1].grid(True, linestyle='--', alpha=0.5)
axes[1].grid(False)
# Mise en forme globale
plt.suptitle("Évolution des soldes : Mensuelle vs Trimestrielle (en M$)", fontsize=14)
plt.tight_layout(rect=[0, 0, 1, 0.96])
plt.show()

Évolution annuelle par succursale : Solde, SoldeAvant, Variation
query = """
SELECT
dd.Annee,
ds.NomSuccursale,
SUM(fc.Balance) AS SommeSoldes,
LAG(SUM(fc.Balance)) OVER (
PARTITION BY ds.NomSuccursale ORDER BY dd.Annee
) AS SommeSoldesAvant,
SUM(fc.Balance) - LAG(SUM(fc.Balance)) OVER (
PARTITION BY ds.NomSuccursale ORDER BY dd.Annee
) AS VariationAbsolue
FROM
FactCompte fc
JOIN
DimDate dd ON fc.ID_DateOpen = dd.ID_Date
JOIN
DimSuccursale ds ON fc.ID_Succ = ds.ID_Succ
GROUP BY
dd.Annee, ds.NomSuccursale
ORDER BY
dd.Annee, ds.NomSuccursale;
"""
# Exécution de la requête via pandas
df = pd.read_sql(query, conn)
# Affichage des premières lignes
df
| Annee | NomSuccursale | SommeSoldes | SommeSoldesAvant | VariationAbsolue | |
|---|---|---|---|---|---|
| 0 | 2021 | CAY | 265190.17 | NaN | NaN |
| 1 | 2021 | FDN | 175825354.63 | NaN | NaN |
| 2 | 2021 | FTL | 11332568.82 | NaN | NaN |
| 3 | 2021 | GNV | 965497.04 | NaN | NaN |
| 4 | 2021 | LGN | 31037238.22 | NaN | NaN |
| 5 | 2022 | CAY | 3832394.46 | 265190.17 | 3567204.29 |
| 6 | 2022 | FDN | 583685804.49 | 175825354.63 | 407860449.86 |
| 7 | 2022 | FTL | 13529171.04 | 11332568.82 | 2196602.22 |
| 8 | 2022 | GNV | 143971030.61 | 965497.04 | 143005533.57 |
| 9 | 2022 | LGN | 46557613.36 | 31037238.22 | 15520375.14 |
| 10 | 2023 | CAY | 178062973.02 | 3832394.46 | 174230578.56 |
| 11 | 2023 | FDN | 404862303.12 | 583685804.49 | -178823501.37 |
| 12 | 2023 | FTL | 357822716.27 | 13529171.04 | 344293545.23 |
| 13 | 2023 | GNV | 59059224.88 | 143971030.61 | -84911805.73 |
| 14 | 2023 | LGN | 1697621435.51 | 46557613.36 | 1651063822.15 |
| 15 | 2024 | CAY | 64871326.45 | 178062973.02 | -113191646.57 |
| 16 | 2024 | FDN | 258780179.29 | 404862303.12 | -146082123.83 |
| 17 | 2024 | FTL | 319582369.31 | 357822716.27 | -38240346.96 |
| 18 | 2024 | GNV | 64740080.33 | 59059224.88 | 5680855.45 |
| 19 | 2024 | LGN | 741683505.96 | 1697621435.51 | -955937929.55 |
| 20 | 2025 | CAY | 52723466.99 | 64871326.45 | -12147859.46 |
| 21 | 2025 | FDN | 211167125.30 | 258780179.29 | -47613053.99 |
| 22 | 2025 | FTL | 216074698.92 | 319582369.31 | -103507670.39 |
| 23 | 2025 | GNV | 55857973.91 | 64740080.33 | -8882106.42 |
| 24 | 2025 | LGN | 265166458.80 | 741683505.96 | -476517047.16 |
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# Convertir l'année en entier au besoin
df['Annee'] = df['Annee'].astype(int)
# Transformation en format long
df_melt = df.melt(
id_vars=['Annee', 'NomSuccursale'],
value_vars=['SommeSoldes', 'SommeSoldesAvant', 'VariationAbsolue'],
var_name='Type',
value_name='Valeur'
)
plt.figure(figsize=(16, 6))
ax = sns.barplot(data=df_melt, x='Annee', y='Valeur', hue='Type', ci=None)
# Ajouter les étiquettes de valeur sur chaque barre
for container in ax.containers:
ax.bar_label(container, fmt='%.1f', label_type='edge', fontsize=9, padding=3)
plt.title('Évolution annuelle par succursale : Solde, SoldeAvant, Variation')
plt.xlabel('Année')
plt.ylabel('Montant')
plt.legend(title='Mesure')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()

Afficher pour chaque type de compte la somme totale du solde et le nombre total de comptes et le pourcentage du total
query = """
SELECT
ds.NomSuccursale,
dt.TypeCompte,
COUNT(DISTINCT fc.ID_Compte) AS NombreComptes,
CAST(SUM(fc.Balance) / 1000000.0 AS DECIMAL(18, 2)) AS SommeSoldes_Millions,
CAST(
SUM(fc.Balance) * 1.0 / SUM(SUM(fc.Balance)) OVER (PARTITION BY ds.NomSuccursale)
AS DECIMAL(5, 2)
) AS PourcentageTotal
FROM
FactCompte fc
JOIN
DimTypeCompte dt ON fc.ID_TypeCompte = dt.ID_TypeCompte
JOIN
DimSuccursale ds ON fc.ID_Succ = ds.ID_Succ
GROUP BY
ds.NomSuccursale, dt.TypeCompte
ORDER BY
ds.NomSuccursale, SommeSoldes_Millions DESC;
"""
# Exécution de la requête via pandas
df = pd.read_sql(query, conn)
# Affichage des premières lignes
df
| NomSuccursale | TypeCompte | NombreComptes | SommeSoldes_Millions | PourcentageTotal | |
|---|---|---|---|---|---|
| 0 | CAY | Compte Courant | 705 | 158.19 | 0.53 |
| 1 | CAY | Compte Epargne | 1385 | 111.07 | 0.37 |
| 2 | CAY | Compte de Prêt | 967 | 27.86 | 0.09 |
| 3 | CAY | Dépôt à terme | 19 | 2.64 | 0.01 |
| 4 | FDN | Dépôt à terme | 2385 | 688.34 | 0.42 |
| 5 | FDN | Compte Epargne | 1796 | 377.22 | 0.23 |
| 6 | FDN | Compte de Prêt | 2249 | 374.31 | 0.23 |
| 7 | FDN | Compte Courant | 600 | 194.46 | 0.12 |
| 8 | FTL | Compte Epargne | 5599 | 489.83 | 0.53 |
| 9 | FTL | Compte de Prêt | 2438 | 198.22 | 0.22 |
| 10 | FTL | Compte Courant | 856 | 188.82 | 0.21 |
| 11 | FTL | Dépôt à terme | 182 | 41.48 | 0.05 |
| 12 | GNV | Dépôt à terme | 917 | 144.06 | 0.44 |
| 13 | GNV | Compte Epargne | 1730 | 112.41 | 0.35 |
| 14 | GNV | Compte Courant | 124 | 44.66 | 0.14 |
| 15 | GNV | Compte de Prêt | 931 | 23.46 | 0.07 |
| 16 | LGN | Compte de Prêt | 4610 | 1438.83 | 0.52 |
| 17 | LGN | Compte Courant | 2664 | 922.48 | 0.33 |
| 18 | LGN | Compte Epargne | 2717 | 325.58 | 0.12 |
| 19 | LGN | Dépôt à terme | 237 | 95.17 | 0.03 |
import matplotlib.pyplot as plt
import seaborn as sns
# Configuration générale
sns.set_style("whitegrid")
fig, axes = plt.subplots(1, 2, figsize=(22, 8)) # Deux graphiques côte à côte
# -------- Graphique 1 : Somme des soldes --------
sns.barplot(
data=df,
x="NomSuccursale",
y="SommeSoldes_Millions",
hue="TypeCompte",
ax=axes[0],
palette="Set2"
)
axes[0].set_title("Soldes (en millions) par type de compte et succursale", fontsize=13)
axes[0].set_ylabel("Montant (millions)")
axes[0].set_xlabel("Succursale")
axes[0].tick_params(axis='x', rotation=45)
axes[0].legend(title="Type de compte", fontsize=9)
axes[0].grid(False)
# Ajouter les valeurs sur les barres
for container in axes[0].containers:
axes[0].bar_label(container, fmt='%.2f', label_type='edge', fontsize=9)
# -------- Graphique 2 : Nombre de comptes --------
sns.barplot(
data=df,
x="NomSuccursale",
y="NombreComptes",
hue="TypeCompte",
ax=axes[1],
palette="Set2"
)
axes[1].set_title("Nombre de comptes par type de compte et succursale", fontsize=13)
axes[1].set_ylabel("Nombre de comptes")
axes[1].set_xlabel("Succursale")
axes[1].tick_params(axis='x', rotation=45)
axes[1].legend(title="Type de compte", fontsize=9)
axes[1].grid(False)
# Ajouter les valeurs sur les barres
for container in axes[1].containers:
axes[1].bar_label(container, fmt='%d', label_type='edge', fontsize=9)
# Ajustement du layout
plt.tight_layout()
plt.show()

Afficher pour chaque succursale les informations sur le premier et le dernier compte ouvert
query = """
SELECT DISTINCT
ds.NomSuccursale,
-- Premier compte (le plus ancien)
FIRST_VALUE(dc.NumeroCompte) OVER (PARTITION BY ds.ID_Succ ORDER BY dc.DateOpen ASC) AS PremierNumeroCompte,
FIRST_VALUE(fc.Balance) OVER (PARTITION BY ds.ID_Succ ORDER BY dc.DateOpen ASC) AS PremierSolde,
FIRST_VALUE(dc.DateOpen) OVER (PARTITION BY ds.ID_Succ ORDER BY dc.DateOpen ASC) AS DateOuverturePremierCompte,
-- Dernier compte (le plus récent)
LAST_VALUE(dc.NumeroCompte) OVER (
PARTITION BY ds.ID_Succ
ORDER BY dc.DateOpen ASC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS DernierNumeroCompte,
LAST_VALUE(fc.Balance) OVER (
PARTITION BY ds.ID_Succ
ORDER BY dc.DateOpen ASC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS DernierSolde,
LAST_VALUE(dc.DateOpen) OVER (
PARTITION BY ds.ID_Succ
ORDER BY dc.DateOpen ASC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS DateOuvertureDernierCompte
FROM FactCompte fc
JOIN DimSuccursale ds ON fc.ID_Succ = ds.ID_Succ
JOIN DimCompte dc ON fc.ID_Compte = dc.ID_Compte
ORDER BY ds.NomSuccursale;
"""
# Exécution de la requête via pandas
df = pd.read_sql(query, conn)
# Affichage des premières lignes
df
| NomSuccursale | PremierNumeroCompte | PremierSolde | DateOuverturePremierCompte | DernierNumeroCompte | DernierSolde | DateOuvertureDernierCompte | |
|---|---|---|---|---|---|---|---|
| 0 | CAY | 410018270 | 120.13 | 2021-02-22 | 410055820 | 14501.34 | 2025-08-13 |
| 1 | FDN | 1610133509 | 5100218.35 | 2021-01-01 | 1610135165 | 15642.53 | 2025-08-13 |
| 2 | FTL | 310044496 | 1002.54 | 2021-02-26 | 2110013012 | 45100.48 | 2025-08-13 |
| 3 | GNV | 210046761 | 74470.47 | 2021-04-28 | 210079064 | 495.91 | 2025-08-13 |
| 4 | LGN | 4240000222 | 261145.13 | 2021-01-09 | 3440000651 | 262910.98 | 2025-08-13 |
Pour chaque succursale, quel est le nombre de comptes et le solde total répartis par quartile ?
query = """
SELECT DISTINCT
NomSuccursale,
QuartilSolde,
COUNT(*) OVER (PARTITION BY NomSuccursale, QuartilSolde) AS NbComptesQuartil,
SUM(Balance) OVER (PARTITION BY NomSuccursale, QuartilSolde) AS SoldeQuartil
FROM (
SELECT
ds.NomSuccursale,
fc.Balance,
NTILE(4) OVER (ORDER BY fc.Balance) AS QuartilSolde
FROM FactCompte fc
JOIN DimSuccursale ds ON fc.ID_Succ = ds.ID_Succ
) T
ORDER BY NomSuccursale, QuartilSolde;
"""
# Exécution de la requête via pandas
df = pd.read_sql(query, conn)
# Affichage des premières lignes
df
| NomSuccursale | QuartilSolde | NbComptesQuartil | SoldeQuartil | |
|---|---|---|---|---|
| 0 | CAY | 1 | 865 | 982484.21 |
| 1 | CAY | 2 | 1250 | 23599021.08 |
| 2 | CAY | 3 | 614 | 32143472.12 |
| 3 | CAY | 4 | 347 | 243030373.68 |
| 4 | FDN | 1 | 1167 | 1367225.98 |
| 5 | FDN | 2 | 1427 | 18976948.88 |
| 6 | FDN | 3 | 975 | 68406701.61 |
| 7 | FDN | 4 | 3461 | 1545569890.36 |
| 8 | FTL | 1 | 2445 | 2979848.67 |
| 9 | FTL | 2 | 2997 | 38912301.51 |
| 10 | FTL | 3 | 2098 | 177516914.98 |
| 11 | FTL | 4 | 1535 | 698932459.20 |
| 12 | GNV | 1 | 1859 | 1841688.31 |
| 13 | GNV | 2 | 962 | 10560157.67 |
| 14 | GNV | 3 | 440 | 31016677.01 |
| 15 | GNV | 4 | 441 | 281175283.78 |
| 16 | LGN | 1 | 1942 | 1966886.60 |
| 17 | LGN | 2 | 1642 | 20140847.61 |
| 18 | LGN | 3 | 4151 | 326474985.75 |
| 19 | LGN | 4 | 2493 | 2433483531.89 |
import pandas as pd
import matplotlib.pyplot as plt
# Pivots
pivot_nb = df.pivot(index='NomSuccursale', columns='QuartilSolde', values='NbComptesQuartil').fillna(0)
pivot_solde = df.pivot(index='NomSuccursale', columns='QuartilSolde', values='SoldeQuartil').fillna(0)
quartiles = sorted(df['QuartilSolde'].unique())
colors = ['#4c72b0', '#55a868', '#c44e52', '#8172b3']
fig, axes = plt.subplots(1, 2, figsize=(16, 7), sharey=False)
def add_labels(ax, data):
cum_values = data.cumsum(axis=1)
for i, col in enumerate(data.columns):
for j, val in enumerate(data[col]):
if val > 0:
height = cum_values.iloc[j, i]
bottom = cum_values.iloc[j, i] - val
ax.text(j, bottom + val/2, f'{val:,.0f}', ha='center', va='center', fontsize=8, color='white')
totals = data.sum(axis=1)
for idx, total in enumerate(totals):
ax.text(idx, total + total*0.01, f'Total: {total:,.0f}', ha='center', va='bottom', fontsize=9, fontweight='bold')
# Graphique 1
pivot_nb[quartiles].plot(kind='bar', stacked=True, color=colors, ax=axes[0])
axes[0].set_title("Nombre de comptes par succursale et quartile")
axes[0].set_ylabel("Nombre de comptes")
axes[0].set_xlabel("Succursale")
axes[0].legend(title='Quartile Solde')
add_labels(axes[0], pivot_nb[quartiles])
axes[0].grid(False) # Supprime la grille
# Graphique 2
pivot_solde[quartiles].plot(kind='bar', stacked=True, color=colors, ax=axes[1])
axes[1].set_title("Montant total par succursale et quartile")
axes[1].set_ylabel("Montant total")
axes[1].set_xlabel("Succursale")
axes[1].legend(title='Quartile Solde')
add_labels(axes[1], pivot_solde[quartiles])
axes[1].grid(False) # Supprime la grille
plt.tight_layout()
plt.show()

Comparer le solde d’un compte avec le suivant (dans l’ordre d’ouverture)
query = """
SELECT
ds.NomSuccursale,
dc.NumeroCompte,
dc.DateOpen,
fc.Balance,
LEAD(fc.Balance) OVER (PARTITION BY ds.ID_Succ ORDER BY dc.DateOpen) AS SoldeCompteSuivant
FROM FactCompte fc
JOIN DimCompte dc ON fc.ID_Compte = dc.ID_Compte
JOIN DimSuccursale ds ON fc.ID_Succ = ds.ID_Succ;
"""
# Exécution de la requête via pandas
df = pd.read_sql(query, conn)
# Affichage des premières lignes
df
| NomSuccursale | NumeroCompte | DateOpen | Balance | SoldeCompteSuivant | |
|---|---|---|---|---|---|
| 0 | CAY | 410018270 | 2021-02-22 | 120.13 | 254393.84 |
| 1 | CAY | 410031729 | 2021-03-11 | 254393.84 | 572.00 |
| 2 | CAY | 410050751 | 2021-04-08 | 572.00 | 9299.15 |
| 3 | CAY | 410028410 | 2021-04-28 | 9299.15 | 805.05 |
| 4 | CAY | 461000010 | 2021-10-06 | 805.05 | 1724.17 |
| ... | ... | ... | ... | ... | ... |
| 33106 | FDN | 1610122540 | 2025-08-13 | 87791.30 | 97826.29 |
| 33107 | FDN | 1610134966 | 2025-08-13 | 97826.29 | 107592.29 |
| 33108 | FDN | 1670000087 | 2025-08-13 | 107592.29 | 76785.17 |
| 33109 | FDN | 1610126590 | 2025-08-13 | 76785.17 | 15375.00 |
| 33110 | FDN | 1640002038 | 2025-08-13 | 15375.00 | NaN |
33111 rows × 5 columns
Quelle est, pour chaque succursale, la contribution des 10 % de comptes ayant les soldes les plus élevés par rapport au solde total de la succursale
query = """
SELECT
Top10.NomSuccursale,
COUNT(*) AS NbComptesTop10,
SUM(Top10.Balance) AS SoldeTotalTop10,
Total.SoldeTotalSuccursale,
Total.NbComptesSuccursale,
ROUND(
1.0 * SUM(Top10.Balance) / NULLIF(Total.SoldeTotalSuccursale, 0), 4
) AS PartTop10Pourcent
FROM (
SELECT
ds.NomSuccursale,
fc.Balance,
CUME_DIST() OVER (PARTITION BY ds.ID_Succ ORDER BY fc.Balance DESC) AS RangPercentile
FROM FactCompte fc
JOIN DimSuccursale ds ON fc.ID_Succ = ds.ID_Succ
) AS Top10
JOIN (
SELECT
ds.NomSuccursale,
SUM(fc.Balance) AS SoldeTotalSuccursale,
COUNT(*) AS NbComptesSuccursale
FROM FactCompte fc
JOIN DimSuccursale ds ON fc.ID_Succ = ds.ID_Succ
GROUP BY ds.NomSuccursale
) AS Total
ON Top10.NomSuccursale = Total.NomSuccursale
WHERE Top10.RangPercentile <= 0.10
GROUP BY Top10.NomSuccursale, Total.SoldeTotalSuccursale, Total.NbComptesSuccursale
ORDER BY PartTop10Pourcent DESC;
"""
# Exécution de la requête via pandas
df = pd.read_sql(query, conn)
# Affichage des premières lignes
df
| NomSuccursale | NbComptesTop10 | SoldeTotalTop10 | SoldeTotalSuccursale | NbComptesSuccursale | PartTop10Pourcent | |
|---|---|---|---|---|---|---|
| 0 | GNV | 370 | 270152151.24 | 324593806.77 | 3702 | 0.83 |
| 1 | CAY | 307 | 236881722.49 | 299755351.09 | 3076 | 0.79 |
| 2 | LGN | 1020 | 2069392297.65 | 2782066251.85 | 10228 | 0.74 |
| 3 | FTL | 907 | 599951501.49 | 918341524.36 | 9075 | 0.65 |
| 4 | FDN | 703 | 1057247217.09 | 1634320766.83 | 7030 | 0.65 |
Nombre de clients par succursale et type de compte, limité aux 10 % de comptes aux soldes les plus élevés.
query = """
WITH ComptesTop10 AS (
SELECT
fc.ID_Compte,
fc.ID_Client,
fc.Balance,
fc.ID_Succ,
ds.NomSuccursale,
dt.TypeCompte,
ROUND(CUME_DIST() OVER (PARTITION BY fc.ID_Succ ORDER BY fc.Balance DESC), 4) AS RangCumul
FROM FactCompte fc
JOIN DimSuccursale ds ON fc.ID_Succ = ds.ID_Succ
JOIN DimTypeCompte dt ON fc.ID_TypeCompte = dt.ID_TypeCompte
JOIN DimClient dcl ON fc.ID_Client = dcl.ID_Client
)
SELECT
NomSuccursale,
TypeCompte,
COUNT(DISTINCT ID_Client) AS NombreClientsTop10,
ROUND(SUM(Balance), 2) AS SoldeTotal_Top10
FROM ComptesTop10
WHERE RangCumul <= 0.1
GROUP BY NomSuccursale, TypeCompte
ORDER BY NomSuccursale, TypeCompte;
"""
# Exécution de la requête via pandas
df = pd.read_sql(query, conn)
# Affichage des premières lignes
df
| NomSuccursale | TypeCompte | NombreClientsTop10 | SoldeTotal_Top10 | |
|---|---|---|---|---|
| 0 | CAY | Compte Courant | 159 | 145150476.41 |
| 1 | CAY | Compte Epargne | 145 | 89300766.25 |
| 2 | CAY | Dépôt à terme | 3 | 2430479.83 |
| 3 | FDN | Compte Courant | 81 | 176557815.77 |
| 4 | FDN | Compte Epargne | 206 | 310455454.97 |
| 5 | FDN | Dépôt à terme | 416 | 570233946.35 |
| 6 | FTL | Compte Courant | 143 | 164789045.98 |
| 7 | FTL | Compte de Prêt | 168 | 38430727.73 |
| 8 | FTL | Compte Epargne | 565 | 360492336.96 |
| 9 | FTL | Dépôt à terme | 31 | 36239390.82 |
| 10 | GNV | Compte Courant | 15 | 42053944.50 |
| 11 | GNV | Compte de Prêt | 24 | 20758567.77 |
| 12 | GNV | Compte Epargne | 156 | 85310007.87 |
| 13 | GNV | Dépôt à terme | 175 | 122029631.10 |
| 14 | LGN | Compte Courant | 336 | 835355711.62 |
| 15 | LGN | Compte de Prêt | 412 | 919751524.90 |
| 16 | LGN | Compte Epargne | 212 | 235313780.48 |
| 17 | LGN | Dépôt à terme | 63 | 80029942.25 |
import matplotlib.pyplot as plt
import seaborn as sns
# Assure-toi que ces colonnes existent bien
assert {'NomSuccursale', 'TypeCompte', 'NombreClientsTop10', 'SoldeTotal_Top10'}.issubset(df.columns)
# Configuration générale
sns.set(style="whitegrid")
fig, axes = plt.subplots(1, 2, figsize=(16, 6), sharey=False)
# Graphique 1 : Nombre de clients top 10% par type de compte et succursale
sns.barplot(
data=df,
x='NombreClientsTop10',
y='NomSuccursale',
hue='TypeCompte',
palette='tab10',
ax=axes[0]
)
axes[0].set_title("Nombre de clients par type de compte et succursale (Top 10 % des comptes par solde)", fontsize=12)
axes[0].set_xlabel("Nombre de clients")
axes[0].set_ylabel("Succursale")
axes[0].legend(title='Type de compte')
axes[0].grid(False)
# Affichage des valeurs sur les barres
for container in axes[0].containers:
axes[0].bar_label(container, fmt='%d', label_type='edge', fontsize=8)
# Graphique 2 : Solde total (Top 10%) par type de compte et succursale
sns.barplot(
data=df,
x='SoldeTotal_Top10',
y='NomSuccursale',
hue='TypeCompte',
palette='tab10',
ax=axes[1]
)
axes[1].set_title("Solde total par type de compte et succursale (Top 10 % des comptes par solde)", fontsize=12)
axes[1].set_xlabel("Solde total ($)")
axes[1].set_ylabel("") # Pas nécessaire, déjà dans le premier graphique
axes[1].legend(title='Type de compte')
axes[1].grid(False)
# Affichage des valeurs sur les barres
for container in axes[1].containers:
axes[1].bar_label(container, fmt='%.0f', label_type='edge', fontsize=8)
# Ajustement final
plt.tight_layout()
plt.show()

Quel est le montant total des soldes par succursale et type de compte, par succursale, par type de compte, ainsi qu’un total général ?
query = """
SELECT
NomSuccursale,
TypeCompte,
SUM(Balance) AS Solde,
CASE
WHEN GROUPING(NomSuccursale) = 0 AND GROUPING(TypeCompte) = 0 THEN 'Détail par Succursale et Type de Compte'
WHEN GROUPING(NomSuccursale) = 0 AND GROUPING(TypeCompte) = 1 THEN 'Total par Succursale'
WHEN GROUPING(NomSuccursale) = 1 AND GROUPING(TypeCompte) = 0 THEN 'Total par Type de Compte'
WHEN GROUPING(NomSuccursale) = 1 AND GROUPING(TypeCompte) = 1 THEN 'Total général'
END AS Commentaire
FROM FactCompte fc
JOIN DimSuccursale ds ON fc.ID_Succ = ds.ID_Succ
JOIN DimTypeCompte dt ON fc.ID_TypeCompte = dt.ID_TypeCompte
GROUP BY GROUPING SETS (
(NomSuccursale, TypeCompte),
(NomSuccursale),
(TypeCompte),
()
)
ORDER BY
GROUPING(NomSuccursale),
GROUPING(TypeCompte),
NomSuccursale,
TypeCompte;
"""
# Exécution de la requête via pandas
df = pd.read_sql(query, conn)
# Affichage des premières lignes
df
| NomSuccursale | TypeCompte | Solde | Commentaire | |
|---|---|---|---|---|
| 0 | CAY | Compte Courant | 158187695.31 | Détail par Succursale et Type de Compte |
| 1 | CAY | Compte de Prêt | 27856786.68 | Détail par Succursale et Type de Compte |
| 2 | CAY | Compte Epargne | 111073980.56 | Détail par Succursale et Type de Compte |
| 3 | CAY | Dépôt à terme | 2636888.54 | Détail par Succursale et Type de Compte |
| 4 | FDN | Compte Courant | 194459480.98 | Détail par Succursale et Type de Compte |
| 5 | FDN | Compte de Prêt | 374305510.78 | Détail par Succursale et Type de Compte |
| 6 | FDN | Compte Epargne | 377218989.69 | Détail par Succursale et Type de Compte |
| 7 | FDN | Dépôt à terme | 688336785.38 | Détail par Succursale et Type de Compte |
| 8 | FTL | Compte Courant | 188819268.13 | Détail par Succursale et Type de Compte |
| 9 | FTL | Compte de Prêt | 198216046.42 | Détail par Succursale et Type de Compte |
| 10 | FTL | Compte Epargne | 489825652.90 | Détail par Succursale et Type de Compte |
| 11 | FTL | Dépôt à terme | 41480556.91 | Détail par Succursale et Type de Compte |
| 12 | GNV | Compte Courant | 44663791.16 | Détail par Succursale et Type de Compte |
| 13 | GNV | Compte de Prêt | 23463229.96 | Détail par Succursale et Type de Compte |
| 14 | GNV | Compte Epargne | 112410627.74 | Détail par Succursale et Type de Compte |
| 15 | GNV | Dépôt à terme | 144056157.91 | Détail par Succursale et Type de Compte |
| 16 | LGN | Compte Courant | 922484731.25 | Détail par Succursale et Type de Compte |
| 17 | LGN | Compte de Prêt | 1438833802.24 | Détail par Succursale et Type de Compte |
| 18 | LGN | Compte Epargne | 325578213.96 | Détail par Succursale et Type de Compte |
| 19 | LGN | Dépôt à terme | 95169504.40 | Détail par Succursale et Type de Compte |
| 20 | CAY | None | 299755351.09 | Total par Succursale |
| 21 | FDN | None | 1634320766.83 | Total par Succursale |
| 22 | FTL | None | 918341524.36 | Total par Succursale |
| 23 | GNV | None | 324593806.77 | Total par Succursale |
| 24 | LGN | None | 2782066251.85 | Total par Succursale |
| 25 | None | Compte Courant | 1508614966.83 | Total par Type de Compte |
| 26 | None | Compte de Prêt | 2062675376.08 | Total par Type de Compte |
| 27 | None | Compte Epargne | 1416107464.85 | Total par Type de Compte |
| 28 | None | Dépôt à terme | 971679893.14 | Total par Type de Compte |
| 29 | None | None | 5959077700.90 | Total général |
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# Remplacement des valeurs manquantes
df['NomSuccursale'] = df['NomSuccursale'].fillna('Toutes Succursales')
df['TypeCompte'] = df['TypeCompte'].fillna('Tous Comptes')
# Combinaison hiérarchique pour affichage clair
df['Categorie'] = df['NomSuccursale'] + ' | ' + df['TypeCompte']
# Tri personnalisé : Succursales d'abord, puis totaux
ordre_personnalise = df.sort_values(by=['NomSuccursale', 'TypeCompte'], ascending=[True, True])['Categorie']
# Affichage horizontal
plt.figure(figsize=(16, 8))
palette = sns.color_palette("Set2", df['Commentaire'].nunique())
barplot = sns.barplot(
data=df,
y='Categorie',
x='Solde',
hue='Commentaire',
palette=palette,
order=ordre_personnalise
)
# Valeurs sur les barres
for container in barplot.containers:
barplot.bar_label(container, fmt='%.0f', label_type='edge', padding=3, fontsize=9)
plt.title("Solde par Succursale et Type de Compte")
plt.xlabel("Solde total")
plt.ylabel("", fontsize=2)
plt.tight_layout()
plt.legend(title="Niveau d'agrégation")
sns.despine() # Retire les bordures supérieures et droites
plt.grid(False) # Désactive la grille
plt.show()

Donner le nombre total de comptes et le solde total regroupés par succursale, type de compte en affichant aussi les sous-totaux et le total général
query = """
SELECT
s.NomSuccursale,
t.TypeCompte,
SUM(f.NombreComptes) AS TotalNombreComptes,
SUM(f.Balance) AS TotalBalance,
CASE
WHEN GROUPING(s.NomSuccursale) = 0 AND GROUPING(t.TypeCompte) = 0 THEN 'Détail Succursale + TypeCompte'
WHEN GROUPING(s.NomSuccursale) = 0 AND GROUPING(t.TypeCompte) = 1 THEN 'Total par Succursale'
WHEN GROUPING(s.NomSuccursale) = 1 AND GROUPING(t.TypeCompte) = 1 THEN 'Total Général'
END AS Commentaire
FROM FactCompte f
JOIN DimTypeCompte t ON f.ID_TypeCompte = t.ID_TypeCompte
JOIN DimSuccursale s ON f.ID_Succ = s.ID_Succ
GROUP BY ROLLUP(s.NomSuccursale, t.TypeCompte)
ORDER BY s.NomSuccursale, t.TypeCompte;
"""
# Exécution via pandas
df = pd.read_sql(query, conn)
# Affichage
df
| NomSuccursale | TypeCompte | TotalNombreComptes | TotalBalance | Commentaire | |
|---|---|---|---|---|---|
| 0 | None | None | 33111 | 5959077700.90 | Total Général |
| 1 | CAY | None | 3076 | 299755351.09 | Total par Succursale |
| 2 | CAY | Compte Courant | 705 | 158187695.31 | Détail Succursale + TypeCompte |
| 3 | CAY | Compte de Prêt | 967 | 27856786.68 | Détail Succursale + TypeCompte |
| 4 | CAY | Compte Epargne | 1385 | 111073980.56 | Détail Succursale + TypeCompte |
| 5 | CAY | Dépôt à terme | 19 | 2636888.54 | Détail Succursale + TypeCompte |
| 6 | FDN | None | 7030 | 1634320766.83 | Total par Succursale |
| 7 | FDN | Compte Courant | 600 | 194459480.98 | Détail Succursale + TypeCompte |
| 8 | FDN | Compte de Prêt | 2249 | 374305510.78 | Détail Succursale + TypeCompte |
| 9 | FDN | Compte Epargne | 1796 | 377218989.69 | Détail Succursale + TypeCompte |
| 10 | FDN | Dépôt à terme | 2385 | 688336785.38 | Détail Succursale + TypeCompte |
| 11 | FTL | None | 9075 | 918341524.36 | Total par Succursale |
| 12 | FTL | Compte Courant | 856 | 188819268.13 | Détail Succursale + TypeCompte |
| 13 | FTL | Compte de Prêt | 2438 | 198216046.42 | Détail Succursale + TypeCompte |
| 14 | FTL | Compte Epargne | 5599 | 489825652.90 | Détail Succursale + TypeCompte |
| 15 | FTL | Dépôt à terme | 182 | 41480556.91 | Détail Succursale + TypeCompte |
| 16 | GNV | None | 3702 | 324593806.77 | Total par Succursale |
| 17 | GNV | Compte Courant | 124 | 44663791.16 | Détail Succursale + TypeCompte |
| 18 | GNV | Compte de Prêt | 931 | 23463229.96 | Détail Succursale + TypeCompte |
| 19 | GNV | Compte Epargne | 1730 | 112410627.74 | Détail Succursale + TypeCompte |
| 20 | GNV | Dépôt à terme | 917 | 144056157.91 | Détail Succursale + TypeCompte |
| 21 | LGN | None | 10228 | 2782066251.85 | Total par Succursale |
| 22 | LGN | Compte Courant | 2664 | 922484731.25 | Détail Succursale + TypeCompte |
| 23 | LGN | Compte de Prêt | 4610 | 1438833802.24 | Détail Succursale + TypeCompte |
| 24 | LGN | Compte Epargne | 2717 | 325578213.96 | Détail Succursale + TypeCompte |
| 25 | LGN | Dépôt à terme | 237 | 95169504.40 | Détail Succursale + TypeCompte |
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# Séparer les lignes
df_detail = df[df['Commentaire'] == 'Détail Succursale + TypeCompte']
df_succ_tot = df[df['Commentaire'] == 'Total par Succursale']
plt.figure(figsize=(14,7))
# Barplot des détails
sns.barplot(
data=df_detail,
x='NomSuccursale',
y='TotalNombreComptes',
hue='TypeCompte',
dodge=True,
palette='pastel'
)
# Barplot des totaux par succursale (barres plus foncées)
sns.barplot(
data=df_succ_tot,
x='NomSuccursale',
y='TotalNombreComptes',
color='gray',
alpha=0.5,
edgecolor='black'
)
# Annotation des barres détaillées et des totaux par succursale
for p in plt.gca().patches:
height = p.get_height()
if height > 0:
plt.text(
x=p.get_x() + p.get_width()/2,
y=height + 1,
s=int(height),
ha='center',
fontsize=9
)
plt.title('Nombre total de comptes par Succursale et Type de Compte avec Totaux')
plt.xlabel('Succursale')
plt.ylabel('Nombre de comptes')
plt.xticks(rotation=45)
plt.legend(title='Type de Compte / Totaux')
plt.tight_layout()
plt.grid(False)
plt.show()

Calculer les totaux et sous-totaux pour toutes les combinaisons de succursales et de types de compte.
query = """
SELECT
s.NomSuccursale,
t.TypeCompte,
SUM(f.Balance)/1000000 AS SoldeTotal,
CASE
WHEN GROUPING(s.NomSuccursale) = 0 AND GROUPING(t.TypeCompte) = 0 THEN 'Détail Succursale + TypeCompte'
WHEN GROUPING(s.NomSuccursale) = 0 AND GROUPING(t.TypeCompte) = 1 THEN 'Total par Succursale'
WHEN GROUPING(s.NomSuccursale) = 1 AND GROUPING(t.TypeCompte) = 0 THEN 'Total par TypeCompte'
WHEN GROUPING(s.NomSuccursale) = 1 AND GROUPING(t.TypeCompte) = 1 THEN 'Total Général'
END AS Commentaire
FROM FactCompte f
JOIN DimSuccursale s ON f.ID_Succ = s.ID_Succ
JOIN DimTypeCompte t ON f.ID_TypeCompte = t.ID_TypeCompte
GROUP BY CUBE (s.NomSuccursale, t.TypeCompte)
ORDER BY ++
GROUPING(s.NomSuccursale),
GROUPING(t.TypeCompte),
s.NomSuccursale,
t.TypeCompte;
"""
# Exécution via pandas
df = pd.read_sql(query, conn)
# Affichage
df
| NomSuccursale | TypeCompte | SoldeTotal | Commentaire | |
|---|---|---|---|---|
| 0 | CAY | Compte Courant | 158.19 | Détail Succursale + TypeCompte |
| 1 | CAY | Compte de Prêt | 27.86 | Détail Succursale + TypeCompte |
| 2 | CAY | Compte Epargne | 111.07 | Détail Succursale + TypeCompte |
| 3 | CAY | Dépôt à terme | 2.64 | Détail Succursale + TypeCompte |
| 4 | FDN | Compte Courant | 194.46 | Détail Succursale + TypeCompte |
| 5 | FDN | Compte de Prêt | 374.31 | Détail Succursale + TypeCompte |
| 6 | FDN | Compte Epargne | 377.22 | Détail Succursale + TypeCompte |
| 7 | FDN | Dépôt à terme | 688.34 | Détail Succursale + TypeCompte |
| 8 | FTL | Compte Courant | 188.82 | Détail Succursale + TypeCompte |
| 9 | FTL | Compte de Prêt | 198.22 | Détail Succursale + TypeCompte |
| 10 | FTL | Compte Epargne | 489.83 | Détail Succursale + TypeCompte |
| 11 | FTL | Dépôt à terme | 41.48 | Détail Succursale + TypeCompte |
| 12 | GNV | Compte Courant | 44.66 | Détail Succursale + TypeCompte |
| 13 | GNV | Compte de Prêt | 23.46 | Détail Succursale + TypeCompte |
| 14 | GNV | Compte Epargne | 112.41 | Détail Succursale + TypeCompte |
| 15 | GNV | Dépôt à terme | 144.06 | Détail Succursale + TypeCompte |
| 16 | LGN | Compte Courant | 922.48 | Détail Succursale + TypeCompte |
| 17 | LGN | Compte de Prêt | 1438.83 | Détail Succursale + TypeCompte |
| 18 | LGN | Compte Epargne | 325.58 | Détail Succursale + TypeCompte |
| 19 | LGN | Dépôt à terme | 95.17 | Détail Succursale + TypeCompte |
| 20 | CAY | None | 299.76 | Total par Succursale |
| 21 | FDN | None | 1634.32 | Total par Succursale |
| 22 | FTL | None | 918.34 | Total par Succursale |
| 23 | GNV | None | 324.59 | Total par Succursale |
| 24 | LGN | None | 2782.07 | Total par Succursale |
| 25 | None | Compte Courant | 1508.61 | Total par TypeCompte |
| 26 | None | Compte de Prêt | 2062.68 | Total par TypeCompte |
| 27 | None | Compte Epargne | 1416.11 | Total par TypeCompte |
| 28 | None | Dépôt à terme | 971.68 | Total par TypeCompte |
| 29 | None | None | 5959.08 | Total Général |
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# Séparer les lignes
df_detail = df[df['Commentaire'] == 'Détail Succursale + TypeCompte']
df_succ_tot = df[df['Commentaire'] == 'Total par Succursale']
plt.figure(figsize=(14,7))
# Barplot pour les détails par type de compte
sns.barplot(
data=df_detail,
x='NomSuccursale',
y='SoldeTotal',
hue='TypeCompte',
dodge=True,
palette='pastel'
)
# Barplot pour les totaux par succursale (barres grises semi-transparentes)
sns.barplot(
data=df_succ_tot,
x='NomSuccursale',
y='SoldeTotal',
color='gray',
alpha=0.5,
edgecolor='black'
)
# Ajouter les valeurs sur les barres
for p in plt.gca().patches:
height = p.get_height()
if height > 0:
plt.text(
x=p.get_x() + p.get_width()/2,
y=height + 0.5,
s=int(height),
ha='center',
fontsize=9
)
plt.title('Solde total en Million par Succursale et Type de Compte avec Totaux', fontsize=14)
plt.xlabel('Succursale')
plt.ylabel('Solde Total en million')
plt.xticks(rotation=45)
plt.legend(title='Type de Compte / Totaux')
plt.tight_layout()
plt.grid(False)
plt.show()

Création du tableau de bord avec Tkinter
Présentation du tableau de Bord
Le tableau de bord est construit avec Tkinter et est constitué principalement de trois zones.
Une zone réservée aux différents KPIs
- Nombre de comptes ouverts
- Solde total
- Nombre de clients actifs
- Age moyen des clients
- Solde moyen
- Nombre de comptes dormants
Une zone réservée aux filtres et aux actions et rapports
- Filtrer par succursale
- Filtrer par zone
- Filtrer par type de compte
- Filtrer par statut du compte
- Filtrer par nature du compte
- Réinitialiser les filtres
- Rafraichir le tableau de bord
- Exportation en PDF
- Transmission par e-mail
- Rapport global détaillé
- Rapport par succursale
- Rapport de performance
- Rapports temporels
- Rapports géographiques
Une zone réservée aux visuels
- Répartition du solde moyen par type de compte
- Répartition des comptes par type
- Répartition des comptes par zone géographique
- Répartition des comptes par statut
- Répartition des comptes par sexe
- Répartition des comptes par succursale

Génération des rapports Excel avec Python
Rapport détaillé des données du Data WareHouse avec xlwings
import seaborn as sns
def hex_to_excel_color(hex_color: str) -> int:
hex_color = hex_color.lstrip('#')
if len(hex_color) != 6:
raise ValueError("La couleur doit être au format '#RRGGBB'")
r = int(hex_color[0:2], 16)
g = int(hex_color[2:4], 16)
b = int(hex_color[4:6], 16)
return r + (g << 8) + (b << 16)
# Génère une palette de 5 couleurs dégradées de bleu
blue_palette = sns.color_palette("Blues_d", 5).as_hex()
print(blue_palette)
green_palette = sns.color_palette("Greens_d", 5).as_hex()
print(green_palette)
['#85b8d9', '#5e9fcd', '#3787c0', '#366b91', '#344f62'] ['#87ca8c', '#5fb570', '#37a055', '#367c4a', '#34573e']
import pandas as pd
import pyodbc
import xlwings as xw
def generer_rapport_global_detaille(nom_fichier=None):
try:
# Connexion SQL Server
conn = pyodbc.connect(
'DRIVER={SQL Server};SERVER=DESKTOP-RUJ1AK0;DATABASE=BanqueDW;Trusted_Connection=yes'
)
# Requête SQL complète
requete = """
SELECT
dc.NumeroCompte,
dc.DateOpen,
dc.AncienneteJours,
dtc.TypeCompte,
ds.StatutCompte,
dsucc.CodeSucc,
dsucc.NomSuccursale,
dz.CodeZone,
dz.NomZone,
cli.Numero AS NumeroClient,
cli.Sexe,
cli.DateNaissance,
cli.Nature,
dd.DateComplete,
dd.Annee,
dd.MoisNom,
f.Balance,
f.NombreComptes NbCompte
FROM FactCompte f
JOIN DimCompte dc ON f.ID_Compte = dc.ID_Compte
JOIN DimTypeCompte dtc ON f.ID_TypeCompte = dtc.ID_TypeCompte
JOIN DimStatutCompte ds ON f.ID_Statut = ds.ID_Statut
JOIN DimSuccursale dsucc ON f.ID_Succ = dsucc.ID_Succ
JOIN DimZone dz ON f.ID_Zone = dz.ID_Zone
JOIN DimClient cli ON f.ID_Client = cli.ID_Client
JOIN DimDate dd ON f.ID_DateOpen = dd.ID_Date
"""
# Lire dans un DataFrame
df = pd.read_sql(requete, conn)
df.index.name = "Indice"
print("Données récupérées, ouverture dans Excel...")
# Affichage dans Excel via xlwings
app = xw.App(visible=True)
wb = app.books.add()
ws = wb.sheets[0]
# Ajout du DataFrame à la cellule "A3"
ws.range("A3").value = df
ws.autofit()
# Texte du titre
titre = "Rapport détaillé des données du Data WareHouse"
# Placer le titre en A1
ws.range("A1").value = titre
# Ajouter une etiquette
#ws.range("A3").value = Indice
# Fusionner les cellules de A1 à S1
ws.range("A1:S1").api.Merge()
# Centrer horizontalement et verticalement
ws.range("A1").api.HorizontalAlignment = -4108 # xlCenter
ws.range("A1").api.VerticalAlignment = -4108 # xlCenter
# Mettre en gras et augmenter la taille de police
ws.range("A1").api.Font.Bold = True
ws.range("A1").api.Font.Size = 14
# Couleur du texte : blanc
ws.range("A1").api.Font.Color = 0xFFFFFF # blanc (RGB hexadécimal)
# Couleur de fond : bleu foncé
ws.range("A1:S1").color = hex_to_excel_color("#36648B")
ws.range("A3:S3").color = hex_to_excel_color("#98F5FF")
# Hauteur de ligne
ws.range("1:1").row_height = 30
print("Données affichées dans Excel avec succès.")
except Exception as e:
print("Erreur :", str(e))
finally:
try:
conn.close()
except:
pass
generer_rapport_global_detaille()
Données récupérées, ouverture dans Excel... Données affichées dans Excel avec succès.

Répartition des comptes et du solde par succursale avec win32com.client
def rgb_to_excel_color(r, g, b):
"""
Convertit une couleur RGB (0-255) en code couleur utilisé par Excel VBA (BGR).
Excel utilise un long entier dans l’ordre BGR.
Exemple : rgb_to_excel_color(255, 0, 0) => 255 (bleu)
rgb_to_excel_color(0, 255, 0) => 65280 (vert)
rgb_to_excel_color(0, 0, 255) => 16711680 (rouge)
"""
return r + (g << 8) + (b << 16)
import pandas as pd
import pyodbc
import win32com.client as win32
# Appel de la fonction avant d'utiliser Excel
#fermer_excel()
# Connexion SQL Server
conn = pyodbc.connect(
'DRIVER={SQL Server};SERVER=DESKTOP-RUJ1AK0;DATABASE=BanqueDW;Trusted_Connection=yes'
)
# 2. Requête : par succursale
sql = """
SELECT s.NomSuccursale As Succursale,
SUM(f.NombreComptes) AS Nombre,
ROUND(SUM(f.Balance)/1000000,2) AS Balance
FROM FactCompte f
JOIN DimSuccursale s ON f.ID_Succ = s.ID_Succ
GROUP BY s.NomSuccursale
ORDER BY s.NomSuccursale
"""
df = pd.read_sql(sql, conn)
# Lancement Excel
excel = win32.gencache.EnsureDispatch('Excel.Application')
excel.Visible = True
wb = excel.Workbooks.Add()
ws = wb.Worksheets(1)
ws.Columns.AutoFit()
# Écriture des données dans Excel
start_row, start_col = 3, 4
for col_index, col_name in enumerate(df.columns):
ws.Cells(start_row, start_col + col_index).Value = col_name
for row_index, value in enumerate(df[col_name]):
ws.Cells(start_row + 1 + row_index, start_col + col_index).Value = value
# Dimensions du tableau
nb_lignes = len(df)
nb_colonnes = len(df.columns)
last_row = start_row + nb_lignes
last_col = start_col + nb_colonnes - 1
# Définir la plage du tableau complet (en-tête + données)
table_range = ws.Range(ws.Cells(start_row, start_col), ws.Cells(last_row, last_col))
# --- Formatage des bordures ---
borders = table_range.Borders
for i in range(1, 13): # xlEdgeLeft (1) à xlInsideHorizontal (12)
borders(i).LineStyle = 1 # xlContinuous
borders(i).Weight = 2 # xlThin
borders(i).Color = 0 # Noir
# Supprimer les bordures diagonales
borders(5).LineStyle = 0 # xlDiagonalDown
borders(6).LineStyle = 0 # xlDiagonalUp
# --- Police et fond général pour le tableau ---
table_range.Font.Name = "Calibri"
table_range.Font.Size = 11
table_range.Interior.Pattern = 1 # xlSolid
table_range.Interior.Color = 15790320 # Gris clair
# --- Formatage de l’en-tête ---
entete_range = ws.Range(ws.Cells(start_row, start_col), ws.Cells(start_row, last_col))
entete_range.Font.Name = "Calibri"
entete_range.Font.Size = 12
entete_range.Font.Bold = True
entete_range.Font.Color = 16777215 # Blanc
entete_range.Interior.Color = hex_to_excel_color("#98F5FF") # Bleu foncé (exemple : RGB(10,93,169))
entete_range.HorizontalAlignment = -4108 # xlCenter
entete_range.VerticalAlignment = -4108 # xlCenter
# --- Remplissage de l’en-tête (titres des colonnes) ---
for i, col in enumerate(df.columns):
cell = ws.Cells(start_row, start_col + i)
cell.Value = col
cell.HorizontalAlignment = -4108 # Centré
cell.VerticalAlignment = -4108
# --- Remplissage des données ---
for r in range(nb_lignes):
for c in range(nb_colonnes):
ws.Cells(start_row + 1 + r, start_col + c).Value = df.iat[r, c]
# --- Auto-ajustement des colonnes ---
ws.Range(ws.Cells(start_row, start_col), ws.Cells(last_row, last_col)).EntireColumn.AutoFit()
# 6. Position du 1er graphique (Nombre de comptes)
top_pos1 = ws.Cells(last_row + 2, 1).Top
left_pos1 = ws.Cells(last_row + 2, start_col).Left
chart1 = ws.Shapes.AddChart2(251, 5, 2, top_pos1, 400, 250).Chart # 5 = xlPie
data_range1 = ws.Range(
ws.Cells(start_row, start_col),
ws.Cells(last_row, start_col + 1) # NomSuccursale + NombreComptes
)
chart1.SetSourceData(Source=data_range1)
chart1.ApplyDataLabels() # Active les étiquettes
for series in chart1.SeriesCollection():
series.ApplyDataLabels()
series.DataLabels().ShowPercentage = True
series.DataLabels().ShowCategoryName = True
# Appliquer une couleur spécifique aux DataLabels (étiquettes) du Pie Chart
for point in chart1.SeriesCollection(1).Points():
point.DataLabel.Font.Color = 16777215
# Suppression des bordures pour chaque secteur
#for point in chart.SeriesCollection(1).Points():
point.Format.Line.Visible = False # Cache la bordure
# Appliquer la palette
for i, point in enumerate(series.Points()):
color_hex = blue_palette[i % len(blue_palette)]
point.Format.Fill.ForeColor.RGB = hex_to_excel_color(color_hex)
#Formatage du titre
chart1.HasTitle = True
chart1.ChartTitle.Text = "Répartition des comptes par Succursale"
font = chart1.ChartTitle.Format.TextFrame2.TextRange.Font
font.Name = "Segoe UI"
font.Size = 9
font.Bold = True
font.Fill.ForeColor.RGB = hex_to_excel_color("#1976D2")
# Centrage
chart1.ChartTitle.Format.TextFrame2.TextRange.ParagraphFormat.Alignment = 1
#===Graphique 2 =======
# 7. Position du 2e graphique (Nombre de Comptes etBalanceTotale )
top_pos2 = chart1.Parent.Top + chart1.Parent.Height + 20 # +20 pour un petit espace
left_pos2 = left_pos1
chart2 = ws.Shapes.AddChart2(251, 51, 2, top_pos2, 400, 250).Chart
data_range2 = ws.Range(
ws.Cells(start_row, start_col),
ws.Cells(last_row, start_col + 2) # NomSuccursale + BalanceTotale
)
chart2.SetSourceData(Source=data_range2)
chart2.Axes(1).HasTitle = True
chart2.Axes(1).AxisTitle.Text = "Succursale"
chart2.Axes(2).HasTitle = True
chart2.Axes(2).AxisTitle.Text = "Solde ($)"
# Formatage du itre du graphique
chart2.HasTitle = True
chart2.ChartTitle.Text = " Comptes et Solde total par succursale"
font = chart2.ChartTitle.Format.TextFrame2.TextRange.Font
font.Name = "Segoe UI"
font.Size = 9
font.Bold = True
font.Fill.ForeColor.RGB = hex_to_excel_color("#1976D2")
# Affichage des étiquettes de données (valeurs sur les barres)
for s in chart2.SeriesCollection():
s.ApplyDataLabels() # Ajoute les étiquettes de données
for lbl in s.DataLabels():
lbl.Position = 2 # Position 2 = outside end
# Supprimer l’axe vertical (valeurs $)
chart2.Axes(2).Delete()
# Supprimer les lignes de la grille principale
chart2.Axes(2).MajorGridlines.Format.Line.Visible = False
# Supprimer les étiquettes de l’axe horizontal (succursales) si tu veux :
# chart2.Axes(1).TickLabels.Delete()
# Facultatif : Supprimer les titres des axes
chart2.Axes(1).HasTitle = False
chart2.Axes(2).HasTitle = False
series = chart2.SeriesCollection(1) # la 1ère série
points_count = series.Points().Count
# Supposons que chart2 est ton graphique en barres
series = chart2.SeriesCollection(1) # 1re série (par exemple : Solde total)
for i, serie in enumerate(chart2.SeriesCollection()):
color_hex = blue_palette[i % len(blue_palette)]
serie.Format.Fill.ForeColor.RGB = hex_to_excel_color(color_hex)
#Formatage du titre
try:
title_range = ws.Range(ws.Cells(1, 1), ws.Cells(1, 10))
if title_range.Cells.Count > 1:
title_range.Merge()
title_range.Value = "Répartition des comptes et du solde par succursale"
title_range.Font.Name = "Calibri"
title_range.Font.Size = 16
title_range.Font.Bold = True
title_range.Font.Color = 16777215 # Blanc
title_range.Interior.Color = rgb_to_excel_color(0, 51, 102) # Bleu foncé
title_range.HorizontalAlignment = -4108 # xlCenter
title_range.VerticalAlignment = -4108
except Exception as e:
print(f"Erreur : {e}")
print("Rapports générés avec succès dans Excel.")
# Fermer la connexion
conn.close()
Rapports générés avec succès dans Excel.

Rapport filtré pour la succursale "CAY"


Exportation en PDF
L'exportaion d'un rapport au format PDF se fait de la manière suivante:
- Clique sur le bouton "Exporter en PDF"
- Choisir le rapport a exporter
- Clique "Open"

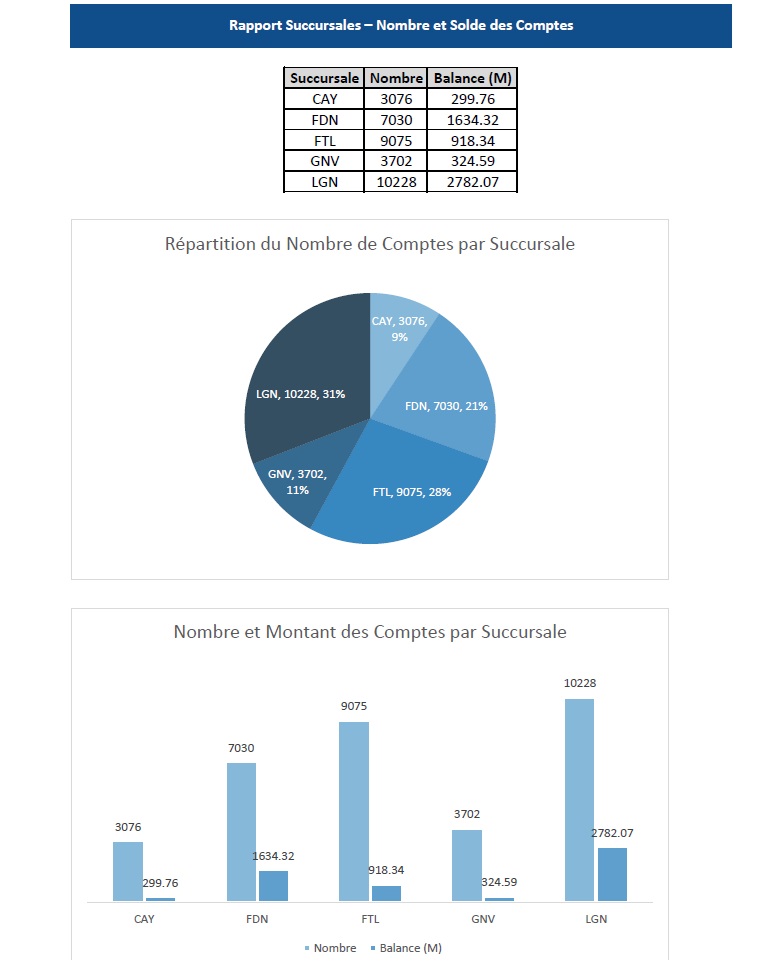
Transmission par e-mail
La transmission d'un rapport au format PDF par e-mail se fait de la manière suivante:
- Clique sur le bouton "Envoyer par Email"
- Le formulaire d'envoi d'un emaill avec pièces jointes s'affiche
- Saisir l'e-mail du destinataire, le sujet du message, le corps du message,
- Ajouter une ou plusieurs pièces jointe
- Choisir le servicr Gmail
- Clique "Envoyer"


Acces au message et affichage du rapport

